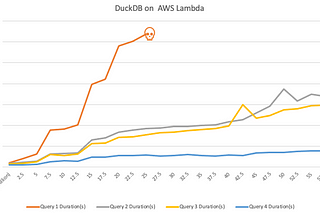
Gary LiProfiling DuckDB with AWS LambdaMainstream OLAP data analysis engines, such as Redshift and Spark, use distributed architecture to distribute computing tasks to various…Feb 27, 2023Feb 27, 2023
Gary LiWhen and How to extend Apache Spark?It is unnecessary to say how important the spark is for a modern data stack. Most of my customers use it to process data every day. They…Feb 2, 2023Feb 2, 2023