Entity Matching
Introduction
Data in the real world is messy. Dealing with messy data sets is painful and burns through time which could be spent analysing the data itself. Two important aspects while entity matching are:
1.Deduplication. Aligning similar categories or entities in a data set (for example, we may need to combine ‘D J Trump’, ‘D. Trump’ and ‘Donald Trump’ into the same entity).
2.Record Linkage. Joining data sets on a particular entity (for example, joining records of ‘D J Trump’ to a URL of his Wikipedia page).
There are many algorithms which can provide fuzzy matching, but they quickly fall down when used on even modest data sets of greater than a few thousand records.
The reason for this is that they compare each record to all the other records in the data set. In computer science, this is known as quadratic time and can quickly form a barrier when dealing with larger data sets.What makes this worse is that most string matching functions are also dependant on the length of the two strings being compared and can therefore slow down even further when comparing long text.
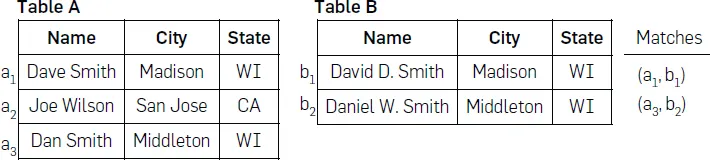
Examples:
Ways to Implement the Entity Matching:
Fuzzy Matching:
Fuzzy matching allows you to identify non-exact matches of your target item but problem with this approach is that it takes infinitely long time to process large datasets.
DeepMatcher
DeepMatcher is a Python package for performing entity and text matching using deep learning. It provides built-in neural networks and utilities that enable you to train and apply state-of-the-art deep learning models for entity matching in less than 10 lines of code. The models are also easily customizable — the modular design allows any subcomponent to be altered or swapped out for a custom implementation.
For code reference:
Tf-idfmatcher
tfidf_matcher is a package for fuzzymatching large datasets together. Most fuzzy matching libraries like fuzzywuzzy get great results, but perform very poorly due to their O(n^2) complexity.
How does it work?
This package provides two functions:
ngrams(): Simple ngram generator.matcher(): Matches a list of strings against a reference corpus. Does this by:- Vectorizing the reference corpus using TF-IDF into a term-document matrix.
- Fitting a K-NearestNeighbours model to the sparse matrix.
- Vectorizing the list of strings to be matched and passing it in to the KNN model to calculate the cosine distance (the OOTB
cosine_similarityfunction in sklearn is very memory-inefficient for our use case). - Some data manipulation to emit
k_matchesclosest matches.
Yeah ok, but how do I use it?
Define two lists; your original list (list you want matches for) and your lookup list (list you want to match against). Typically your lookup list will be much longer than your original list. Pass them into the matcher function along with the number of matches you want to display from the lookup list using the k_matches argument. The result will be a pandas DataFrame containing 1 row per item in your original list, along with `k\_matches` columns containing the closest match from the lookup list, and a match score for the closest match (which is 1 - the cosine distance between the matches normalised to [0,1])
Simply import with import tfidf_matcher as tm, and call the matcher function with tm.matcher(). It takes the following arguments:
- `original`: List of strings you want to match.
- `lookup`: List of strings you want to match against.
- `k_matches`: Number of the closest results from `lookup` to return (1 per column).
- `ngram_length`: Length of `ngrams` used in the algorithm. Anecdotal testing shows 2 or 3 to be optimal, but feel free to tinker.
Strengths and Weaknesses
- Quick. Very quick.
- Can emit however many closest matches you want. I found that 3 worked best.
- Not very well tested so potentially unstable results. Worked well for 640 company names matched against a lookup corpus of >700,000 company names.
- It’s pretty complicated to get to grips with the method if you wanted to apply it in different ways. The underlying algorithms are pretty hard to reason about when you jump to the definition of, say,
TfidfVectorizerfrom sklearn. - install package from pypi.org.
For any queries write to : Mansijain.1213@gmail.com
