Import JSON into BigQuery with Google Cloud Functions
BigQuery is a powerful tool for building a data warehouse, allowing you to store massive amounts of data and perform super-fast SQL queries without having to build or manage any infrastructure.
The typical ETL process involves three steps:
- Extract: Pull data from a source, such as a database (LDAP, MySQL, MongoDB, etc.) or an API (GitHub, Google, Workday, etc.)
- Transform: Prepare source data for destination (if necessary).
- Load: Import prepared data into destination.
Regardless of your source and the steps you may need to take to prepare your data, there are several options for loading data into BigQuery. For this example, we’ll be loading data from Cloud Storage, specifically JSON.
Once your newline-delimited JSON file is ready to load, you can upload it to a Cloud Storage bucket, and then there are a couple of options for how to get it into BigQuery.
- BigQuery Data Transfer Service (schedule recurring data loads from GCS.)
- Create a new Load Job.
We want to be able to load new data at any time, rather than waiting for the next scheduled job to run. So, instead of using the Data Transfer Service, we want to create a Load Job as soon as our file is uploaded. To make things as simple as possible, we also want to enable schema auto-detection.
Since we want to create a load job every time a new file is uploaded to GCS, we can simply create a Cloud Function that responds to Google Cloud Storage Triggers.
Architecture
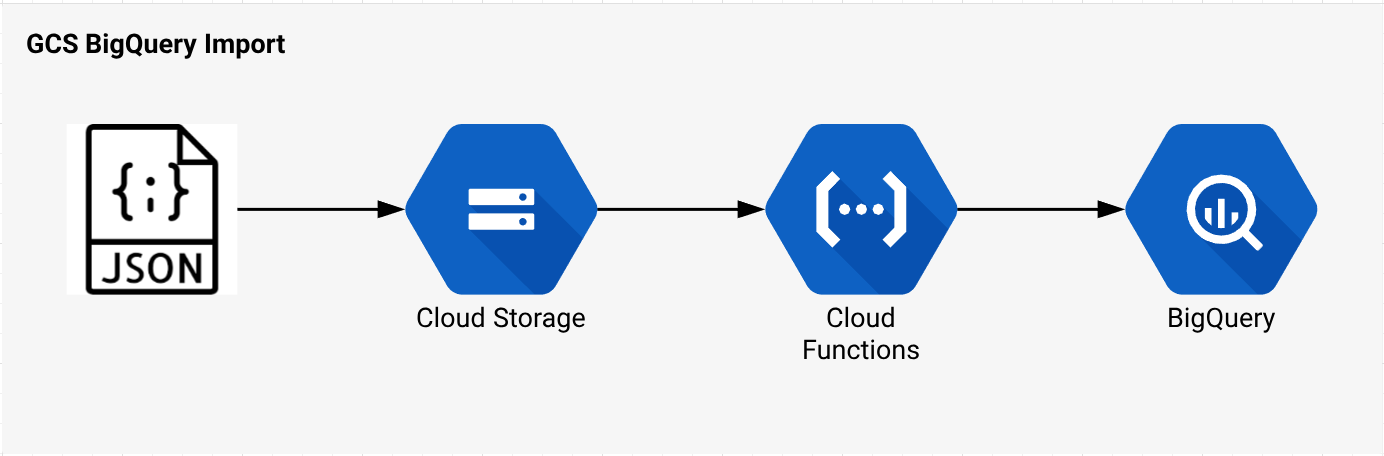
With this design, the process for getting data into BigQuery is as simple as:
- Extract data from source.
- Transfer data into newline-delimited JSON.
- Upload JSON file to GCS bucket.
The moment a new file is uploaded to correct GCS bucket, the Cloud Function is kicked off and creates the new Load Job with schema auto-detection, which loads the data into a BigQuery table.
Source
Source code for the Cloud Function is available on GitHub:
Installation
Currently, this all assumes that you are using a single project to host the BigQuery Datasets, Cloud Function, and Cloud Storage Bucket, so the default IAM permissions on the Compute service account should be sufficient. If your BigQuery data is in a different project than the Bucket and Cloud Function, you will need to grant BigQuery IAM access to the Compute Service account.
- Create a GCP Project if you do not already have one.
- Create a GCS Bucket in that Project.
- Update the
deploy.shscript to reflect yourBUCKETandPROJECT. - Run
deploy.shto deploy the Cloud Function into your Project.
Usage
- Create newline-delimited JSON file with your data.
- Upload JSON file to GCS bucket as
DATASET/TABLE.jsonwhereDATASETandTABLEreflect the name of the BigQuery Dataset and Table where you’d like the data stored.
Once the JSON file has been uploaded to the GCS Bucket, the Cloud Function runs, determines the name of the Dataset and Table (based on the filename), and then it creates a new Load Job with schema auto-detection enabled.
If all goes well, you can load up the BigQuery Console for your Project and you will see the newly-created Dataset and the Table containing your data.
Now, start writing some SQL queries and enjoy!

