Hindi Character Recognition
Table of Contents
Introduction
Character recognition is a process that allows computers to recognize written or printed characters such as numbers or letters and to change them into a form that computers can use.
As a part of this case study, we are going to recognize “Hindi characters”.
Machine Learning Formulation
It is a Character Recognition problem related to computer vision, where our task is to predict the Hindi character present in the image.
Constraints
The Model should predict or recognize the character present in the image in real-time. So the latency of the model should be low.
Dataset Overview
The Dataset consists of Images belonging to 46 different Hindi Characters.
The dataset consists of 78,200 Train images and 13,800 Test images belonging to 46 classes.
Performance Metrics
Since this is a classification problem we will be using ‘Accuracy’ as our metric for this problem.
Exploratory Data Analysis (EDA)
First, let's check the few images from the dataset.

Now let's check if the Train dataset is balanced or not.

From the above bar plot, we could clearly understand that the ‘Train dataset’ is well balanced.
The images in the dataset have large dimensionality we will try to reduce the dimensionality and visualize the data points using T-SNE.
Since the dataset is large and as T-SNE takes a lot of time to reduce the dimensionality, we will be using only random 25,000 images to visualize.
A 2-Dimensional representation of T-SNE

A 3-Dimensional representation of T-SNE

From the above plots, we can clearly observe that all the images are mixed together without forming any groups of similar classes.
Modeling
In this section, we are going to build a “Convolutional Neural Network Architecture” using convolutional layers, Max-Pooling layers, and Dense Layers
What is a Convolutional Neural Network?
Convolutional Neural Network is also known as ConvNet, is a deep neural network that is applied to various computer vision problems especially for image problems.
The building block of a ConvNet is the Convolutional Layer.
What does Convolutional Layer do?
The convolutional layer computes the convolutional operation of the input images using kernel filters to extract fundamental features from an image
The most common type of convolution that is used is the 2D convolution layer which is usually abbreviated as Conv2D. A filter or a kernel in a conv2D layer “slides” over the 2D input data, performing an elementwise multiplication. As a result, it will be summing up the results into a single output pixel. The kernel will perform the same operation for every location it slides over, transforming a 2D matrix of features into a different 2D matrix of feature

What does Max-Pooling Layers do?
Pooling is a feature commonly used in Convolutional Neural Network architectures. The main idea behind a pooling layer is to “accumulate” features from maps generated by convolving a filter over an image. Formally, its function is to progressively reduce the spatial size of the representation to reduce the number of parameters and computation in the network.
There are many types of poolings in which Max-Pooling is one of the types and the functionality of a Max-Pooling Layer is to take the maximum pixel value from a sub-matrix of defined ‘pool_size’.
In the below image the pool_size is 2x2.
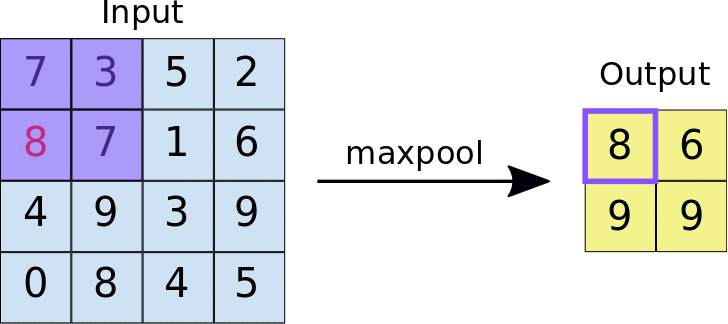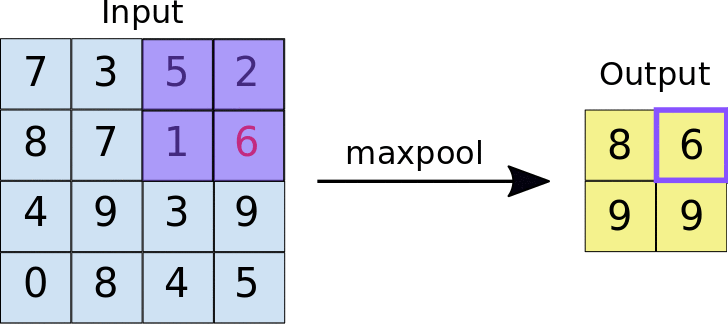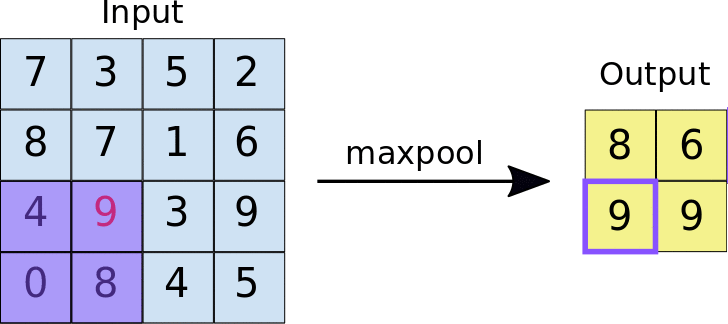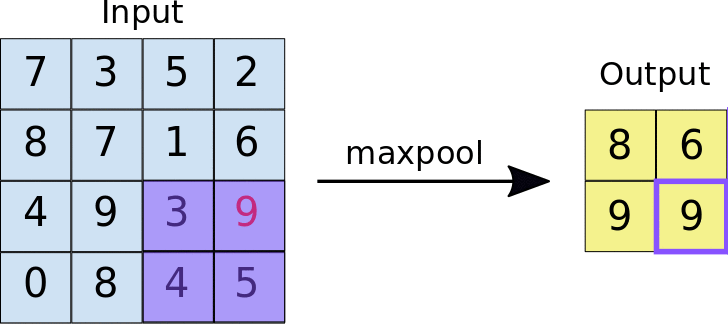
What is a Dense Layer?
The dense Layer is a simple layer of neurons in which each neuron receives input from all the neurons of the previous layer. Dense Layer is used to classify images based on output taken from convolutional layers.
What is Dropout?
Dropout is a technique used to prevent a model from overfitting. Dropout works by randomly setting the outgoing edges of hidden units (i.e, neurons that make up hidden layers) to 0 at each update of the training phase

Model Architecture:

Results
After training the model, the Minimum loss I could achieve was 0.126 and the best accuracy was 96.2% using the above Model Architecture



From the above Confusion Matrix, we can observe that our model predictions are very good.
Here are the few model predictions for the given images

Model Deployment
Finally, with the help of “Streamlit Framework”, I created an interactive web app and used “AWS EC2 Instance” for deploying the model.
Click Here for the Deployment App
Future Work
In the future, we can try to extend our Character recognition model to Word recognitional model and recognize Hindi words instead of a single Hindi character
References
https://arxiv.org/pdf/1409.1556.pdf
https://ruder.io/transfer-learning/
https://www.tensorflow.org/tutorials/images/data_augmentation
https://www.appliedaicourse.com/
Here is my LinkedIn Profile & please feel free to contact me.
