KnewtoninKnerdAnalyzing Java “Garbage First Garbage Collection” (G1GC) Logsby Carlos Monroy NieblasOct 11, 2016Oct 11, 2016
KnewtoninKnerdHow to Replace a Microservice: Swapping Out the Engine in Mid-Flightby Seth Charlip-BlumleinSep 20, 2016Sep 20, 2016
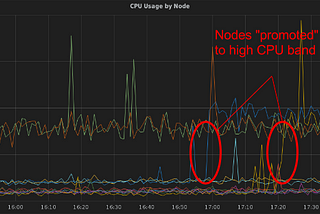
KnewtoninKnerdDigging Deep Into Cassandra Thrift Buffer Behaviorby Jeff BergerAug 30, 2016Aug 30, 2016
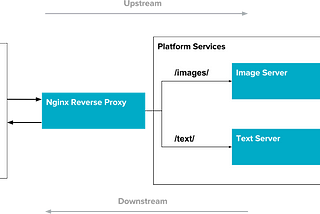
KnewtoninKnerdAPI Infrastructure at Knewton: What’s in an Edge Service?by Paul Sastrasinh, Robert MurcekMay 9, 2016May 9, 2016