Regresi Linear Sederhana (Supervised Learning) Menggunakan dataset ‘Boston Housing’ — Part 1
Bagaimana memprediksi harga rumah di Boston?

Sekilas Regresi Linear
Asumsi Regresi Linear
- Memiliki hubungan linear; bisa dicek menggunakan residual plot
- Residual memiliki variansi yang stabil atau konstan; bisa dicek menggunakan residual plot
- Residual antar observasi tidak berkorelasi; disebut juga observasi yang independen, juga dapat dicek menggunakan residual plot
- Residual berdistribusi normal; dapat dicek menggunakan density plot atau QQ-plot
Dataset ‘Boston Housing’
Dataset berasal dari link berikut: Boston Housing dataset
Penjelasan variabel dataset:
- CRIM: Per capita crime rate by town
- ZN: Proportion of residential land zoned for lots over 25,000 sq. ft
- INDUS: Proportion of non-retail business acres per town
- CHAS: Charles River dummy variable (= 1 if tract bounds river; 0 otherwise)
- NOX: Nitric oxide concentration (parts per 10 million)
- RM: Average number of rooms per dwelling
- AGE: Proportion of owner-occupied units built prior to 1940
- DIS: Weighted distances to five Boston employment centers
- RAD: Index of accessibility to radial highways
- TAX: Full-value property tax rate per $10,000
- PTRATIO: Pupil-teacher ratio by town
- B: 1000(Bk — 0.63)², where Bk is the proportion of [people of African American descent] by town
- LSTAT: Percentage of lower status of the population
- MEDV: Median value of owner-occupied homes in $1000s
Regresi Linear Sederhana (1 Variabel)
Persiapan Data
Pertama, mari import library yang diperlukan untuk analisis ini.
Kemudian, masukan data yang dapat didownload di sini: download data
Saya menaruh data tersebut di Google Drive saya, maka untuk menarik data tersebut saya memerlukan kode berikut.
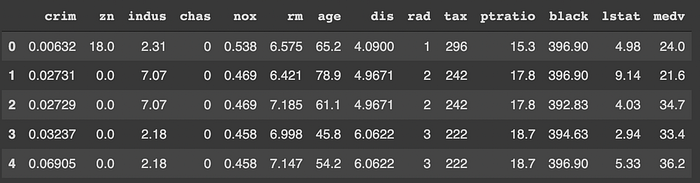
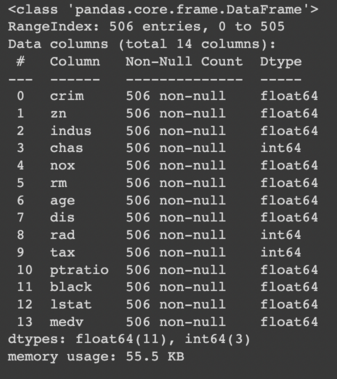
Kita dapat menggunakan command df.info() untuk melihat rangkuman kolom dalam dataset kita.
Menentukan Variabel yang Digunakan untuk Simple Linear Regression (1 Variabel)
Dataset yang digunakan, ‘Boston Housing’ merupakan dataset yang memiliki banyak variabel. Di sini kami akan menggunakan medv sebagai target dan kami akan memilih satu variabel yang memiliki korelasi paling kuat terhadap variabel target. Maka, kami akan melakukan analisis korelasi untuk menentukan variabel mana yang akan dipakai dalam model regresi linear sederhana kali ini.
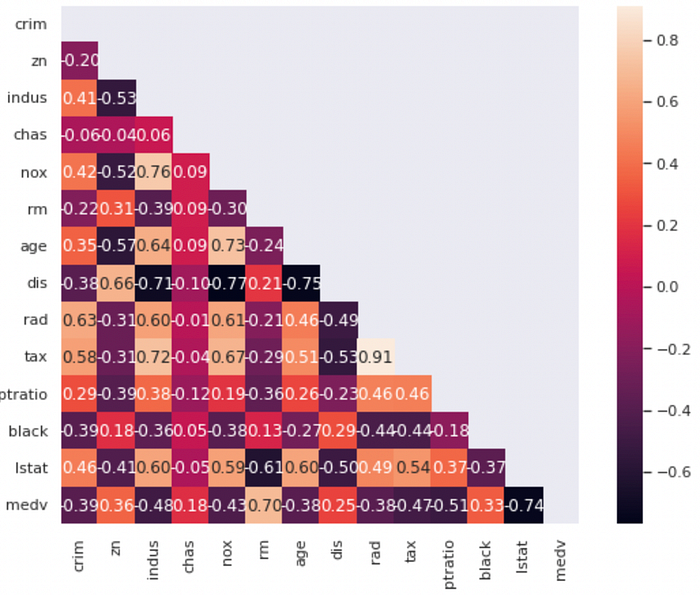
di sini ada 2 variabel yang memiliki korelasi paling kuat dengan medv
rmberkorelasi positif dengan nilai 0.70
2. lstat berkorelasi negatif dengan nilai -0.74
Di sini kita bisa melakukan pengecekan dengan menggambar scatter plot antara variabel tersebut dengan target variabel kita medv


Di sini kita akan mencoba membangun regresi linear sederhana untuk menggunakan variabel rm untuk memprediksi medv
#Split Data
#Train Model
#Model Coefficient
Model Diagnostics
Setelah ini, kita akan melakukan pengecekan untuk melihat apakah model ini memenuhi asumsi yang dibahas sebelumnya dengan melihat residual plot dan QQ plot.
Residual Plot
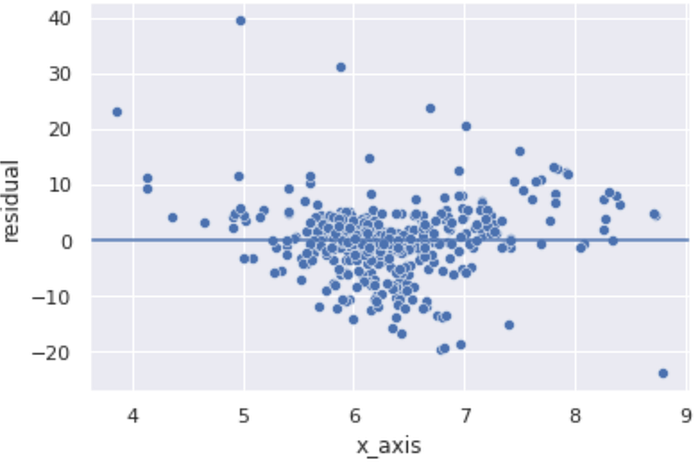
Dari residual plot, terlihat residunya terlihat kurang lebih acak sehingga memenuhi asumsi.
QQ plot
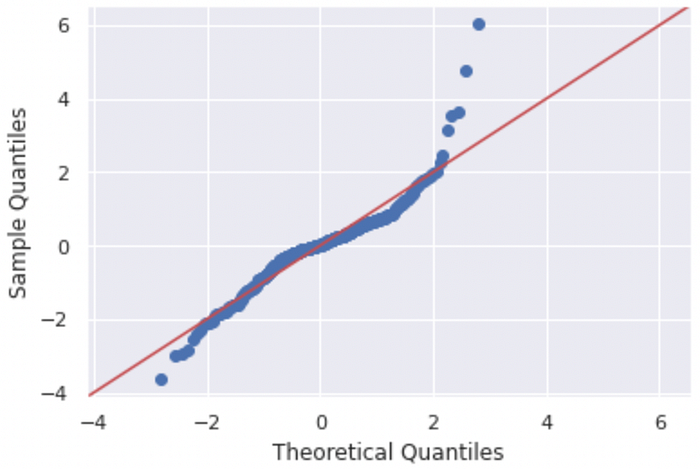
Dari QQ plot meskipun ada penyimpangan dari garis teoretis (warna merah), namun secara umum masih mengikuti garis tersebut sehingga bisa dianggap berdistribusi normal.
Setelah mengecek asumsi, kita perlu mengevaluasi apakah model kita cukup baik. Di sini kita akan menggunakan R-squared dan RSME sebagai metrics evaluasi.
Evaluation Training Sets
The evaluation for training set
— — — — — — — — — — — — — — — — — — —RMSE is 6.557180458295626R2 score is 0.5050658352776293
Interpretasi dari hasil ini (R2) adalah bahwa saat dilakukan pengecekan dengan training sets, model kita yang menggunakan rm menjelaskan 50.5% variasi perubahan pada medv . Angka ini tidak cukup baik, sehingga pada tahapan berikutnya kita perlu meningkatkan performance model kita.
Evaluation Test Sets
The evaluation for test set
— — — — — — — — — — — — — — — — — — —RMSE is 6.792994578778734R2 score is 0.3707569232254778
Interpretasi dari hasil ini (R2) adalah bahwa saat dilakukan pengecekan dengan training sets, model kita yang menggunakan rm menjelaskan 37% variasi perubahan pada medv . Angka ini berarti model kita tidak bisa mengeneralisasi hasilnya dengan baik.
Di tahap selanjutnya, kita akan meningkatkan performance model menggunakan model yang lebih rumit, yaitu model regresi linear berganda.
About Me
Saat ini saya bekerja sebagai researcher di bidang Edtech. Lulusan Institut Teknologi Bandung jurusan Manajemen Rekayasa Industri tahun 2012. Saya juga merupakan alumni pertukaran pelajar AFS-YES tahun 2011 selama 1 tahun ke Amerika Serikat di tahun 2011. Hubungi saya lewat LinkedIn dan kunjungi Github saya.
