Karthik KumarWhy I joined Georgia Tech’s OMSCS programIn about two months from now, I will graduate from Georgia Tech’s OMSCS program. This post talks about my journey to get this point.Mar 3, 2019Mar 3, 2019
Karthik KumarScala: The Good PartsI recently finished the Functional Programming Principles in Scala course on Coursera. Having primarily programmed in an imperative…Oct 24, 2015Oct 24, 2015
Karthik KumarDesign Patterns in Real LifeI recently finished reading the popular Design Patterns book. As I was reading, I noticed that many of the examples used in the book were…Dec 5, 2014Dec 5, 2014
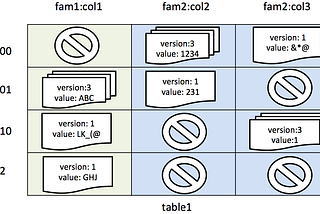
Karthik KumarIntroduction to ZooKeeperOver the past few weeks, I have been working with Apache ZooKeeper for a certain project at work. ZooKeeper is a pretty cool technology…Aug 16, 2014Aug 16, 2014
Karthik KumarUsing HBase to store and analyze NFL play-by-play dataIn celebration of Super Bowl Sunday, this post will examine how HBase can be used to model NFL play-by-play data.Feb 2, 2014Feb 2, 2014
Karthik KumarIndexing and Searching Tweets with LuceneIn this post, I will go through a demo of using Lucene’s simple API for indexing and searching Tweets. We will be indexing Tweets from the…Dec 14, 2013Dec 14, 2013
Karthik KumarIntroduction to Apache LuceneApache Lucene™ is a high-performance, full-featured text search engine library written entirely in Java. It is a technology suitable for…Dec 8, 2013Dec 8, 2013