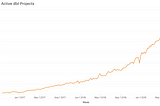
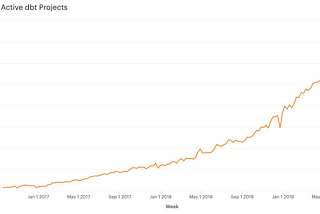
Tristan HandyinFishtown AnalyticsThree Years In: Things Are Heating UpYear 3 for dbt community has been intense, and things are only going to accelerate from here.Jul 2, 20192Jul 2, 20192
Tristan HandyinFishtown AnalyticsA Wave of Acquisitions in Business IntelligenceHoly crap! Within the past week we’ve seen the acquisitions of the two biggest players in the modern BI landscape, Looker and Tableau.Jun 10, 20198Jun 10, 20198
Tristan HandyinFishtown AnalyticsHow to Unnest Arrays in RedshiftUnnesting arrays on Redshift is a pain, but it’s doable. This post walks through the entire process, start to finish.May 14, 2019May 14, 2019
Tristan HandyinFishtown AnalyticsPricing-Vision FitYou’ve heard of Product-Market Fit. PMF has become common parlance within startup culture. It has even spawned similar terms, my favorite…May 4, 2019May 4, 2019
Tristan HandyinFishtown AnalyticsWhat’s in a name?Sinter just became dbt Cloud. Why the re-brand?Jan 16, 20192Jan 16, 20192
Tristan HandyinFishtown AnalyticsDoes my Startup Data Team Need a Data Engineer?The role of the data engineer in a startup data team is changing rapidly. Are you thinking about it the right way?Jan 3, 201917Jan 3, 201917
Tristan HandyinFishtown AnalyticsScaling KnowledgeThe hardest thing about scaling a company is communication.Sep 6, 20181Sep 6, 20181
Tristan HandyinFishtown AnalyticsTwo Years In And It’s Just Getting GoodThis week marks the second anniversary of Fishtown Analytics. A year ago, I wrote One Year In: We’re Still in Business. I had pretty…Jul 6, 20181Jul 6, 20181
Tristan HandyHow Compatible are Redshift and Snowflake’s SQL Syntaxes?I just went through the process of converting 25,000 lines of SQL from Redshift to Snowflake. Here are my notes.Jun 13, 20189Jun 13, 20189
Tristan HandyinFishtown AnalyticsHow to Safely Convert Strings to Integers in RedshiftThis is a very stupid problem. I am not writing this post because it’s a fascinating topic—rather, I’m writing it in the hopes that you…Mar 16, 20181Mar 16, 20181