Hyper-Modular systems in banking (3 of ??) Data Mesh vs(or +) Data Fabric
(All opinions on my own)
Abstract: In a banking legacy system transformation, what is the best approach for the anaytical logic and data?. There are two key and hot trends in the market: Data Fabric and Data Mesh. Which fits better in a domain oriented modular transformation? Is it a “versus” or an “addition to”?
— — — — — — — — — — — — — — — — — — — — — — — — — — — — — — — — — — — — —
Domain Oriented design and Data Mesh
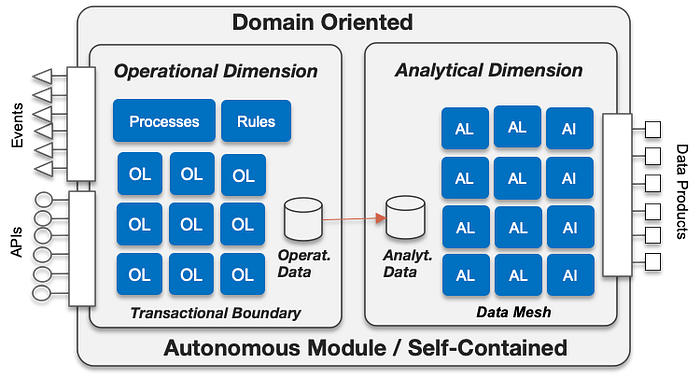
So far our approach to Hyper-Modular systems has been very “operational”, and not so focused on the “analytical” dimension of a bank information system. The conceptual view that we have used from the very beginning included the “analytics/AI processing” capabilities, but without a clear reference to the two types of data, operational and analytical, as it is shown in the next figure¹.

The “Domain-Oriented” approach is a key concept that we have been using from the very beginning in this hyper-modular architectural style but mainly on its operational dimension, not so much in the analytical one, even we had the intuition of doing something similar with analytical world: apply domain-oriented.
This intuition came to reality on something tangible when Zhamak Dehghani coined the Data Mesh term in her article “Data Mesh Principles and Logical Architecture”. As she proposes, the analytical data and logic is also domain-oriented, which fits extremely well on our view on how to transform legacy monolithic systems in banking using domain-oriented self-contained modules.
Data Mesh vs Data Fabric?
In addition to Data Mesh, the other hot topic in analytic architectures is Data Fabric, considered by many people as alternatives (so a “versus”), whilst others think that are different approaches to a similar problem.
It is not the intention of this post to explain in detail what Data Mesh and Data Fabric is (you can find a lot of information in the internet), but just to make easier to follow the rationale in the rest of this article, we are including a summary of those styles.
Data Mesh
This is a quite new approach (2019) defined by Zhamak Dehghani, in that moment at Thoughtworks.
Most of the information and images in this section are extracted from the aforementioned article “Data Mesh Principles and Logical Architecture”.
Basically, the Data Mesh approach tackles the problems of centralized analytical data solutions, like in the case of DWH and Data Lakes, proposing a Domain-Oriented approach where the analytical data space is split down in business Domains, allowing distributed governance. Data Mash is not just a technical approach as also considers the organizational and process challenges.

The Data Mesh model is based on four principles:
1. Domain-oriented decentralised data ownership and architecture
2. Data as a product
3. Self-serve data infrastructure as a platform
4. Federated computational governance
It is interesting notice the domain-oriented design, following the same principles than the operational models based on DDD.

Also interesting the Federated Governance principle, a balance between the data-domain data product owners governance autonomy and the need of set of global rules to ensure a healthy and interoperable ecosystem.

This Data Mesh Architecture site provides also an excellent technical and architectural view and the federated governance implementation. In the next figure the architecture:
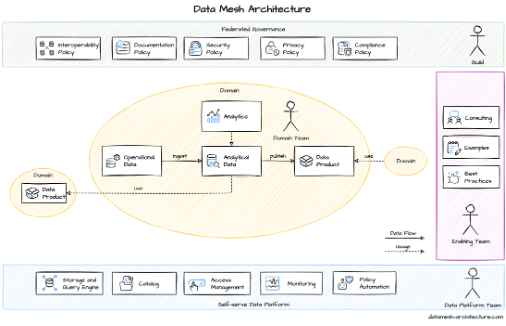
“Data Mesh Architecture. Data Mesh From an Engineering Perspective”. It is an excellent site with an architectural and engineering perspective of Data Mesh
Data Fabric
The Data Fabric approach is oriented to exploit and making data, stored in any legacy system, consumable by users and analytical processes, without moving the data with ETLs pipelines, but accessing them thru virtualization and federation techniques, supported in metadata and strong data governance.
Some definitions:
“Data Fabric is an all-in-one integrated architecture that connects data and analytical processes. It leverages existing metadata assets to support the design, deployment, and proper data utilization across all environments and platforms”²
“Data fabric is an architecture that facilitates the end-to-end integration of various data pipelines and cloud environments through the use of intelligent and automated systems”³
“Data Fabrics have six fundamental components:
- Data Management layer
- Data Ingestion Layer
- Data Processing
- Data Orchestration
- Data Discovery
- Data Access” ⁴
Finally, the next figure shows the IBM Data Fabric reference architecture, landing the above definitions and principles:
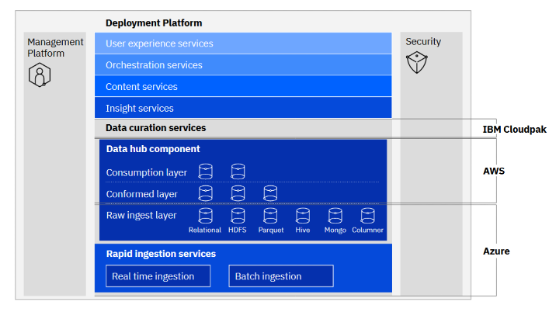
In summary:
- Data Mesh. Recent approach for splitting down the analytical data monolith, business domain with full autonomy and a federated governance for keeping interoperability.
- Data Fabric. Centralized view of the bank data assets, through virtualization and federation (no ETL), to be exposed and consumed by bank users and systems. Meta-data centric with a strong governance. Technical maturity.
Data Mesh and Data Fabric in core transformational projects
Our approach to core transformation projects is gradual, stepwise, where just part of the core it is transformed into a modular system following BIAN and DDD for decomposing the monolith.
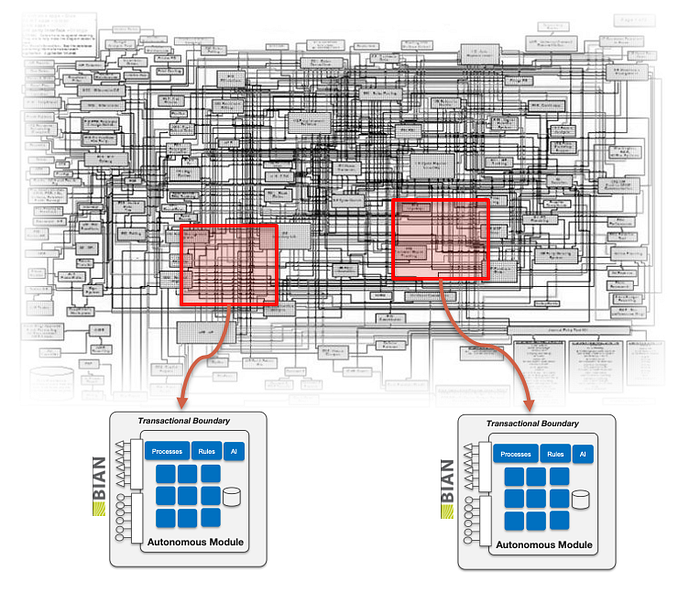
In this case the Data Mesh approach, domain centric and modular, fits extremely well in our hypèr-modular architectural model, also designed and built as modular self-contained systems. So Data Mesh should be the proper approach, using its federated governance model to manage interoperability.
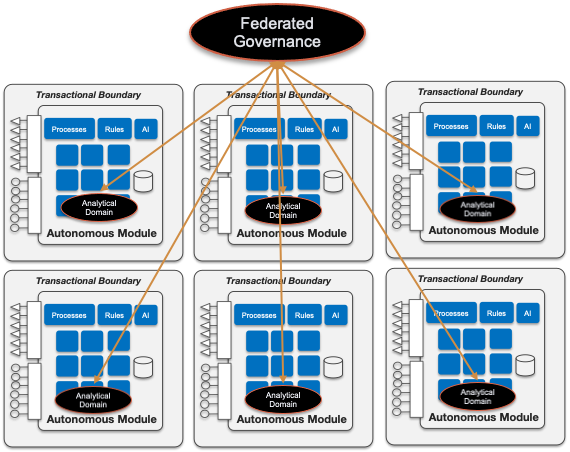
The Data Mesh style it is influencing our architectural model based on hyper-modular system, built out self-contained modules, where now the analytical data and processes is also confined in the model offering its own interface: the data product.
Anyway, the new banking system is still structurally hybrid, coexisting the new modular architecture with the legacy one, where the Data Fabric style can be used as the solution to expose, consume and govern that legacy data.
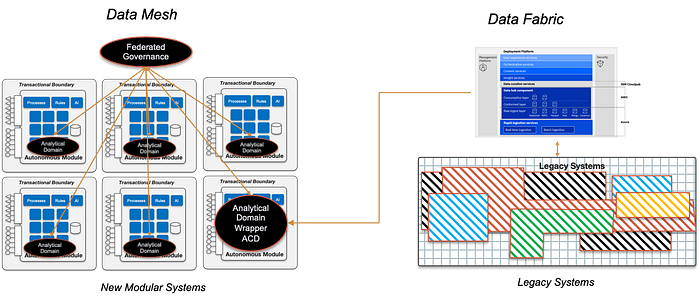
That coexistence, shown in the previous picture, it is not just about two analytical styles working separately. Both can be integrated under the Data Mesh umbrella with domains acting as a proxy or wrapper (Analytical Domain Wrapper) of legacy analytical data, a kind of anticorruption layer for data domains (anticorruption domain — ACD).
Finally, other option for the coexistence between both styles is that in which the Data Fabric acts as the technical infrastructure that supports the Data Mesh domains definition.
Conclusion
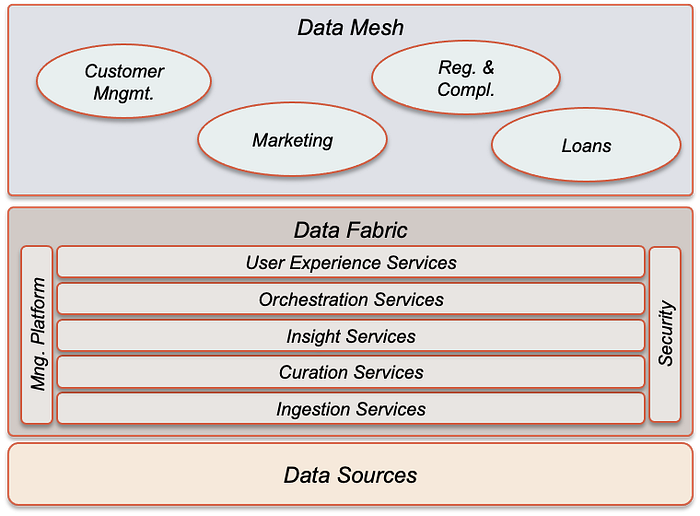
The two current data analytics styles, even considered in many cases as competitors, can play a joint role in the legacy core transformations, being the Data Mesh an excellent solution for the new modular systems and the Data Fabric the best to access and consume the legacy data, but also the underlaying technology that supports Data Mesh.
— — — — — — — — — — — — — — — — — — — — — — — — — — — — — — — — — — — — — Footnotes
[1]: See the first post in this series (hyper-modular systems in banking 1 of ??) for an explanation of this module view
[2]: Analytics India Magazine: https://analyticsindiamag.com/data-mesh-vs-data-fabric-whats-the-difference/
[3]: IBM: https://www.ibm.com/topics/data-fabric
[4]: Forrester referred by IBM: https://www.ibm.com/topics/data-fabric
