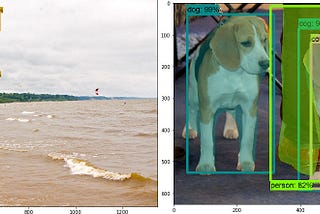
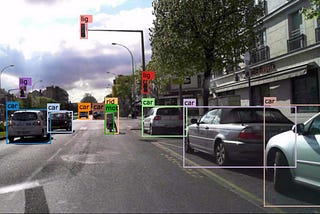
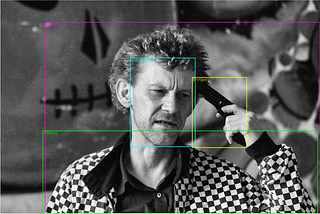
Karol Majek10 simple steps to Tensorflow Object Detection APIDon’t know how to run Tensorflow Object Detection? In this tutorial, I will show you 10 simple steps to run it on your own machine! We will…Jul 20, 20185Jul 20, 20185
Karol MajekBDD100K DatasetInstance segmentation, object detection, drivable areas and lane markings — all you can find in Berkley DeepDrive 100K Dataset. It consists…Jul 20, 20182Jul 20, 20182
Karol MajekOpen Images Dataset V430th April 2018 new version of Open Images Dataset V4 is released. There is also announced a challenge for best object detection results…Jul 20, 2018Jul 20, 2018
Karol MajekObject Detection in 4K Dashcam Videos4K dashcam videos versus State of The Art object detection deep nets such as YOLO, SSD or Mask RCNN.Dec 18, 20172Dec 18, 20172
Karol MajekinBecoming Human: Artificial Intelligence MagazineHow to use Google Cloud Vision APIGoogle offers machine learning REST API for image content understanding.Dec 14, 2017Dec 14, 2017
Karol MajekMooseFS: Multinode cluster using dockerDistributed file system demo using docker containers.Dec 11, 2017Dec 11, 2017
Karol MajekERL Emergency 2017 — Deep Learning to the rescueTeam IMM approach to European Robotics League Emergency 2017Oct 11, 2017Oct 11, 2017
Karol MajekSelf-Driving Car: Road segmentationSemantic segmentation is one of projects in 3rd term of Udacity’s Self-Driving Car Nanodegree program. The goal is to train deep neural…Sep 9, 2017Sep 9, 2017
Karol MajekHigh Resolution Face2Face with Pix2Pix 1024x1024Inspired by this work Dat Tran, I prepared my own dataset and trained improved Pix2Pix net to generate Polish youtuber Krzysztof Gonciarz…Aug 18, 20172Aug 18, 20172