Czechitas Digitální Akademie | Analýza Recruitment procesu v Kiwi.com
Projekt pracuje s datasetem z ATS (applicant tracking system) Jobvite. Data z náborového procesu byla sebrána v období jednoho roku po implementaci systému Jobvite v recruitment týmu Kiwi.com. Do projektu jsme se pustily, protože jedna z nás s těmito daty pracuje na denní bázi, druhá nadšeně přivítala možnost vyzkoušet si takovou práci s reálnými daty. Cílem projektu je podrobnější analýza procesu náboru nových zaměstnanců.
Na úvod ještě trocha té HR terminologie:
- recruitment = nábor zaměstnanců
- hiring manager = šéf týmu, do kterého nového člověka nabíráme
- recruiter =člověk, který zastřešuje nábor, komunikuje s kandidáty
- requisition = otevřená pracovní pozice
Kapitola 1: Proč a k čemu?
Kiwi.com je středně velkou (1800 zaměstnanců) rychle rostoucí firmou. Během období jednoho měsíce (údaje z přelomu 2017/2018) prošlo rukama Recruitment týmu přibližně 1000 unikátních přihlášek na cca 45 různých pozic. Cílem týmu je kandidáty procesovat rychle, bezbolestně (dokonce i příjemně) pro obě strany a v co nejrychlejším čase je “doručit” do provozu firmy.

Potřeby týmu v oblasti zpracování a vyhodnocování dat:
- Kde inzerovat? Kolik investovat? Kde rozhodně neinzerovat? (vyhodnocování efektivity jednotlivých zdrojů kandidátů (doporučení, agentury, pracovní portály,…)
- Proč to trvá tak dlouho? Na kom/čem to stojí? Kdy dostanu těch dalších 20 lidí? (analýza průchodnosti recruitment procesem: čas, který kandidát stráví ve výběrovém řízení, úzká místa, bussines predikce)
- Potřebujeme další recruitery? Kdy? Včera?! Pomůže nám někde AI/nový tool? (řízení lidských/softwarových kapacit recruitment týmu)
- Na pozici se mi hlásí dost divní lidi. Ani jeden z nich neumí to, co potřebujeme. Kde je problém? (zpětná vazba HR marketingu ohledně kvality přijatých přihlášek)


Jedním z úskalí projektu byl nepochybně výchozí formát dat. Systém Jobvite má reportovací rozhraní s možností exportu konkrétních reportů (.pdf, .xls, .csv). Tyto reporty lze v rámci reportingového rozhraní upravovat: jak vizuálně, tak na úrovni dopočítávání vlastních metrik, agregace dat apod. Problémy současného systému jsou spojené zejména se skutečností, že i když systém trackuje téměř všechno (postup kandidáta procesem, každé jedno zobrazení CV, každý kontakt), dostat data ze systému v prezentovatelné formě je poměrně problematické.
Kde to v současné chvíli drhne:
- vizuální stránka reportů neodpovídá standardu, ve kterém je třeba data prezentovat managementu (= nikdo z toho nic nevyčte)
- veškeré ad hoc reporty je tedy třeba mezi exportem a předáním dál manuálně upravovat, případně kombinovat jednotlivé typy reportů dohromady (a to nechceš)
- systém nenabízí real-time dashboardy se snadnou možností řezu dat podle zájmu oblasti konkrétního manažera (“To mě vůbec nezajímá, tohleto.”)
- požadavky na pravidelné reporty není možné splnit přípravou reportu přímo v systému, tj. znovu dochází k manuálním úpravám mimo systém
- exportovaná data je potřeba před další prací čistit, protože se nepředpokládá, že s nimi bude někdo dál pracovat jinak, než formou přeposlání (vždyť je to HR!)
Ale jinak tým Kiwi.com Jobvite miluje. ♥ Je to skvělý, robustní software. Jen není krásný. Na UI je třeba zapracovat. Stejně jako na vizualizacích.
Kapitola 2: Co s tím teda provedeme?
Na začátek je třeba uvést, že pracujeme na projektu, od kterého se očekává reálné užití ve firemní praxi. Komplexita projektu lehce (lehce víc) přesahuje naše časové možnosti v rámci Digitální Akademie (což neznamená, že to vzdáme!). Celý battle plan je následující:
- Seznámit se detailně s daty a navrhnout datový model na papír.
- Automatizovat přesun aktuálních dat ze systému Jobvite do SQL databáze (Python) a čištění dat.
- Překlopit SQL databázi do Power BI.
- Vytvořit několik dashboardů a reportů obsahující aktuální data (část pro recruitment tým, část pro management), přístupná na pár kliků.
- Automatizovat generování pravidelných měsíčních reportů dle kritérií zadaných managementem.
Kapitola 3: Co jsme provedly

Začaly jsme poměrně logicky (bludišťák pro nás), datovým modelem. Na prvním meetingu nám to hrozně šlo, byly jsme super agilní, diskutovaly, všechno polepily post-itama (Post-ity jsou super, zvyšujou totiž agilitu. To je fancy název pro situaci, kdy nevíte nic, jen tak random něco děláte, nefunguje to a tak to zkoušíte jinak, funguje to ještě míň a tak pořád dokola.) Rozhodly jsme se jít cestou prohrabávání se raw daty, aby nám neunikla nějaká souvislost. Původní data z Jobvitu jsme měly ve dvou velkých ošklivých tabulkách (export v .csv):
- Tabulka Requisition (cca 400 záznamů): obsahovala informace o pracovních pozicích (jak se pozice jmenuje, ve kterém týmu je, ve které lokaci, kdo na pozici nabírá, kolik chce lidí, kdy se otevřela, kdy zavřela, kolik se nabralo lidí, atd.)
- Tabulka Application (cca 8000 záznamů): info o jednotlivých přihláškách na pozice (kdo, kam, kdy, odkud, z jakého zdroje, jakými kroky náborového procesu prošel, s kým se viděl a kdy, jestli z toho něco bylo, velikost bot, rodné příjmení dědečkovy matky a v podobném duchu dál)
Vypadalo to asi nějak takhle:

Pro zajímavost, původní datasety vypadaly takhle (GDPR friendly verze, jména si domyslete):
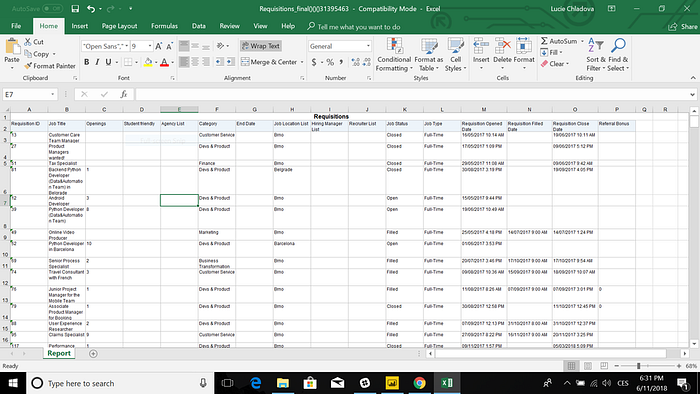
[..tady běží čas, konzultace s Léňou, furt je to špatný, potřebuje to unpivotovat, IDčka nesedí, podle toho vám nepůjde filtrovat, přijde mi to nějaký podezřelý, fuj to je hnusný..]
Co bylo třeba, než jsme datový model zvládly dát dohromady:
- rozlišit, co jsou fakta (např. [kandidát se přihlásil: datum] nebo [kandidáta jsme zamítli: datum]) a co jsou na jejich základě vypočítané metriky (např. [doba, která uplynula mezi přihlášením a zamítnutím: počet dnů]) — v modelu jsme chtěly mít jen fakta (o tom, proč to v tomhle projektu nebylo ideální, si můžeme pokecat osobně)
- rozsekat naše mega tabulky na menší funkční celky, číselníky a celou tu věc propojit
- občas se poprat s nesystémovými skutečnostmi (ne všechny přihlášky mají svou pracovní pozici, existují lidé, kteří jsou expertními kandidáty a hlásí se na všechno, občas se objeví nějaká nesmyslnost vložená do systému atd.)
Od téhle hrůzy:
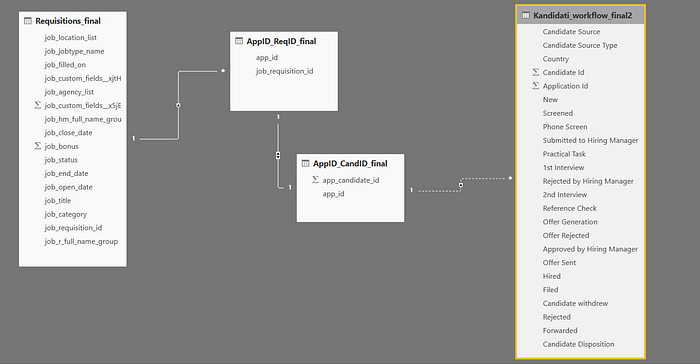
Jsme se dostaly k tomuhle krasavci:
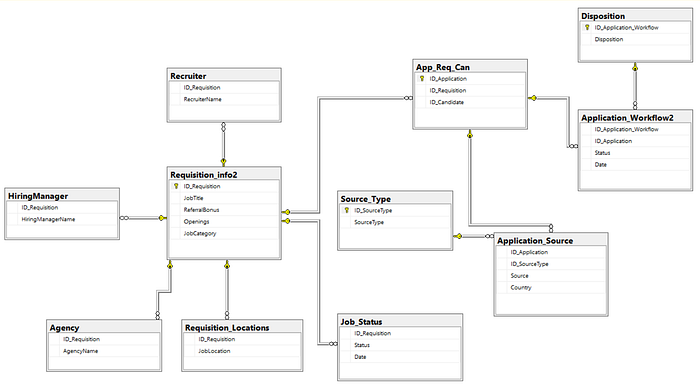
Je v něm spousta divných cizích slov, tady krátká legenda:
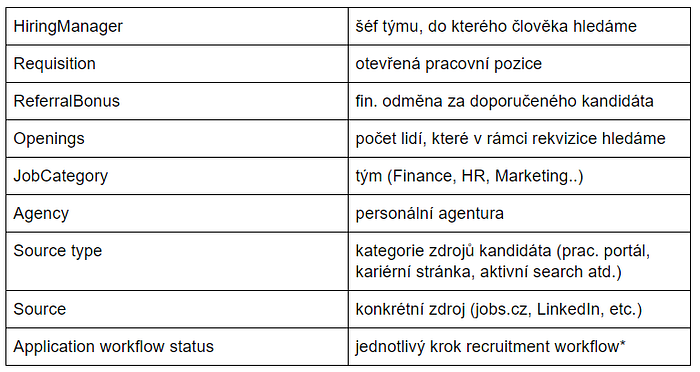
recruitment workflow = kandidát se v procesu pohybuje přes jednotlivé kroky (New: přihlásil se, Screened: CV viděl recruiter, PhoneScreen: úvodní telefon, Practical Task: praktický úkol/testování, 1st Interview : pohovor.. a tak dál až ke konci, kdy je Rejected (Nechceme ho!), Withdrew (Nechce on nás!) nebo Hired (Uf..)
Když jsme se konečně dostaly k datovému modelu, který se líbil všem, bylo skoro po Digitální Akademii. V tu chvíli už bylo jasno, že je potřeba osekat naše původní očekávání, a zaměřit se na to, co je v projektu zásadní — narvat data do rozumného datového modelu v SQL, z SQL databázi překlopit do Power BI a zkusit jestli vizualizace budou odpovídat představám. Pokud bude všechno ok (včetně datového modelu, který nás trápil nejvíc), má smysl investovat čas do automatizace přenosu dat z Jobvitu do naší databáze a taky do měsíčních reportů (což uděláme, ale až po DigiAkademii, takže se netěšte).
Proběhl import a čištění dat v SQL.
Takhle jednoduše se to dá napsat. Tímto bychom rády poděkovaly brněnské kavárně Podnebí (zdravíme!), jejíž obsluha byla nucena se dívat na nás dvě, jak 4 hodiny sedíme v rohu u jedné kávy, mátového čaje a třech počítačů a tváříme se střídavě hodně nadšeně a hned vzápětí naprosto zoufale. A pak si ten cheesecake nedej. :-D.
Fail. Learn. Repeat.
Během této session se nám několikrát stalo, že námi vytvořené vazby mezi jednotlivými tabulkami zmizely. A my jako: ‘Ty voe, to nesnáším, to SQLko! Dyť jsem to ukládala!” To bylo proto, že jsme se urputně snažily vyhnout skriptování (poučily jsme se), všechno naklikávaly a zapomněly používat tlačitko “Add relationship”. Výsledek: každou nastavenou vazbu jsme si ve finále přemazaly novou. To chceš.
Pak jsme celou naši věc překlopily do Power BI. Yes!

To nám šlo o poznání lépe. Jo, jedné Lucce chyběly některé tabulky, druhé Lucce vazby, ale tak vyřešilo se to, že jo. Teď bychom chtěly napsat, že pak už jsme jenom krásně klikaly a dělaly vizualizace a všechno bylo růžový, byla tam duha a po ní lítali jednorožci, ale takhle to úplně nebylo. Většinu vizualizací, které jsme měly v plánu udělat, se udělat i podařilo. Krásně se nám dařily průřezové reporty za celé období, hrdé jsme na naše hiring funnels a reporty výnosnosti jednotlivých zdrojů (Lucka, která v týmu pracuje, u nich měla několik aha momentů, pokud jde o návratnost prostředků investovaných do placených inzercí. Že jsou mrtvé pracovní portály, to se vědělo, ale od toho LinkedInu se přece jen čekalo víc ¯\_(ツ)_/¯.)
Co se ukázalo jako problém, který z naší strany bude vyžadovat ještě nějaké to přemýšlení, jsou kapacitní reporty. Kolik jsme v konkrétních měsících, týdnech hledali lidí? Máme sice kritická data otevření/uzavření jednotlivých pozic + informace o počtu lidí, které jsme hledali, ale promítnutí počtu v konkrétním momentu otevřených pozic od nás bude vyžadovat pravděpodobně dopočítání dalších metrik. Teď vedeme živou diskuzi, jestli bude lépe to udělat v SQL nebo Power BI nebo vůbec (vtípek, to nepřichází v úvahu).
Skvělá věc byla možnost validovat data zpětně se systémem Jobvite. Ono i v těch ošklivých tabulkách se dá většina naklikat nebo vyfiltrovat, takže víme, že jsme na svém (ne že bychom tam byly od začátku).
Následuje pár dashboardů a insights. Data jsou záměrně prezentována jen průřezově za celou firmu, ať si nějaké to tajemství taky necháme.
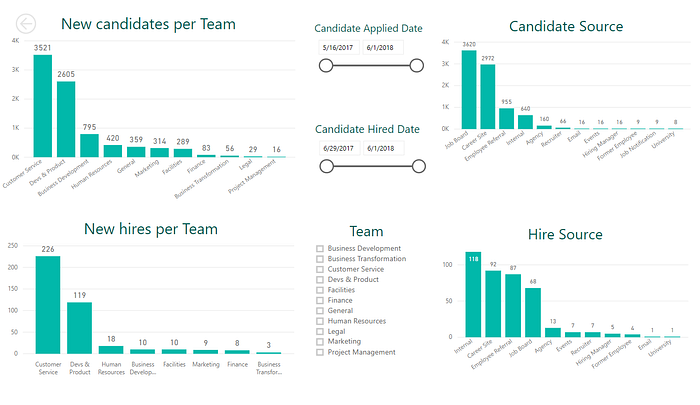
Potvrzují poměrně známé pravdy o tom, do kterých týmů firma nejvíce nabírá (Customer Support, Devs & Tech) a že zdroje bohaté na kandidáty zdaleka nejsou ty nejvýnosnější. Slicery umožňují data filtrovat podle jednotlivých oddělení a podle období, ve kterém se kandidát přihlásil/byl přijat.
Co z toho: Pracovní portály jsou zlo. Sypou se z nich CVčka, ale dobrého kandidáta aby člověk pohledal. Dobře z toho nevychází ani agentury, kde i s preselekcí je konverze žalostně nízká.
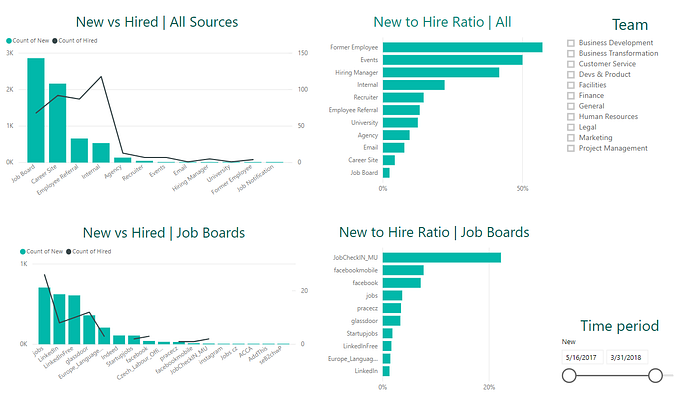
Při bližším pohledu na jednotlivé zdroje, počty nových a nabraných kandidátů už je jasné, které zdroje sice chrlí životopisy, ale nedoručují kvalitní kandidáty.
Co z toho: Skvěle fungují osobní doporučení, eventy, interní hiring a další velmi dobrý zdroj (z hlediska balancu počtu kandidátů a nabraných lidí) jsou zaměstnanecká doporučení. Největším zklamáním jsou placené inzeráty na LinkedInu, jejichž výnosnost je nejmenší (pro zajímavost a srovnání, zde jde o nejdražší formu placené inzerce).

V tomto typu reportu jsme se setkaly s poměrně nepříjemnou vlastností Power BI promítat data v rámci jednoho roku do sebe. Data máme sebraná od června 2017 do května 2018 (respektive 1.6. 2018, což vysvětluje drop na konci). Grafy se budeme snažit spravit tak, aby začínaly červnem a končily květnem, protože v tomto zobrazení poměrně zkreslují.
Co z toho: Závěr je jasný: Tým by uživil posily, jak počty pohovorů, tak počty telefonních prescreeningů od ledna poměrně dramaticky narostly.
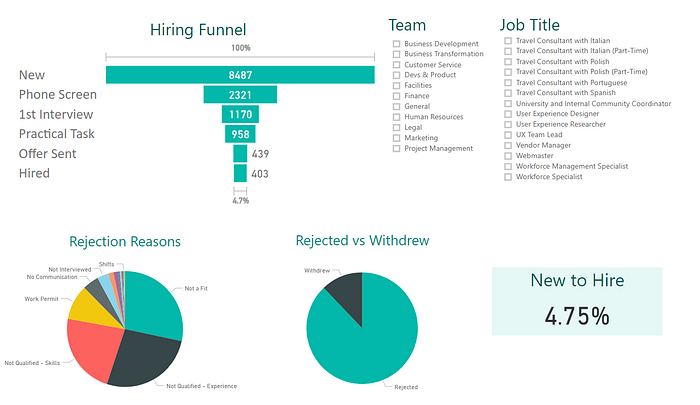

Hiring funnel je naše oblíbená vizualizace. Na začátku jste velmi šťastný recruiter, máte spoustu kandidátů. CVčka projdete, zjistíte, že půlka se přihlásila omylem. Pak kandidátům zavoláte, čtvrtina vám telefon nikdy nevezme, další čtvrtina už vzala práci jinde. Půlka se jich zdá dobrých, tak je pozvete na pohovor. Z nich půlka nedojde, čtvrtině se práce nelíbí, zbyde pár. Dáte jim jazykový test, protože na pozici potřebujete angličtinu. Zbyde jeden. Tak ho vezmete. A příště jim ten test dáte před pohovorem.
Nejčastěji jednoduše vázne komunikace, dalším z důvodů bývá jiná firma nebo plat. Podle slicerů si lze kandidáty vyfiltrovat podle týmů.
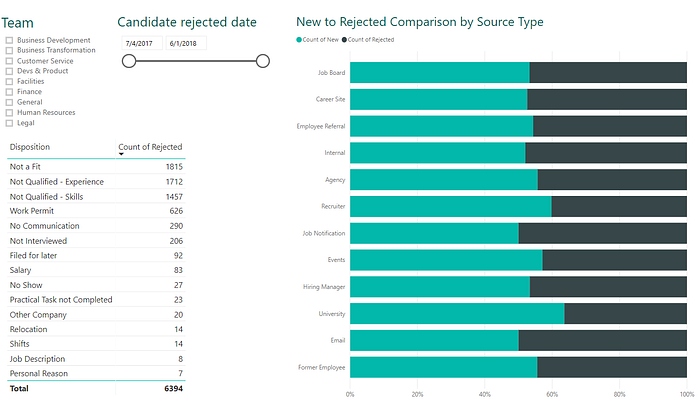
Mezi nejčastější důvody, proč nejsou kandidáti ve výběrovém řízení úspěšní, patří nedostatek zkušeností nebo znalostí, viz zmíněný test na angličtinu. Suverénně nejčastějším důvodem je “Not a fit”, tedy dispozice, kterou dostane kandidát, který k pozici nesedí z důvodů nezahrnutých v ostatních dispozicích. Může jít o situace, kdy kandidát do týmu nesedne osobnostně, případně se hlásí na pozici zcela mimo své pracovní zkušenosti. Vzhledem k tomu, že poměr kandidátů v této kategorii je poměrně vysoký (a zároveň těžko říct, co bylo za problém) lze týmu lze doporučit se nad touto dispozicí a jejím využíváním ještě zamyslet.
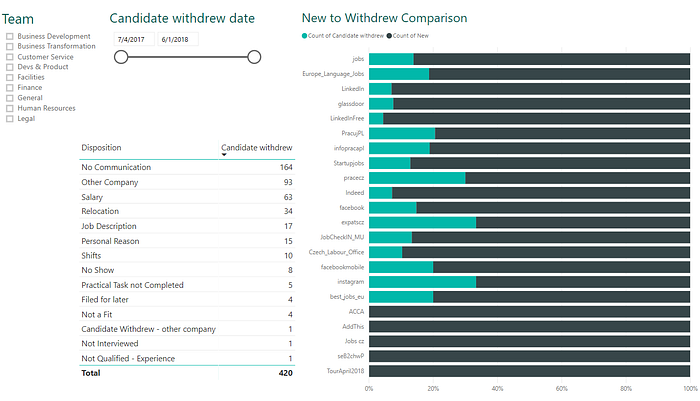
Odevšud. Doslova.
Kapitola 4: K čemu to všechno bylo
Kladně hodnotíme jasně stanovené cíle projektu, které se nám v osekané verzi podařilo splnit a lze je využít v praxi. To znamená, že na základě zpracovaných dat lze tvořit přehledné a pravidelně aktualizované dashboardy v Power BI. Ty budou sloužit pro prezentaci hiring manažerům a informovat např. o vytíženosti recruitment týmu, o aktuálních zdrojích kandidátů a jejich výnosnosti, o tom, proč kandidáti z procesu odpadávají. V projektu bychom chtěly dále navázat automatizací přenosu dat z Jobvitu do naší databáze a taky do měsíčních reportů. Výsledky projektu tedy budou mít přímý dopad na každodenní práci recruitment týmu a představovat časovou úsporu při práci s daty. Práce na měsíčním reportu nyní zabere 3 až 4 hodiny jednomu recruiterovi.
Při práci na projektu se nám potvrdilo, že většinu času ajťák tápe a snaží se přijít na nejlepší možné řešení. Učí se spousty nových věcí, které si následně ověřuje v praxi, zda mu pro jeho projekt fungují. A když ne, tak googlí a učí se dál, jede si na své flow vlně a nevnímá čas. Náš největší rekord bylo 5 hodin v kuse nad projektem v příjemné kavárně s velmi vtíravým reggae. To bylo: “Luci, už ti z té hudby taky hrabe?” “Jo. Tak makáme dál.” :)
Poznaly jsme, že nejtěžší je opravdu umět se dobře zeptat (jak mentora, tak Googlu nebo Stack Overflow) a správně pochopit problém!!! Ve finále se nám občas stalo, že cestě k úspěchu bránila drobná chybička, která nás malinko přiváděla k šílenství a člověk měl pocit, že se vrátil do dětských let, když pořád opakoval: A proč?!
Motivací, proč se pustit do projektu byla možnost vyzkoušet si práci s reálnými daty, která se pravidelně využívají pro reporty a nejrůznější prezentace v Kiwi.com. Pro práci na projektu jsme využili většinu dovedností, které jsme získaly v průběhu akademie: od Excelu až po PowerBI (ideálně chceme zakončit ještě Pythonem :)). Výzvou bylo data správně pochopit a vymyslet, jak grafy donutit ukazovat údaje, které chceme zobrazit. Téma projektu nám přišlo zajímavé i proto, že oblast HR dat, jak obecných, tak dat z náboru, je v ČR poměrně nové a atraktivní. A nedotčené. Hlavně nedotčené!
Kapitola 5: A to je všechno, přátelé!
Závěrem bychom chtěly poděkovat skvělé mentorce, lezkyni a slacklinerce Léně Kmeťové za podporu, diskuze a trpělivost, našim rodinám a přátelům za shovívavost/respektování naší dočasné nepřítomnosti v jejich životech a Czechitas za skvělý kurz, který jsme chvílema nenáviděly, ale tak už to v životě chodí. Kolik dáš, tolik dostaneš.
P.S. Budou tu updaty, pracujeme na posledních úpravách.
P.S.S.
