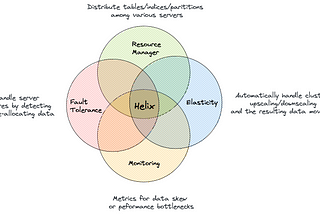
Kartik KhareinBetter ProgrammingApache Helix: The Distributed System’s Orchestra ConductorAchieve harmony in complex clusters using finite-state machinesFeb 28, 20231Feb 28, 20231
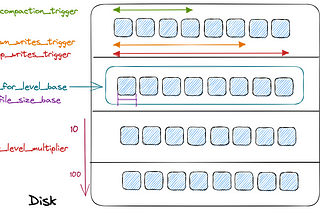
Kartik KhareinBetter ProgrammingNavigating the Minefield of RocksDB Configuration OptionsUnleashing the full potential of your rocksdb with the right configurationJan 3, 2023Jan 3, 2023
Kartik KhareincodeburstHow to Package Java Projects in Python Tar filesWell, before starting this article I should state that as a developer the situation which requires a language A project into language B…Mar 2, 20211Mar 2, 20211
Kartik KhareinApache Pinot Developer BlogUtilize UDFs to Supercharge Queries in Apache PinotLeverage the scalar functions in Pinot to expose your java methods to the SQL users.Sep 29, 20201Sep 29, 20201
Kartik KhareinApache Pinot Developer BlogLeverage Plugins to Ingest Parquet Files from S3 In pinotHow to use Spark to push billions of rows in S3 to Pinot without writing a single line of code?Aug 18, 2020Aug 18, 2020
Kartik KhareinTowards Data ScienceLearning Multi-dimensional indices: The next big thing in OLAP DBsAn introduction to Flood self-learning index algorithmApr 9, 20202Apr 9, 20202
Kartik KhareA Glimpse into my “WFH in Quarantine” LifeCOVID-19 has taken over the world and has forced people to stay at home. I am no exception and have been working from home for the past 3…Apr 1, 2020Apr 1, 2020
Kartik KhareincodeburstHow Does Zookeeper Servers Remain In sync?A glimpse into ZAB protocol in ZookeeperMar 30, 2020Mar 30, 2020
Kartik KhareinTowards Data ScienceWhy Apache Airflow Is a Great Choice for Managing Data PipelinesA look at capabilties which makes Airflow better than its predecessorsJan 20, 20201Jan 20, 20201
Kartik KhareinTowards Data ScienceDeploying ML Models in Distributed Real-time Data Streaming ApplicationsExplore the various strategies to deploy ML models in Apache Flink/Spark or other realtime data streaming applications.Jan 11, 2020Jan 11, 2020