StarRocks millisecond-level point queries on hundreds of billions of data
Supporting point queries with arbitrary field filtering is a common requirement for TP databases, and a common solution is the use of secondary indexes. In recent user scenario tests, we found that StarRocks, in a cluster consisting of 3 servers with 8-core CPUs, 32GB of memory, and 4TB AWS EBS disks, can provide sub-millisecond performance for hot queries on hundreds of billions of data and around 1-second performance for cold queries.
This article briefly analyzes how StarRocks achieves millisecond-level query of tens of billions of data. The main method of StarRocks to accelerate the query of prefix columns is the prefix index, and the main method of accelerating the query of the following non-primary key columns is Bitmap index:
select * from table where A = 1
select * from table where A = 1 and B = 2
select * from table where A = 1 or B = 21 How does StarRocks Bitmap index speed up point queries
1.1 StarRocks supports indexed Bitmap indexes
StarRocks Segment File
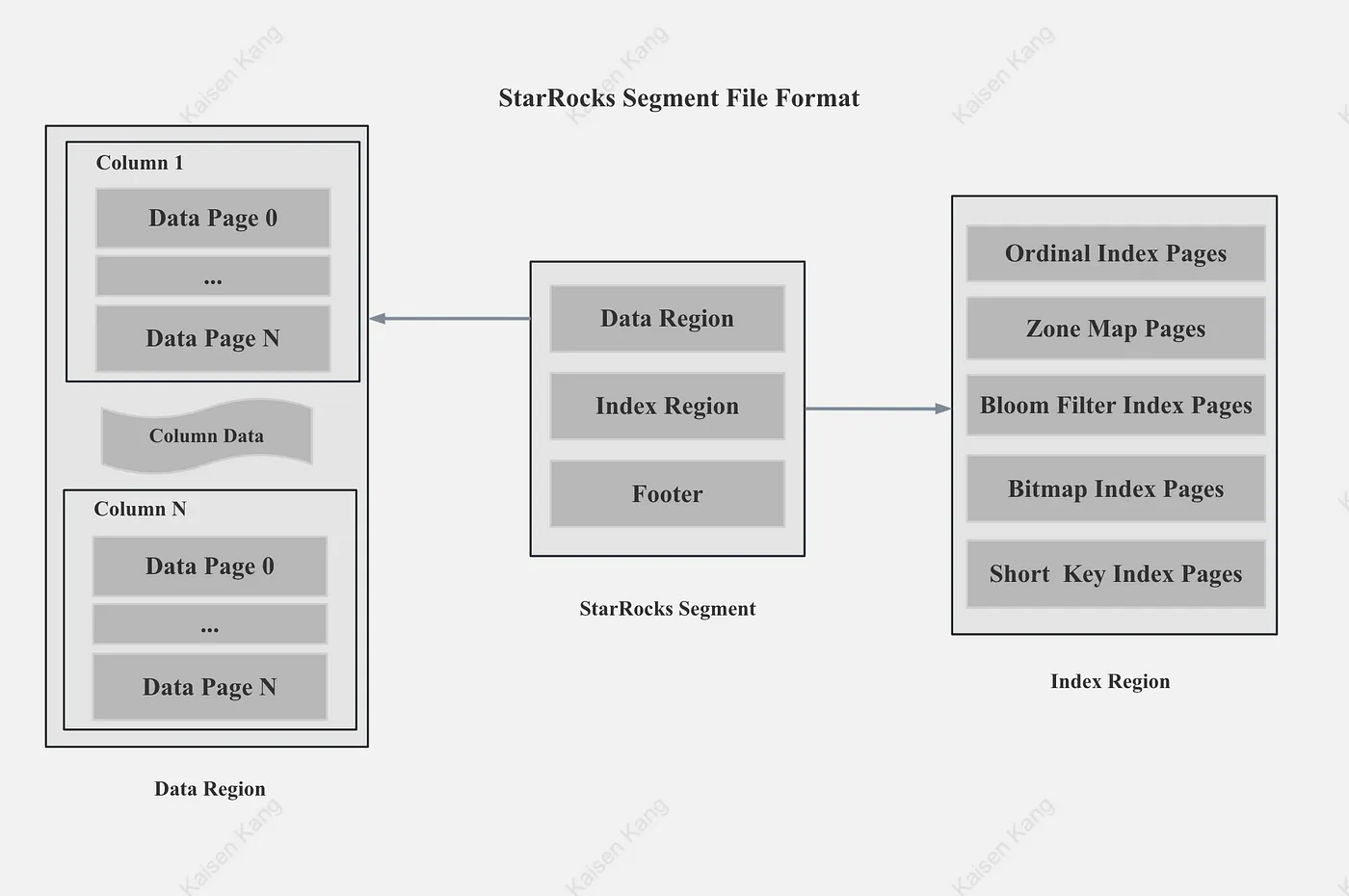
The segment file of StarRocks is divided into three parts: data, index, and metadata. Data and index are organized according to Page, and the default size of a Page is 1M.
StarRocks Bitmap Index Rationale

The Bitmap Index of StarRocks mainly includes two parts: the dictionary and the Bitmap index itself. The dictionary saves the mapping from the original value to the encoding Id, and the Bitmap index records the mapping from each encoding ID to the Bitmap.
StarRocks Bitmap Index Storage Format

As shown in the figure above, both the dictionary part and the Bitmap index part of StarRocks are stored in the format of Page. In order to reduce memory usage and speed up indexing, StarRocks indexes both the dictionary and Bitmap Page.
Of course, if the cardinality of the Bitmap index column is very low and there is only one Dict Data Page and Bitmap Data Page, we don’t need Dict Index Page and Bitmap Index Page.
1.2 Operation On Encode Data
When StarRocks uses Bitmap Index for filtering, it only needs to load the Dict Index Page and some Dict Data Pages first, and quickly filter according to the dictionary values, without decoding data, and without loading all Bitmap Data Pages at once.
To sum up, since StarRocks supports Bitmap index indexing and supports quick filtering according to dictionary values, even if the cardinality of the Bitmap Index column is high, the overall disk storage of the Bitmap Index is large, the memory usage is still small.
1.3 Or predicate supports Bitmap index
Due to historical reasons, the predicate pushdown of the StarRocks storage layer only supports the CNF conjunctive paradigm, which requires the predicate to be connected by And. For example for the following SQL:
select * from table where A = 1 and B = 2StarRocks will push down the predicates A = 1 and B = 2 respectively, and the final result is the filtered intersection of the two predicates. A = 1 and B = 2 can use various indexes on column A and column B respectively.
But for the following Or predicate:
select * from table where A = 1 or B = 2The old version of the StarRocks storage layer cannot push down the OR predicate, so it needs to scan the entire table and then use the A = 1 or B =2 predicate to filter data. In order for the Or predicate to use the Bitmap index, the most ideal way is that the storage layer supports the Or predicate. A = 1 and B = 2 respectively apply the Bitmap index, and then the row numbers can be union, but the code modification is a little complicated, so it is implemented two steps, the first step is to rewrite SQL on the FE side so that the OR predicate can use the Bitmap index, and then the second step will directly support the OR predicate in the storage layer.
The SQL rewrite is as follows:

1.4 Bitmap index memory cache

StarRocks will ensure that all Dict Index Pages and Bitmap Index Pages must be in memory, and keep as many Dict Data Pages and Bitmap Data Pages in memory as possible, and ensure that the Page Cache related to Bitmap Index is not flushed by Column data.
In this way, in the case of a small query result set, even if it is the first Cold Query, StarRocks can achieve only one Disk Seek.
1.5 Adaptive Bitmap Indexing
When StarRocks found that the selectivity of the Bitmap index was not high and needed to seek a lot of data pages, we would give up using the Bitmap index and directly scan in order.
2 StarRocks prefix index speeds up point queries

As shown in the figure above, if the cardinality of a table’s filter condition is very high, in StarRocks, there is no need to use the Bitmap index, set the column as the Sort Key, and use the prefix index to filter. For high-cardinality columns, the prefix index has better point lookup performance and can save a lot of storage space.
3 StarRocks RollUp || Materialized View speeds up point queries
When the filtering degree of the Bitmap index is not large and many data pages need to be Seek, you can consider further exchanging space for time, using RollUp and Materialized View of StarRocks to set different filter columns as Sort Key, and using the prefix index to speed up point queries.
4 StarRocks Generated Column speeds up point queries

As shown in the figure above, when the filtered column is a Key column of type Json or Map, in StarRocks, we can add a Generated Column for the Key column, and then create a Bitmap index for the Key column to speed up the point queries through the Bitmap index.
Of course, when StarRocks supports the direct build the Bitmap indexes for Json or Map type Key columns, there is no need to rely on Generated Column.
5 StarRocks Two-Level Partition & Bucket

StarRocks supports two-level partitioning and bucketing. You can first partition according to columns with time attributes, and then partition according to high-cardinality columns. This ensures good data locality and avoids data skew.
- The better the data locality, the better the data compression ratio in the columnar storage, and the lower the IO cost of the query.
- Without data skew, StarRocks can give full play to the capabilities of multi-machine and multi-core.
5.1 StarRocks Partition Pruning
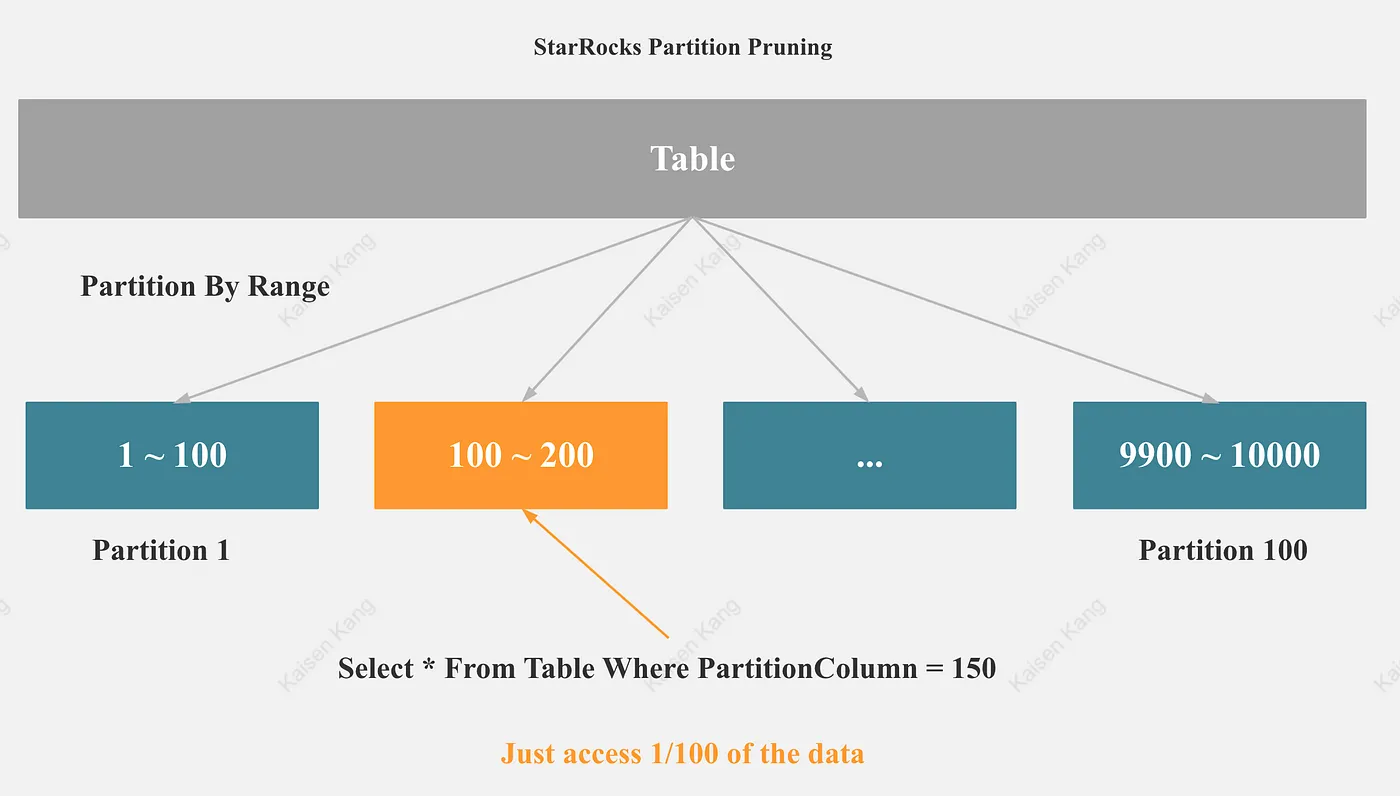
As shown in the figure, if the filter condition of the query contains partition columns, StarRocks can trigger partition pruning, and the amount of Scan data will be greatly reduced.
5.2 StarRocks Bucket Pruning
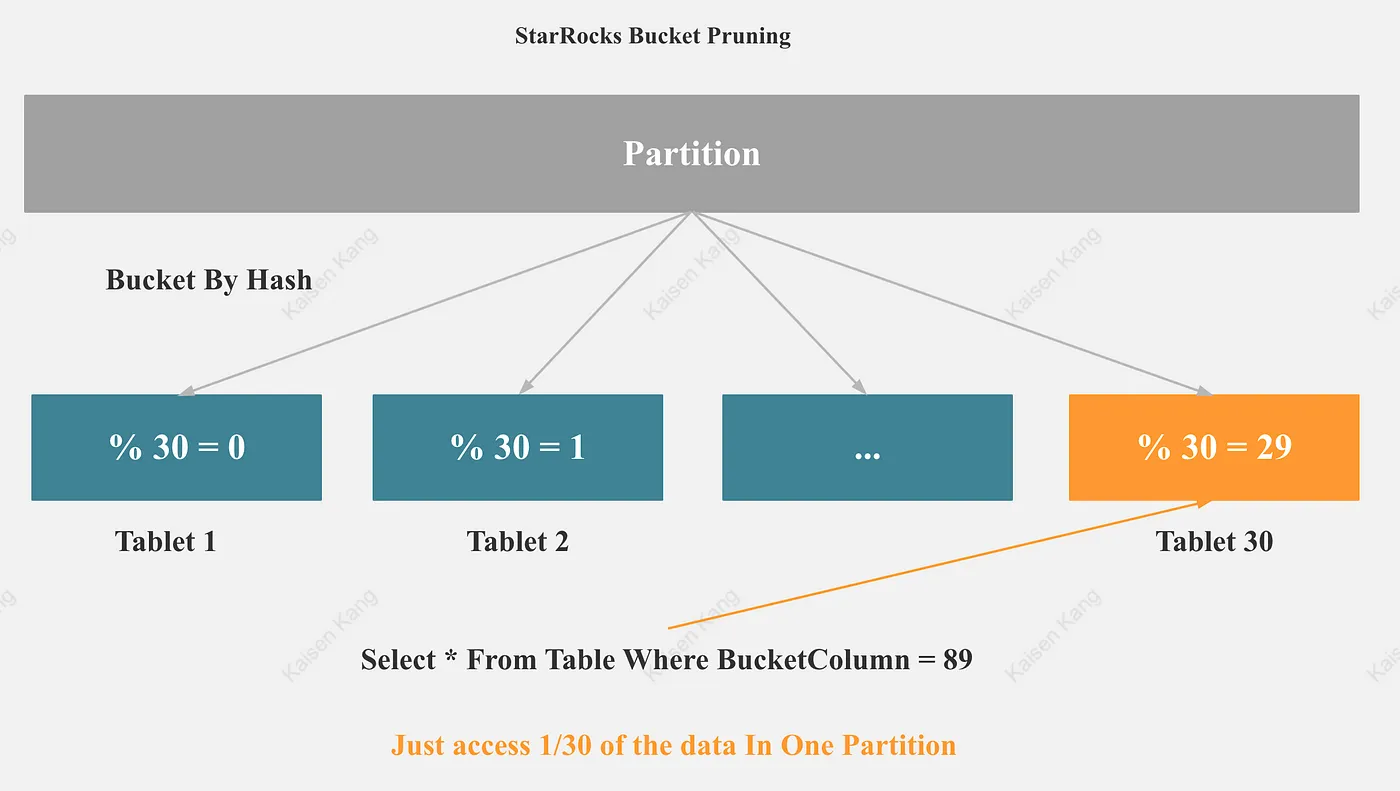
As shown in the figure, if the filter condition of the query contains bucket columns, StarRocks can trigger bucket pruning, and the amount of Scan data will be greatly reduced.
6 Conclusion


When you need high-performance point query, high-performance OLAP query, high-performance AdHoc query and high-performance data lake analysis at the same time, StarRocks is your best choice.
