From SAS Enterprise Miner to Python: A Tale of Auto Scorecards
Introduction
In the fast-evolving world of data science and machine learning, data practitioners seek a tool that enables efficient and automated model development. SAS Enterprise Miner has long been recognized as a powerful data mining and predictive modelling platform, providing data analysts and scientists with a comprehensive suite of tools to tackle complex business challenges. One of its prominent features is the Enterprise Miner, which automates the creation of predictive scorecards for credit risk, fraud detection, and other applications. However, as the Python ecosystem continues to grow in popularity, many data practitioners are exploring alternatives that harness the versatility and extensive libraries offered by Python.
In this blog post, we embark on a journey from SAS Enterprise Miner to Python, replicating the functionality of scorecards development using popular Python libraries and techniques. We will dive into the essential steps of creating automated scorecards in Python, showcasing its capabilities and comparing the process to SAS Enterprise Miner’s approach. By the end of this tutorial, you will gain valuable insights into harnessing Python’s potential for automated scorecard generation, empowering you to make informed decisions regarding your choice of tools for future data-driven projects.
If you want to jump to the code, see the GitHub repository.
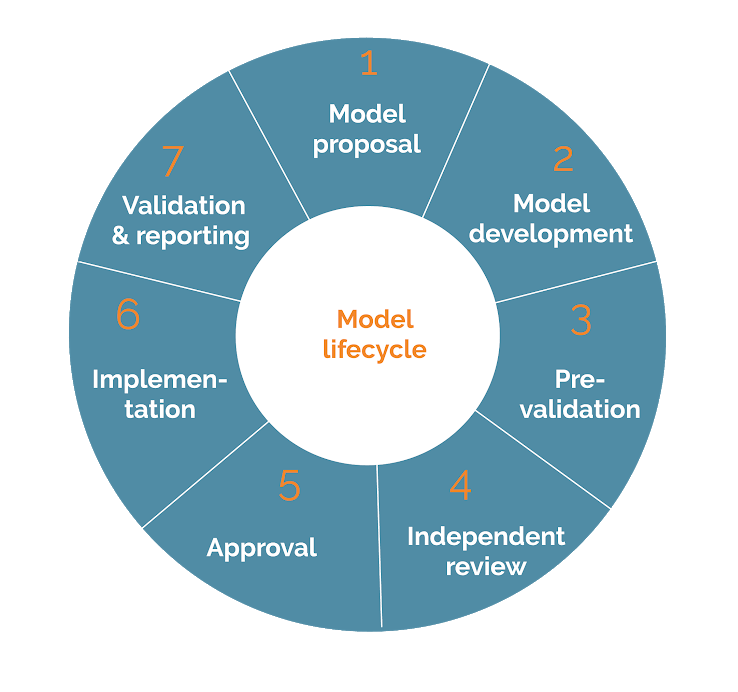
Model development typically follows a process like the one shown in the figure below. The details of each section are beyond what we are showcasing here. Therefore, we assume that the reader has experience building scorecards in SAS and would understand terms like the weight of evidence (WOE), informational value (IV), and other terms used in developing scorecards. In the process we will mention replication however, our aim is not to replicate everything verbatim but to show that the main steps can be achieved via open source. We would not discuss section 1 of the model development cycle.

Step 1: Understanding Auto Scorecards
Before we begin the modelling process, let’s understand what auto-scorecards are and why they are valuable in predictive modelling. In SAS Enterprise Miner, auto-scorecards allow users to quickly generate predictive models without delving into the intricate details of model construction. It automates the development of a scorecard, a crucial tool in risk assessment and decision-making for businesses and financial institutions. Scorecards assign scores to customers or entities based on various predictive features, facilitating quick evaluation and ranking of potential risks or opportunities.
Step 2: Setting Up the Python Environment
To replicate the functionality of auto-scorecards in Python, we need to set up a robust Python environment. We’ll utilize popular libraries such as NumPy, Pandas, and Scikit-learn to handle data manipulation, pre-processing, and modelling tasks. Additionally, we’ll explore specific libraries that cater to scorecard development, such as varclushi and Optbinning, to streamline the process further. By leveraging Python’s extensive ecosystem, we can achieve a flexible and efficient environment to match SAS Enterprise Miner’s capabilities. We acknowledge that here are other packages that we won’t dive into which includes Skorecard, scorecardpy, LightEBM.
The Python development environment setup is via pipenv. In the GitHub repository are Pipfile and Pipfile.lock, to create a virtual environment. The command is to achieve is
pipenv install --devThe — dev flag ensures all the packages necessary for the development environment are present. dev packages includes black, profiling packages etc.
Step 3: Data Preprocessing and Exploration
With the Python environment set up, it’s time to import our dataset and conduct the necessary data preprocessing steps. Exploring the data, handling missing values, and encoding categorical variables are vital in preparing the data for modelling. We’ll demonstrate how Python simplifies these tasks and ensures that the data is in a suitable format for creating predictive scorecards. Pandas profiling is a good package for this. We will skip this process here as there are many tutorials to profile data. Another reason is that our data of choice is the FICO dataset which has excellent data exploration available. One of the explorations we will use is the one on the Optbinning website, which illustrates explainable AI and the binning process.
Data separation is a critical component, where we randomly partition the data to ensure that we can evaluate the model’s performance on unseen data. The Scikit-learn function train_test_split divides a dataset into two sets: training and testing sets. The training set trains the machine learning model, containing input features and their corresponding target labels, allowing it to learn patterns and relationships in the data. The testing set evaluates the model’s performance, comprising input features without their related target labels. Instead, the model makes predictions on this set, comparing them with the actual target labels to assess the model’s accuracy and generalization ability.
By using separate training and testing sets, train_test_split helps to avoid over-fitting. Over-fitting occurs when a model performs well on the training data but poorly on unseen data, indicating that it has memorized the training set rather than learning the underlying patterns.
The testing set allows us to estimate how well the model will perform on new, unseen data. This evaluation helps select the best model, tuning hyper-parameters, and making informed decisions about its deployment and usage in real-world scenarios. In credit risk, we need out-of-time data; however, we don’t have a time dimension in the dataset. We can then run an auto pipeline with the exploration and understanding of the data, its missing values for each column, its particular importance, and whether the feature is positively correlated or negatively correlated with the target. The auto pipeline is structured as follows.
Step 4: Automatic Scorecard Pipeline
This step contains working code and was used as a final pipeline to build a risk-scoring model. There are two significant stages here: The data reduction stage and the scorecard stage. The data reduction aims to narrow down to about 7 to 12 features for the model. The scorecard stage uses these features to build the best possible scorecard. The general pipeline looks like the figure below, however, some of the components would be missing in this automated version. The full version will be out later.

Stage 1: Feature Reduction
Preprocessing: This step involves a few processes. It holds data transformation and dimensionality reduction to improve the efficiency of the learning process. In the feature reduction part, we aim to remove the feature with negligible variation using VarianceThreshold. Variance threshold is a feature reduction method in machine learning that eliminates features (columns) with low variance. Data practitioners commonly use VarianceThreshold to eliminate data points that display little or no variation across the dataset. Such features may contribute little to the learning process and even introduce noise to the model. The basic concept underlying VarianceThreshold is that if a feature has extremely low variance, it indicates that most of its values are similar or identical. Consequently, distinguishing between different instances in the dataset becomes less informative and less valuable. On the contrary, features with higher variance exhibit more diverse patterns and contain more relevant information for the learning algorithm.
In the second part of feature reduction, we preprocess the data, including transforming every feature to ordinal data using weight-of-evidence (WOE). The package of choice is OptBinning. OptBinning is a powerful Python library that provides advanced binning techniques for data preprocessing and feature engineering. One of its key components is the BinningProcess module, which offers a wide range of binning algorithms, including optimal binning methods such as Recursive Partitioning and Dynamic Programming. With OptBinning’s BinningProcess, you can efficiently transform continuous variables into categorical bins, improving your models’ interpretability and predictive power. You can handle data preprocessing challenges, such as reducing noise, taking care of outliers, and capturing non-linear relationships, ultimately enhancing the accuracy and interpretability of your models.
Clustering: This is a feature reduction stage. The features are clustered together based on their correlation. The output is a list of automatically selected features. The feature with the highest informational value (IV) and the one at the cluster’s centre is preferred. The package of choice is Varclushi. Varclushi is a Python package designed for feature selection and dimensionality reduction. It implements a variant of the clustering-based feature selection method called variance component analysis. With Varclushi, you can identify and eliminate redundant or irrelevant features from your dataset, leading to more efficient and interpretable models. By leveraging clustering and statistical techniques, Varclushi helps uncover the most informative features and improve overall model performance.
Feature selection: In the feature selection stage, we additionally select a smaller number of features to provide a parsimonious model. The module of choice is Scikit-learn RFECV (Recursive Feature Elimination with Cross-Validation). RFECV is a feature selection technique in scikit-learn that recursively eliminates less important features by repeatedly training models and selecting the optimal subset of parts based on cross-validation performance. RFECV helps improve model interpretability, reduce over-fitting, and enhance prediction accuracy by automatically selecting the most relevant features for the task.
Stage 2: Model
The model stage involves building a scorecard with the final features from the data reduction stage. The scorecard is a classification model converted into a score from a range of output scores. The OptBinning library’s Scorecard module combines binning and logistic regression, enabling the development of scorecards for credit risk modelling and scoring applications. The first part is a BinningProcess is employed in this approach to enhance the modelling process further.
The second part is the linear algorithm which we use scikit-learn LogisticRegression. In scikit-learn, LogisticRegression is a widely used classification algorithm for binary and multi-class classification problems. It fits a logistic regression model to the training data and predicts the probability of class membership for new observations. Logistic regression is famous for its simplicity, interpretability, and effectiveness across various domains. It proves particularly useful in binary classification tasks, where the objective is to predict the probability of an instance belonging to a specific class.
The third element of the Scorecard is the scoring part. This step converts the logistic regression probabilities into points based on the criterion specified. In this part, Naeem Siddiqi’s Credit Risk Scorecards book explains converting probabilities into scores. Optbinning provide this out of the box.
The Code!
The final part of the article is the code located in the AutoScorard folder of this GitHub Repo. We made the entry point to be a simple script which contains almost nothing but the __main__ of python script.
if __name__ == "__main__":
model, model_table, dim_reduction = scorecard.main(data_path="data", binning_fit_params=binning_fit_params)
model_table.to_csv("auto-scorecard-model.csv")
model.save("model.pkl")
print(model_table)
print("Features out", dim_reduction["features"].n_features_)The major components of the imported scorecard script are the variable_reduction_pipeline function which is made primarily of various scikit-learn transformers. These transformers are already explained above.
def variable_reduction_pipeline(
categorical_features: list[str],
binning_features: list[str],
binning_fit_params=None,
) -> Pipeline:
"""Create a scikit-learn pipeline for feature reduction using clustering.
Args:
categorical_features (list[str]): List of names of categorical features.
binning_features (list[str]): List of names of features to apply binning.
binning_fit_params (dict, optional): Fit parameters for binning process. Defaults to None.
Returns:
Pipeline: A scikit-learn pipeline for feature reduction.
"""
binning_process = BinningProcess(
categorical_variables=categorical_features,
variable_names=binning_features,
binning_fit_params=binning_fit_params,
min_prebin_size=10e-5, # The prebin size to make the feature set usable
special_codes=SPECIAL_CODES,
selection_criteria={"iv": {"min": 0.1}}
)
variance_reductor = VarianceThreshold().set_output(transform="pandas")
clustering_process = Cluster(max_eigen=MAX_EIGEN)
feature_selection = RFECV(
LogisticRegression(max_iter=1000),
cv=5,
scoring="roc_auc",
n_jobs=-1,
)
return Pipeline(
[
('variance', variance_reductor),
('binning', binning_process),
('cluster', clustering_process),
('features', feature_selection),
]
)The model_pipeline function takes the transformer and access the binning object and use it in the Scorecard object from Optbinning.
The model_pipeline function
def model_pipeline(features, categorical_features, binning_fit_params=None):
"""
Creates a pipeline for building a Scorecard model using the provided features and categorical features.
Args:
features (list): List of feature names.
categorical_features (list): List of categorical feature names.
binning_fit_params (dict, optional): Parameters for the binning process. Defaults to None.
Returns:
Scorecard: A Scorecard model pipeline.
"""
binning_process = BinningProcess(
categorical_variables=categorical_features,
variable_names=features,
binning_fit_params=binning_fit_params,
min_prebin_size=10e-5,
special_codes=SPECIAL_CODES,
selection_criteria={"iv":{"min": 0.1}}
)
scaling_method: str = "pdo_odds"
scaling_method_data = {
"pdo": 30,
"odds": 20,
"scorecard_points": 750,
}
return Scorecard(
binning_process=binning_process,
estimator=LogisticRegression(),
scaling_method=scaling_method,
scaling_method_params=scaling_method_data,
intercept_based=True,
reverse_scorecard=False,
rounding=True,
)Explanation
model_pipeline creates a pipeline for building a Scorecard model using the specified features and categorical features. The function takes three arguments:
1. features: A list of feature names to be used in the model.
2. categorical_features: A list of categorical feature names.
3. binning_fit_params (optional): Parameters for the binning process. Default is set to None.
Inside the function, a BinningProcess object is created to handle the feature binning. It specifies the categorical variables, variable names, and binning fit parameters, among other options. The pipeline applies selection criteria, where features with Information Value (IV) less than 0.1 are discarded.
Next, the function sets the scaling method to pdo_odds and defines scaling method data with values for pdo, odds, and scorecard_points.
Finally, a Scorecard model is returned, which uses the previously defined binning process, a Logistic Regression estimator, and additional scaling and rounding options to create the final Scorecard model pipeline.
The remaining two functions are helpers to access categorical columns and save artifacts respectively.
Conclusion
In the journey from SAS Enterprise Miner to Python for building Auto Scorecards, both platforms prove to be capable options. However, Python’s unmatched community support stands out as a significant advantage. Migrating to Python opens up a world of benefits, including cost savings by eliminating the need for SAS licenses. Moreover, Python’s flexibility allows scorecard pipelines to be easily modified as packages evolve, ensuring adaptability and future-proofing for data science projects. By embracing Python, data practitioners can tap into a thriving community, enhanced tools, and greater cost-effectiveness, making it a compelling choice for Auto Scorecard development and beyond.

{kind=link}