Parallel Quick Sort on C++
Hey there fellow coders! Are you tired of waiting for your sorting algorithms to finish executing on large datasets? Well, have no fear because parallel algorithms are here! In this article, we’ll be diving into the world of parallel quicksort in C++. We’ll explore how parallel algorithms can significantly speed up our sorting processes and create lightning-fast applications. So buckle up and get ready to optimize your code like a pro!
Why that is important?
So why is parallel quicksort such an important topic? Well, first of all, it’s no secret that sorting large amounts of data can be a time-consuming process. By utilizing parallel algorithms, we can break down the sorting process into smaller, more manageable chunks that can be executed simultaneously. However, it’s worth noting that each algorithm requires a unique approach to parallelization. There is no one-size-fits-all solution when it comes to parallelizing algorithms, and quicksort is no exception. That’s why understanding the parallelization process for quicksort is crucial for any programmer looking to optimize their sorting algorithms.
Sequential version of qsort
Before we dive into the parallel version of quicksort, let’s take a look at the sequential version. Quicksort is a divide-and-conquer algorithm that works by selecting a pivot element from the array and partitioning the other elements into two sub-arrays, according to whether they are less than or greater than the pivot. The sub-arrays are then recursively sorted. This process continues until the entire array is sorted.
In terms of time complexity, the worst-case scenario for quicksort is O(n²), which occurs when the partitioning process always selects the smallest or largest element as the pivot. However, on average, quicksort has a time complexity of O(n*log n), which is faster than other sorting algorithms such as selection sort or bubble sort.
One of the main issues with the sequential version of quicksort is that it has two independent sub-tasks that must be executed in a specific order. This can lead to slow performance when sorting very large datasets. Additionally, the recursive nature of the algorithm can lead to stack overflow errors if the depth of recursion is too large.
On the diagram you can see the proof of my words:
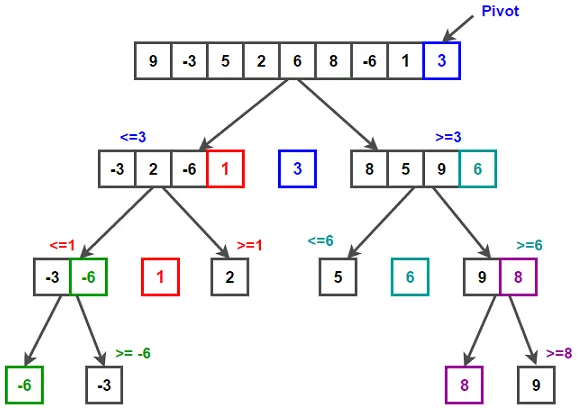
As you can see, the subtasks are not required to be synchronized at all because they do not affect each other.
Parallelize over std::async
One way to parallelize quicksort is to use the std::async function in C++. This allows us to create tasks that run asynchronously in separate threads, which can significantly speed up the sorting process.
However, when we execute a large number of threads within the scope of a single algorithm, it can put a lot of strain on the operating system. This is because each thread requires its own resources, such as memory and CPU time. As a result, if we create too many threads, it can lead to resource contention and slow down the overall performance of the system. In the next example of parallelization we will se how to fix this
To address this issue, we can use a technique called fork-join parallelism. This involves dividing the work into smaller, more manageable tasks, and then executing them in parallel using multiple threads. Once all the threads have completed their work, we join the results back together to obtain the final output.
The code demonstrating how it could be implemented is below:
template <typename T, int sync_size = 10'000>
void qsort_async_util(std::vector<T>& v, int left, int right)
{
int i = left;
int j = right;
T pivot = middle_of_three(v[left], v[(left + right) / 2], v[right]);
while (i <= j)
{
while (v[i] < pivot)
i++;
while (v[j] > pivot)
j--;
if (i <= j)
{
std::swap(v[i], v[j]);
i++;
j--;
}
}
std::future<void> left_future;
std::future<void> right_future;
if (left < j)
{
if (j - left < sync_size) {
qsort_async_util(v, left, j);
}
else {
left_future = std::async(std::launch::async, [&v, left, j]() { qsort_async_util(v, left, j); });
}
}
if (i < right)
{
if (right - i < sync_size) {
qsort_async_util(v, i, right);
}
else {
right_future = std::async(std::launch::async, [&v, i, right]() { qsort_async_util(v, i, right); });
}
}
if (left_future.valid())
left_future.wait();
if (right_future.valid())
right_future.wait();
}
template <typename T, int SZ = 10'000>
void qsort_async(std::vector<T>& v)
{
qsort_async_util<T, SZ>(v, 0, v.size() - 1);
}As you can see from the example, each util function call sorts given piece of vector over pivot value. Then it creates two threads that do the same. The calls will be proceeded asynchronously until the size of sub-array become less than ‘sync_size’. It was implemented in a such way because it some time point resources needed to sort the sub-array will be less than than resources needed for creating thread.
Parallelize with thread pool
The previous code example showcased how to parallelize quicksort using the std::async function in C++, which creates tasks that run asynchronously in separate threads. However, creating too many threads can oveload the operating system and slow down performance. To address this issue, a more efficient approach is to use a thread pool instead of individual threads for each task. The thread pool creates a fixed number of threads and distributes tasks among them, which avoids resource contention and the overhead of managing many threads. For our implementation, we will use the thread pool provided by the Boost.Asio library, which can significantly improve the performance of our parallelized quicksort algorithm while avoiding resource-related issues.
Here is the code example of the implementation of quick sort that uses thread_pool:
template <typename T, int sync_size = 10'000>
void qsort_pool_util(std::vector<T>& v, int left, int right, boost::asio::thread_pool&& tp) {
int i = left;
int j = right;
T pivot = middle_of_three(v[left], v[(left + right) / 2], v[right]);
while (i <= j) {
while (v[i] < pivot)
i++;
while (v[j] > pivot)
j--;
if (i <= j) {
std::swap(v[i], v[j]);
i++;
j--;
}
}
if (left < j) {
if (j - left < sync_size) {
qsort_pool_util(v, left, j, std::move(tp));
}
else {
boost::asio::post(tp, [&v, left, j, &tp]() { qsort_pool_util(v, left, j, std::move(tp)); });
}
}
if (i < right) {
if (right - i < sync_size) {
qsort_pool_util(v, i, right, std::move(tp));
}
else {
boost::asio::post(tp, [&v, i, right, &tp]() { qsort_pool_util(v, i, right, std::move(tp)); });
}
}
}
template <typename T, int SZ = 10'000>
void qsort_pool(std::vector<T>& v) {
boost::asio::thread_pool tp(std::thread::hardware_concurrency());
qsort_pool_util(v, 0, v.size() - 1, std::move(tp));
tp.join();
}What is general difference? The first one is that we do not wait forked tasks, but just push them into the thread pool that is used on per algorithm call. I have tried using it like it could be implemented in Java with the help of ForkJoinFramework to join tasks, but actually it didn’t work because all the threads was busy by several tasks that were waiting for other that was pushed and were waiting for that ones which were running in threads right now. It was kind of dead lock that we should avoid. So, as all the tasks calls can be ran asynchronously in the same queue as pushed, I do not wait them to execute, but wait for all tasks to be executed in root quick sort.
The implementation with thread pool improved performance of the algorithm compared to use std::async average on 11% that I think is amazing result.
Performance table
On the table below it is demonstrated how much time it takes to do a quick sort where it is compared sequential version and two parallel that are described in the article. On my 6 cores 12 threads i7–8750h average boost for ‘std::async qsort’ is 4,07 to 4,42 depending on ‘sync size’ and actual array size. As for ‘pool’ implementation, the performance is around 4,53 to 4,99 that is average 11% faster than previous version.

Repo
The project is hosted on github so you can check it by your own:
https://github.com/lucky-rydar/tpo-cw
Conclusion
So, during the article it was described two ways of how we can implement parallel version of such a common algorithm as Quick sort on C++. It was demonstrated the results of performance test that shown actual boost of using thread pool compared to std::async and other unmanaged ways to use threads.
Hope, this article was interesting and useful for you. If you like my work, make sure you are following me on Medium and you will not skip new articles and posts. Do not forget to clap if you are reading this, it motivates me to write more about interesting things in programming world.
