Simple Review: High-Resolution Image Synthesis with Latent Diffusion Models
Most images in this post are from the High-Resolution Image Synthesis with Latent Diffusion Models paper.




There are four main steps (texts from the [2]):
- The first step is to extract a more compact representation of the image using the encoder E located in the upper left corner of the figure above. Unlike other methods, latent diffusion works in the latent space defined by the encoder rather than in pixel space.
- Next, Gaussian noise is added to the image in the upper middle part of the figure as part of the diffusion process that goes from z to zT (in case T steps of noise addition are applied).
- The zT representation is then passed through a U-Net located in the middle part at the bottom of the figure. The U-Net has the role of predicting zT-1, and this process is repeated T-1 times until we arrive at z, which is then returned from latent space to pixel space via the decoder D.
- Finally, the approach allows for arbitrary conditioning by mapping various input modalities such as semantic maps or text. This is achieved by first transforming the input y with a dedicated encoder τθ and then mapping it to the intermediate layers of the U-Net with the same cross-attention layer used by the Transformer architecture.



========================================================
To compress the image as the latent vector z, they used VQGAN.
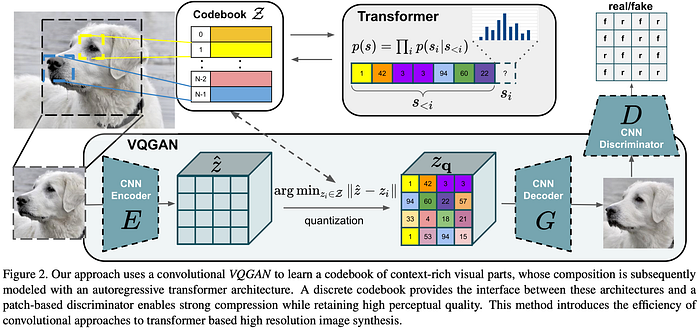
Here is how to use latent vector (code book) in VQGAN:

========================================================

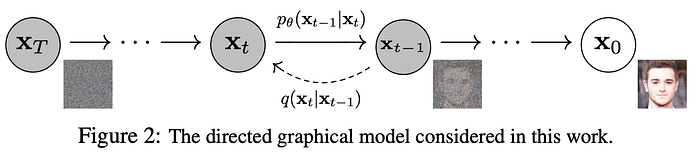
Diffusion model: denoise (or noise) model from x(or x_t) to x_t(or x)


Instead of using all image information, they used latent information. And they used UNet as their diffusion model.


Inside their denoising process, they added conditioning information using cross-attention layers. This conditional information y is encoded by \lambda_\theta. The y can contain semantic maps, text, representations, and images. Each step t, encoded information is adjusted as shown in Equation (3).
========================================================
Diffusion Model [5]:


========================================================




This post is to summarize this paper for me to understand.
If there is something wrong with this post, please let me know and explain that.
References:
[1]
[2]
[3]
[4]
[5]
