Demystifying Large Language Models: A Beginner’s Guide to Understanding AI Text Generation
Demystifying Large Language Models: A Beginner’s Guide to Understanding AI Text Generation
Unlock the Secrets of Large Language Models and Learn About AI Text Generation in Simple Terms
Welcome to the world of AI, where Large Language Models (LLMs) hold incredible potential for text generation!
If you’re curious about how these language models work, you’ve come to the right place. In this beginner’s guide, we’ll dive into the fascinating realm of LLMs, breaking down their magic and revealing the art of AI-generated text.
Before we embark on this journey, don’t forget to check out my Twitter, where I discuss various AI topics, including working with LLMs and more.
Demystifying AI: An Exploration of Large Language Models
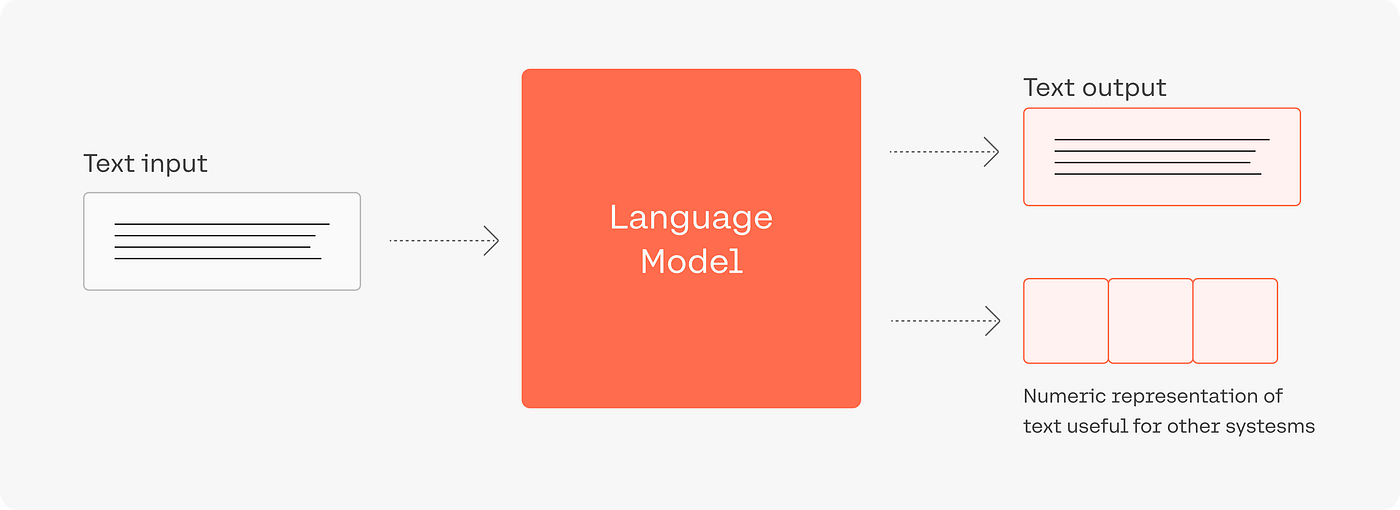
Large Language Models have become a hot topic in the AI community, revolutionizing natural language processing and powering impressive applications like ChatGPT, GPT-3, and more. These models are built on a special type of machine-learning architecture known as the Transformer, and they have the ability to generate human-like text that seems almost too good to be true.
In this series, ‘Demystifying AI,’ we aim to make complex AI concepts accessible to everyone, especially beginners. Whether you’re a seasoned developer or someone new to the world of AI, we’ll guide you through the inner workings of LLMs step by step.
- Tokenization: Breaking Down Text into Tokens

Tokenization serves as the foundation of LLMs’ text-processing capabilities. It involves breaking down input text into smaller pieces called tokens. Instead of working with full words, tokens can be as small as a single character or as large as a complete word. The advantage of using tokens is twofold: it forms a manageable vocabulary, reducing the complexity of the model, and it enables efficient processing of the input text.
2. Embedding: Mapping Tokens to Rich Semantic Vectors

Once tokenized, LLMs map each token to a high-dimensional vector known as an embedding. These embeddings, often referred to as word embeddings, encode the semantic meaning of the tokens. Each token is transformed into a numerical representation that captures its essence and context within the entire language. Word embeddings are learned during the model’s training process, optimizing them to retain useful information about the tokens’ relationships and semantic nuances.
3. Contextual Understanding: Unleashing the Power of Transformers

What sets LLMs apart is their contextual understanding of text. Unlike traditional n-gram models that lack context, LLMs leverage the Transformer architecture to consider not just the individual token but also its surrounding tokens.
This contextual understanding is achieved through self-attention mechanisms, which allow the model to attend to different parts of the input text when processing each token. By grasping contextual dependencies, LLMs can generate coherent and contextually relevant responses.
4. Prediction: From Probability Distributions to Fluent Text

Once the LLM has comprehended the context, the next step is prediction. Drawing on patterns learned during training, the model generates a probability distribution over all words or tokens in its vocabulary. The token with the highest probability is selected as the next word. This process repeats iteratively, generating longer sequences of text that form coherent paragraphs or conversations. The model’s training data imbues it with knowledge of language patterns, grammar, and syntax.
5. Decoding: Translating Numerical Representations into Human Language
The predicted tokens, existing as numerical representations, are decoded back into human-readable text using reverse mapping. The decoding process converts the embeddings into recognizable language, creating text that appears human-like and contextually appropriate.
Understanding the Limitations:
Despite their impressive capabilities, it’s essential to recognize the limitations of LLMs. While they generate text that sounds coherent, LLMs do not possess a genuine understanding of the meaning they convey.
They rely on statistical patterns present in the data they were trained on, rather than true comprehension. This limitation highlights the distinction between AI-generated text and human language understanding.
Conclusion:
Large Language Models, built on the foundation of tokenization, embedding, contextual understanding, prediction, and decoding, have ushered in a new era of natural language processing and understanding. The innovative Transformer architecture enables these models to consider contextual dependencies and generate human-like text, transforming the field of AI-driven language generation.
As we continue to explore the capabilities of LLMs and refine their methodologies, we gain valuable insights into the interplay between artificial intelligence and human language, advancing the fascinating frontier of AI research.
Want to develop your own applications with Large Language Models?
Check out my tutorial on building your own Smart Study Buddy with OpenAI, LangChain and Streamlit:
A Step-by-Step Guide to Creating a Smart Study Buddy using OpenAI, LangChain, and Streamlit
Don’t forget to check out my Twitter, where I discuss various AI topics, including working with LLMs and more.
See you next time!
