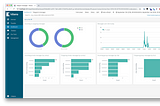
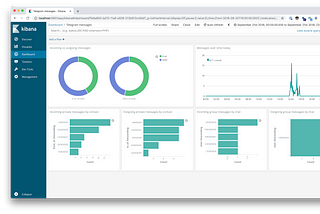
Jiayu YiTelegrammetry: Stats for TelegramGet insights into your Telegram activitySep 24, 2018Sep 24, 2018
Jiayu YiLife and death in black and whiteA primer on elementary cellular automataAug 21, 2018Aug 21, 2018
Jiayu YiA compact representation of the SUTD logoPlaying with PBM files and ImageMagickJun 17, 2018Jun 17, 2018
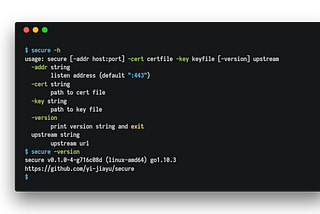
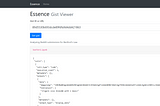
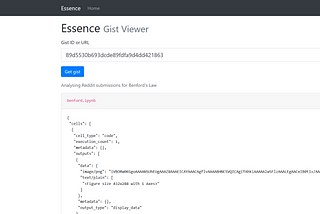
Jiayu YiAn alternative GitHub Gist viewerIn case your corporate proxy blocks gistsJun 12, 2018Jun 12, 2018
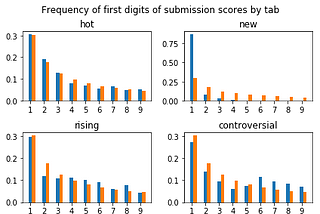
Jiayu YiBenford’s law and RedditApplying Benford’s law to submission scores and number of commentsMay 20, 2018May 20, 2018