Smart Insights: Leveraging Big Data and Machine Learning in Product Review Sentiment Analysis (II)
Note: The previous content from Section 1 to Section 3 is here: Smart Insights: Leveraging Big Data and Machine Learning in Product Review Sentiment Analysis (I)
4 Train and Tune Models on Amazon SageMaker
In my pursuit of a robust big data machine learning system for product review sentiment analysis, I opted to employ a random search strategy for hyperparameter tuning within the framework of the system. Section 4.1 delves into the spotlight on hyperparameter tuning, comparing the effectiveness of grid search and random search strategies. Subsequently, in Section 4.2, I proceed with model training and evaluation using SageMaker Autopilot.
4.1 Hyperparameter Tuning
In the process of training models in a big data machine learning system, hyperparameter tuning emerges as a crucial step aimed at optimizing model performance. This optimization may entail achieving the highest accuracy or minimizing errors to attain the best quality model. However, hyperparameter tuning is typically a time-consuming and compute-intensive process (Bischl, Bernd, et al, 2023). There are some popular algorithms that can be used for automated model tuning, such as grid search algorithm, and random search algorithm (Zahedi, Leila, et al, 2021). The gid search algorithm and random search algorithm both work reasonably well in smaller search bases, also both fail fairly quickly when the search space grows beyond a certain size (Bischl, Bernd, et al, 2023). The grid search algorithm tests every combination by training the model with each set of hyperparameters and selecting the best possible parameters. The advantage of grid search is that it enables us to explore all potential combinations. This approach works particularly well when dealing with a small number of hyperparameters and a limited range of values to explore for each hyperparameter. Nevertheless, as the number of hyperparameters or the range of values to explore for these hyperparameters increases, this process can become significantly time-consuming (Alibrahim, Hussain, and Simone A. Ludwig, 2021). In random search, it begins by defining sets of available hyperparameters, comprising the names and values I wish to explore. Instead of exhaustively searching every combination, the algorithm randomly selects hyperparameter values within the defined search space (Zahedi, Leila, et al, 2021). Additionally, stop criteria in the random search strategy, such as elapsed time or a maximum number of completed pieces of training, can be specified. When the stop criteria are met, we can select the best-performing set of hyperparameters from the trained models available so far. There are some of the key advantages of random search over grid search for hyperparameter tuning in big data machine learning (Alibrahim, Hussain, and Simone A. Ludwig, 2021):
● Efficiency: Random search significantly reduces the computational cost of hyperparameter tuning, making it more suitable for large-scale problems.
● Scalability: Random search can effectively handle high-dimensional hyperparameter spaces, which often arise in big data machine learning tasks.
● Exploration: Random search avoids the potential biases introduced by the predefined grid in grid search, allowing for a more comprehensive exploration of the hyperparameter space.
● Flexibility: Random search can be easily adapted to different hyperparameter distributions, making it more versatile for various machine learning models.
● Robustness: Random search is less prone to overfitting and local optima compared to grid search, leading to more generalizable models.
By comparing the grid search algorithm, random search is more efficient and less computationally expensive, especially when dealing with relatively large datasets and high-dimensional hyperparameter spaces (Alibrahim, Hussain, and Simone A. Ludwig, 2021). And I don’t have the need to test every combination by training the model with each set of hyperparameters. Hence, it’s better to adopt the random search strategy for hyperparameter tuning in this system.

Amazon SageMaker Automatic Model Tuning (AMT) is a comprehensively managed platform designed for large-scale gradient-free function optimization (Perrone, Valerio, et al, 2021). We can use AMT to do hyperparameter tuning at scale and find the best version of the model by running multiple training jobs on the dataset using the hyperparameter range values that we specify. For tuning strategies, SageMaker natively supports random optimization strategies. Here are the steps I take for hyperparameter tuning.

Step 1. Create PyTorch Estimator (Define fixed hyperparameters)

Include specific parameters from this set in the hyperparameters argument for both the PyTorch estimator and tuner. Set up the dictionary for the parameters to be included in the hyperparameters argument.
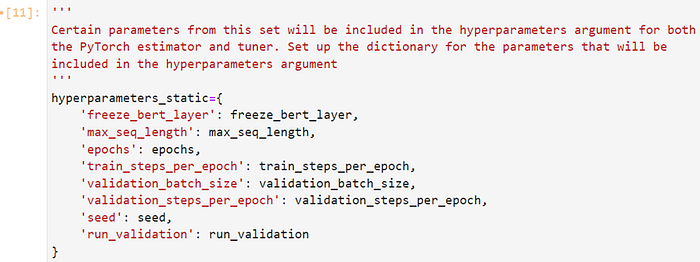
Employ a random search strategy to identify combinations of hyperparameters, within defined ranges, for each training job within the tuning process. Upon completion of the tuning job, we can choose the hyperparameters employed by the top-performing training job with respect to the objective metric.

Step2. Create Hyperparameter Tuning Job

Step 3. Analyze Results
The outcomes of the SageMaker Hyperparameter Tuning Job can be accessed through the analytics of the tuner object. Utilizing the dataframe function directly converts the results into a dataframe.
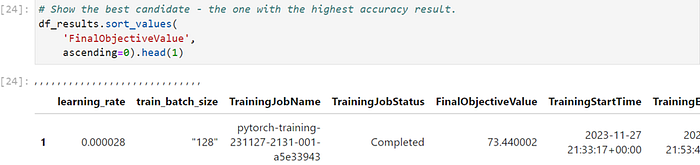
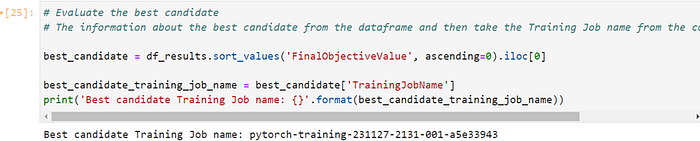

In the context of large-scale training and tuning, ongoing monitoring and selecting appropriate compute resources are crucial. Although I have the flexibility to opt for various compute options, determining the specific instance types and sizes requires a case-by-case approach. There is no one-size-fits-all solution; it hinges on comprehending the workload and conducting empirical testing to ascertain the optimal compute resources for the training process until I get the best candidate values. By performing a random search for hyperparameter tuning through the SageMaker Hyper-Parameter Tuning (HPT) Job on ml.c5.9xlarge, we can monitor the status of the tuning job and identify the hyperparameter configuration that yields the best candidate accuracy result, which is 73.44%. This section represents an additional research exploration into conducting hyperparameter tuning at scale. In the next section, I will delve into and implement how to scale up model training and evaluate the accuracy of models with AutoML on Sagemaker Autopilot.
4.2 Model Training, Model Evaluation
The process of model training and validation involves numerous iterations across various experiments. The objective is to identify the optimal combination of data, algorithm, and hyperparameters that yields the most effective model. For each selected combination, the model is trained and assessed against a designated holdout dataset.
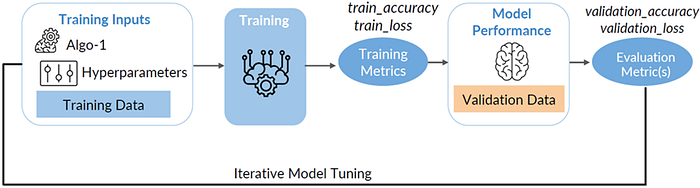
This cycle is repeated iteratively until a well-performing model is achieved based on the defined objective metric. Performing these iterations can be computationally intensive, and it is crucial to facilitate rapid iterations without encountering bottlenecks. The AutoML capabilities significantly alleviate the repetitive tasks associated with constructing and fine-tuning models, streamlining the extensive iterations and experiments usually necessary in the process ((Salehin, Imrus, et al., 2023)). Sagemaker Autopilot, Amazon Sagemaker’s AutoML implementation, not only automates the machine learning workflow but also provides a high degree of control and transparency (SageMaker Autopilot, 2023).
Autopilot ensures complete transparency by automatically generating and sharing feature engineering code. It produces Jupyter notebooks that guide us through the entire model-building process, covering data processing, algorithms, hyperparameters, and training configuration. These automatically generated notebooks can be used to replicate the experiment or make modifications for ongoing model refinement (SageMaker Autopilot, 2023). This allows us to comprehend the precise details of data processing and model construction. Here is the workflow that I conduct for the big data machine learning system on Amazon SageMaker. I’ve completed data ingestion, data analysis by data profiling, preparation and transformation in previous section/steps. In this subsection, I focus on model training and tuning.

Below is the fundamental steps I take to train and tune models on Amazon SageMaker Autopilot.
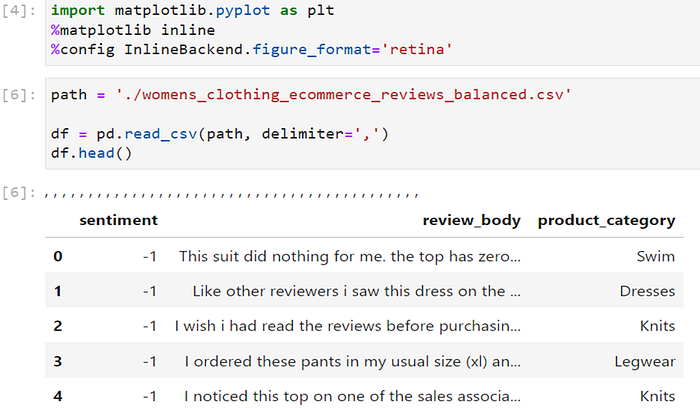
Step 1. Load Transformed Data Set
The data set has been processed in the previous steps. I directly load it in the SageMaker Lab development environment.
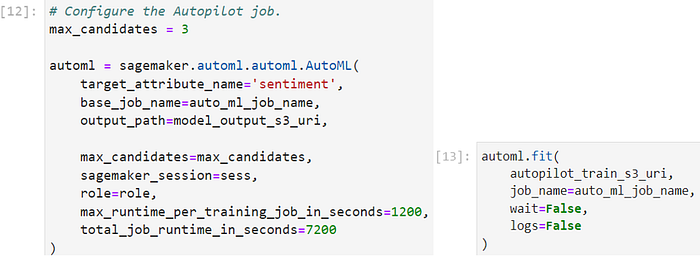
Step 2. Set up and Initiate the Autopilot job
Setting up and initiating the Autopilot job in Amazon SageMaker involves configuring the job with the necessary information and parameters.
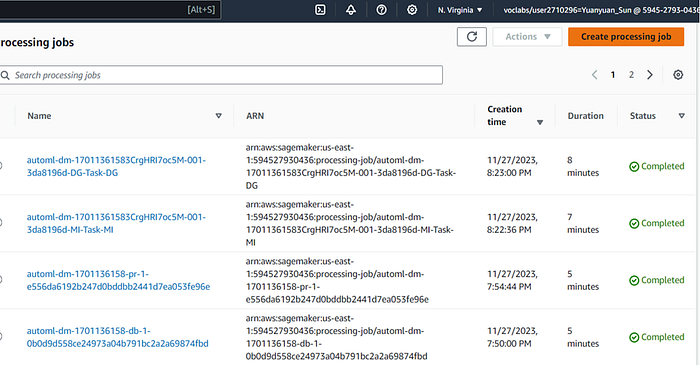
Step 3. Monitor the Progress of the Autopilot Job
Monitoring the progress of the Autopilot job is crucial to understanding how different models and hyperparameter configurations are being explored. In SageMaker, we can use the SDK capabilities to access insights, logs, and analytics during the Autopilot job execution. After initiating the Autopilot job, I monitor its progress directly from the notebook using the SDK capabilities.

We can review the processing jobs and track their progress on the SageMaker platform through user-friendly interfaces:
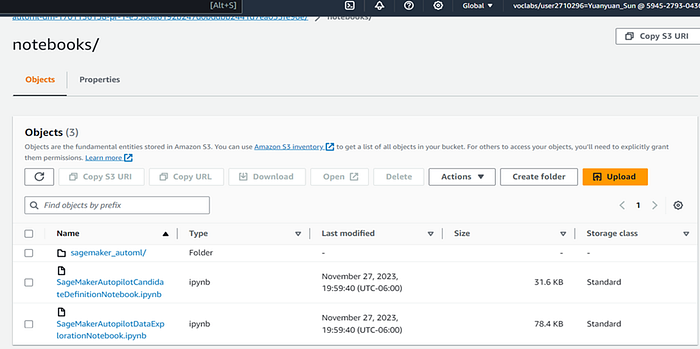
In this step, SageMaker AutoPilot produces two notebooks: Data Exploration, Candidate Definition.
● Data Exploration Notebook: This notebook provides an overview of the data, including its basic statistics, distribution of features, and relationships between features. It also identifies potential data quality issues, such as missing values and outliers.
● Candidate Definition Notebook: This notebook defines the different machine learning pipelines that Autopilot will evaluate for the task. Each pipeline consists of a set of preprocessing steps, an algorithm, and a set of hyperparameter values. Autopilot will train and evaluate each pipeline based on the data and select the best one based on its performance.
Step 4. Feature Engineering
The feature engineering step can be identified by checking the job status values. Specifically, I’ve mentioned the primary job status value InProgress and the secondary job status value FeatureEngineering. The primary job status (AutoMLJobStatus) being in the state of InProgress indicates that the Autopilot job is actively running. Additionally, the secondary job status (AutoMLJobSecondaryStatus) being FeatureEngineering specifically signifies that the Autopilot job is in the feature engineering phase. This is a good approach to monitor and wait for the completion of the feature engineering step before proceeding with the next phases of the Autopilot job.
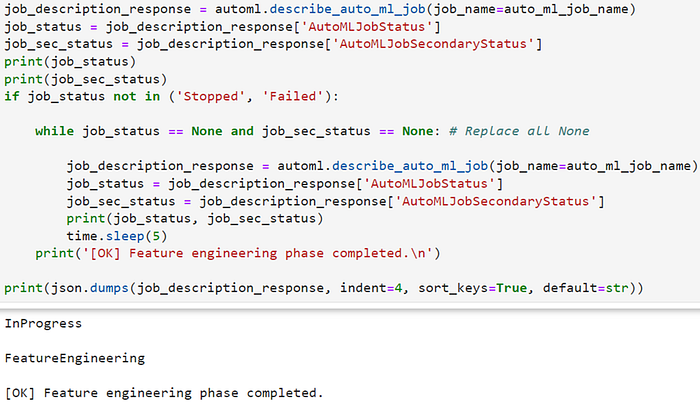
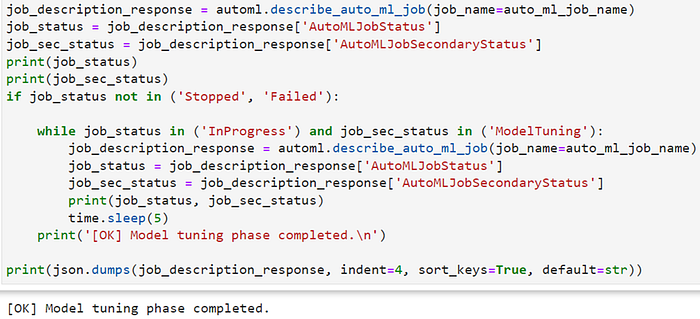
Step 5. Training and Tuning the Model
SageMaker Autopilot and the fact that it automates the end-to-end process of building, training, and deploying machine learning models. It emphasizes the goal of making machine learning more accessible to users without extensive expertise by automating tasks. We can verify the completion of the model tuning phase via the below code:
Step 5. Evaluating Output
I have successfully concluded the Autopilot job on the dataset and visualized the trials. We can now retrieve information about the best candidate model and review its details.
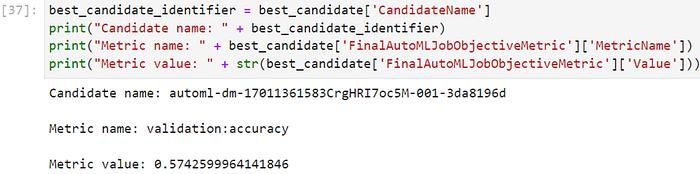
Above is the best candidate model generated by SageMaker Autopilot:
● Candidate Name: automl-dm-17011361583CrgHRI7oc5M-001–3da8196d
This is the name assigned to one of the candidate models generated by SageMaker Autopilot. Each candidate represents a different combination of hyperparameters and model architecture explored during the automated machine learning process.
● Metric Name: validation:accuracy
This indicates the evaluation metric used for assessing the performance of the candidate model. In this case, the metric is accuracy, which measures the proportion of correctly classified instances in the validation set.
● Metric Value: 0.5742599964141846
The metric value represents the actual performance of the candidate model with respect to the specified metric. In this instance, the accuracy of the model on the validation set is approximately 57.4%.
5. Summary
A robust big data machine learning system for sentiment analysis of product reviews has been successfully developed and implemented. By leveraging cutting-edge technologies and methodologies, the system demonstrates a commitment to efficiency, scalability, and accuracy in handling extensive datasets. I successfully demonstrated the feasibility of building a big data machine learning system for product review sentiment analysis by conducting a comparative analysis to choose appropriate technologies. Additionally, I performed data profiling using AWS Glue and AWS Athena, conducted bias detection using Amazon SageMaker Clarify, and carried out model tuning and training with Amazon SageMaker Autopilot. The big data machine learning system for product review sentiment analysis has achieved promising results, and further enhancements can be achieved by refining the data preparation and preprocessing steps, exploring additional machine learning algorithms, and optimizing the hyperparameters.
Reference
[1] Alibrahim, Hussain, and Simone A. Ludwig. ‘Hyperparameter Optimization: Comparing Genetic Algorithm against Grid Search and Bayesian Optimization’. 2021 IEEE Congress on Evolutionary Computation (CEC), IEEE, 2021, pp. 1551–59. DOI.org (Crossref), https://doi.org/10.1109/CEC45853.2021.9504761.
[2] Bischl, Bernd, et al. ‘Hyperparameter Optimization: Foundations, Algorithms, Best Practices, and Open Challenges’. WIREs Data Mining and Knowledge Discovery, vol. 13, no. 2, Mar. 2023, p. e1484. DOI.org (Crossref), https://doi.org/10.1002/widm.1484.
[3] Perrone, Valerio, et al. ‘Amazon SageMaker Automatic Model Tuning: Scalable Gradient-Free Optimization’. Proceedings of the 27th ACM SIGKDD Conference on Knowledge Discovery & Data Mining, ACM, 2021, pp. 3463–71. DOI.org (Crossref), https://doi.org/10.1145/3447548.3467098.
[4] Zahedi, Leila, et al. Search Algorithms for Automated Hyper-Parameter Tuning. arXiv:2104.14677, arXiv, 29 Apr. 2021. arXiv.org, http://arxiv.org/abs/2104.14677.
[5] Brumbaugh, Eli, et al. ‘Bighead: A Framework-Agnostic, End-to-End Machine Learning Platform’. 2019 IEEE International Conference on Data Science and Advanced Analytics (DSAA), IEEE, 2019, pp. 551–60. DOI.org (Crossref), https://doi.org/10.1109/DSAA.2019.00070.
[6] Feng, Z. (2023). Past and Present of Natural Language Processing. In: Formal Analysis for Natural Language Processing: A Handbook. Springer, Singapore. https://doi.org/10.1007/978-981-16-5172-4_1
[7] Black, Anne C., et al. ‘Missing Data Techniques for Multilevel Data: Implications of Model Misspecification’. Journal of Applied Statistics, vol. 38, no. 9, Sept. 2011, pp. 1845–65. DOI.org (Crossref), https://doi.org/10.1080/02664763.2010.529882.
[8] Branco, Paula, et al. ‘A Survey of Predictive Modeling on Imbalanced Domains’. ACM Computing Surveys, vol. 49, no. 2, June 2017, pp. 1–50. DOI.org (Crossref), https://doi.org/10.1145/2907070.
[9] Das, Sanjiv, et al. ‘Fairness Measures for Machine Learning in Finance’. The Journal of Financial Data Science, vol. 3, no. 4, Oct. 2021, pp. 33–64. DOI.org (Crossref), https://doi.org/10.3905/jfds.2021.1.075.
[10] Luque, Amalia, et al. ‘The Impact of Class Imbalance in Classification Performance Metrics Based on the Binary Confusion Matrix’. Pattern Recognition, vol. 91, July 2019, pp. 216–31. DOI.org (Crossref), https://doi.org/10.1016/j.patcog.2019.02.023
[11] K, Valantis. ‘Battle of The Giants: TensorFlow vs PyTorch 2023’. Medium, 28 Jan. 2023, https://medium.com/@valkont/battle-of-the-giants-tensorflow-vs-pytorch-2023-fd8274210a38
[12] ‘PyTorch’. Wikipedia, 4 Nov. 2023. Wikipedia, https://en.wikipedia.org/w/index.php?title=PyTorch&oldid=1183408410.
[13] ‘TensorFlow’. Wikipedia, 10 Sept. 2023. Wikipedia, https://en.wikipedia.org/w/index.php?title=TensorFlow&oldid=1174808074.
[14] ‘Bias Detection and Model Explainability — Amazon Web Services’. Amazon Web Services, Inc., https://aws.amazon.com/sagemaker/clarify/. Accessed 20 Nov. 2023.
[15] ‘Data Profiling’. Wikipedia, 4 Aug. 2022. Wikipedia, https://en.wikipedia.org/w/index.php?title=Data_profiling&oldid=1102297638.
[16] MLlib | Apache Spark. https://spark.apache.org/mllib/. Accessed 20 Nov. 2023.
[17] ‘Prepare Data For Ml, Data Wrangling Tool — Amazon SageMaker Data Wrangler — AWS’. Amazon Web Services, Inc., https://aws.amazon.com/sagemaker/data-wrangler/. Accessed 20 Nov. 2023.
[18] Singh, Aishwarya. ‘Ultimate Guide to Handle Big Datasets for Machine Learning Using Dask (in Python)’. Analytics Vidhya, 9 Aug. 2018, https://www.analyticsvidhya.com/blog/2018/08/dask-big-datasets-machine_learning-python/.
[19] SageMaker Autopilot — Amazon SageMaker. https://docs.aws.amazon.com/sagemaker/latest/dg/autopilot-automate-model-development.html. Accessed 29 Nov. 2023.
[20] Salehin, Imrus, et al. ‘AutoML: A Systematic Review on Automated Machine Learning with Neural Architecture Search’. Journal of Information and Intelligence, Oct. 2023, p. S2949715923000604. DOI.org (Crossref), https://doi.org/10.1016/j.jiixd.2023.10.002.
[21] Integration with AWS Glue — Amazon Athena. https://docs.aws.amazon.com/athena/latest/ug/glue-athena.html. Accessed 3 Dec. 2023.
