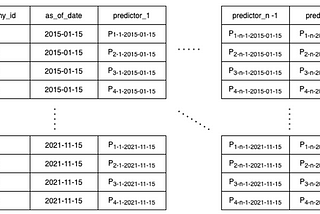
juanjolainezinCreditorWatchHow we built a master dataset to transform 700B data points in an economic indexThis article is a series of 4 in which we’ll cover end to end how we transformed 700 Billion data points into an index to track credit risk…Feb 19, 2022Feb 19, 2022
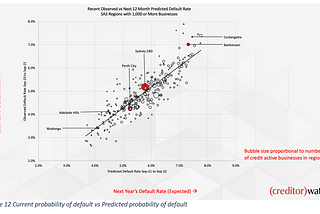
juanjolainezinCreditorWatchHow to visualize and serve a multi-billion datapoints economic indexHow do you deliver the index?Dec 22, 2021Dec 22, 2021
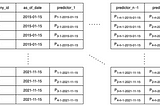
juanjolainezinCreditorWatchHow did we build a model from 700B datapoints to create an economic indexThis is the 3rd part of a 4 part journey on how we build an economic index to track Australia’s credit risk. In case you missed them…Dec 15, 2021Dec 15, 2021
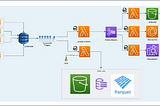
juanjolainezinCreditorWatchHow we built a multi-billion datapoints dataset to create a predictive risk indexCreating the big-data datasetsNov 16, 2021Nov 16, 2021
juanjolainezinCreditorWatchMulti-clustered architectures to scale big data systemsIn CreditorWatch, we use Hadoop clusters in combination with Spark and R to produce hundreds of billions of data points every month.Jul 11, 2021Jul 11, 2021
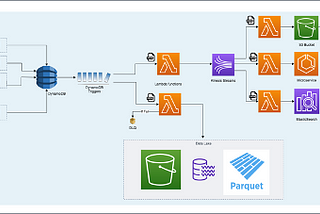
juanjolainezinCreditorWatchMicroprocesses: a new architectural design pattern for background jobs on a microservice…Background processes are the biggest forgotten element when implementing microservices and needed in the vast majority of applications.May 9, 20216May 9, 20216
juanjolainezinCreditorWatchAWS Lambda facts you wish to know before processing 2 billion lambda executions — 2021After having executed 2 billion lambdas we are happy to share recommendation on best practices and limitations on AWS Lambdas.Apr 20, 20216Apr 20, 20216
juanjolainezinCreditorWatchHow to successfully create a push queue using SQS + lambdaAmazon SQS and Lambda integration to create push queues, process your messages, and trigger endpoints on your microservices.Apr 6, 2021Apr 6, 2021