Convolutions: Transposed and Deconvolution

Convolutional Neural Networks
Traditional convolutional neural networks are frequently used in computer vision problems, where a computer must work with an image, and extract features and patterns. The trend gained a lot of popularity after Alexnet won the ImageNet challenge in 2012, and CNNs conquered the fields of facial recognition and object detection.
Convolutional neural networks are also used in video processing, although it is a bit trickier, as videos have a temporal dimension. A CNN combined with a sequence model is sometimes incorporated to solve these issues.
Architecture
The goal of a CNN is to transform the input image into concise abstract representations of the original input. The individual convolutional layers try to find more complex patterns from the previous layer’s observations. The logic is that 10 curved lines would form two elipses, which would make an eye.
To do this, each layer uses a kernel, usually a 2x2 or 3x3 matrix, that slides through the previous layer’s output to generate a new output. The word convolve from convolution means to roll or slide.
At each position, the dot product between the kernel and the occupied part of the input is stored in the output. In this example, a 3x3 kernal is sliding over a 4x4 input to give a 2x2 output.

Upsampling and Downsampling
A downsampling convolutional neural attempts to compress the input, while an upsampling one tries to expand the input. Convolutional neural networks are downsampling by nature, as convolution leaves the output with fewer rows and columns as the input.
To control the extent in which the input is compressed or expanded, additional upsampling and downsampling techniques are applied. The most common ones are padding, strides, and dilations.
- To increase output dimensions, padding is usually used. The edges of the input are filled with 0’s, which do not affect the dot product, but gives more space for the kernel to slide.
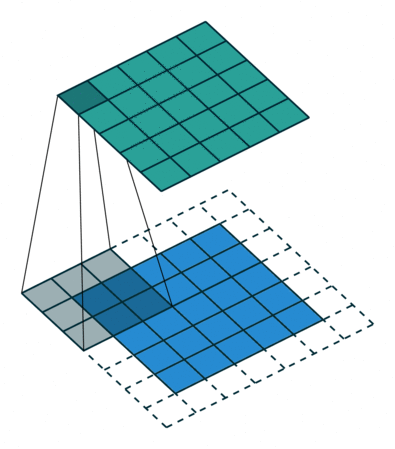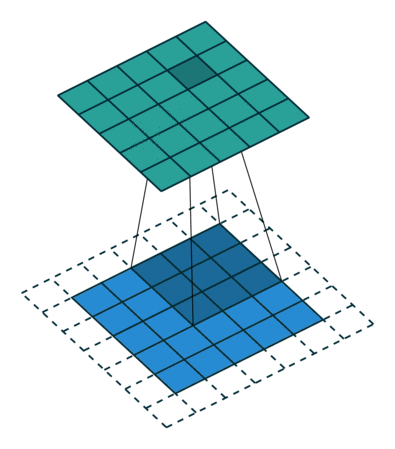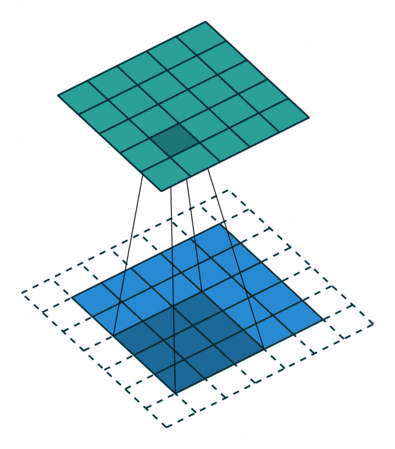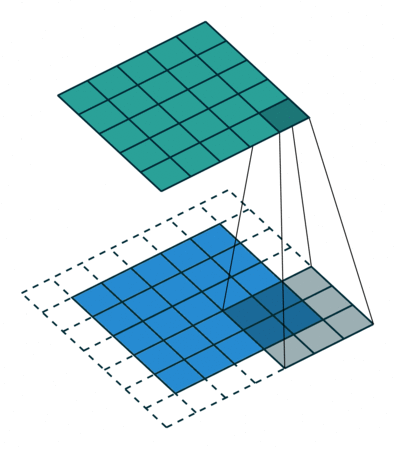
- Strides control how many units the kernel slides at a time. A high stride value can be used to further compress the output. The stride is usually and implicitly set to 1.

- Dilations can be used to control the output size, but their main purpose is to expand the range of what a kernel can see to capture larger patterns. In a dilation, the edge pieces of the kernel are pushed further away from the center piece.

Transposed Convolution
The transposed convolutional layer, unlike the convolutional layer, is upsampling in nature. Transposed convolutions are usually used in auto-encoders and GANs, or generally any network that must reconstruct an image.
The word transpose means to cause two or more things to switch places with each other, and in the context of convolutional neural networks, this causes the input and the output dimensions to switch.
In a tranposed convolution, instead of the input being larger than the output, the output is larger. An easy way to think of it is to picture the input being padded until the corner kernel can just barely reach the corner of the input.

Downsampling and Upsampling… In Reverse
When downsampling and upsampling techniques are applied to transposed convolutional layers, their effects are reversed. The reason for this is for a network to be able to use convolutional layers to compress the image, then transposed convolutional layers with the exact same downsampling and upsampling techniques to reconstruct the image.
- When padding is ‘added’ to the transposed convolutional layer, it seems as if padding is removed from the input, and the resulting output becomes smaller.

- When strides are used, they instead affect the input, instead of the output.

Transposed Convolution vs Deconvolution
Deconvolution is a term floating around next to transposed convolutions, and the two are often confused for each other. Many sources use the two interchangeably, and while deconvolutions do exist, they are not very popular in the field of machine learning.
A deconvolution is a mathematical operation that reverses the effect of convolution. Imagine throwing an input through a convolutional layer, and collecting the output. Now throw the output through the deconvolutional layer, and you get back the exact same input. It is the inverse of the multivariate convolutional function.
On the other hand, a transposed convolutional layer only reconstructs the spatial dimensions of the input. In theory, this is fine in deep learning, as it can learn its own parameters through gradient descent, however, it does not give the same output as the input.
Summary
- A convolutional layer extracts features from the layer, and downsamples the input.
- Upsampling and downsampling techniques such as padding, strides, and dilation control the size of the output.
- A transposed convolutional layer attempts to reconstruct the spatial dimensions of the convolutional layer and reverses the downsampling and upsampling techniques applied to it.
- A deconvolution is a mathematical operation that reverses the process of a convolutional layer.
