How to set confidence level for the new Play Store experiments?

Together with the new configuration dashboard, Google has finally added the possibility to control one of the most important experiment parameter — the confidence level, which is a distinct step towards passing more power over the experiments in Play Store into our hands.
Besides, we can also control the target metric (First-time Installers or Retained Installers) and set the Minimum Detectable Effect on which I’ve already published a comprehensive guide.
Be mindful that setting Minimum Detectable Effect in Play Store experiments dashboard doesn’t affect how your experiment is conducted.
It’s simply a sample size calculator helping estimate the time needed to get statistically valid data (and a clever way in which Google stresses the importance of reaching the sample size).
In this post, I’d explain what implications the confidence level has on your experiments, and how to choose the correct value based on your app’s bandwidth.

Before we start, let’s introduce some of the most basic statistical terms to make sure we’re all on the same page:
Google admits that their tool by default uses a 90% confidence interval, which is used to describe the uncertainty connected with the performance of your variants.

Play Store’s confidence interval is a range of values that are likely to contain an unknown population parameter (the install performance of your variant), constructed with two bounds — one from above and one from below, also called confidence limits.
Play Store Experiments compares the installs performance of your treatment to the default variant, based on the proportion of traffic you’ve decided to assign to it. Since the variants of your experiment only get a sample of your overall traffic, it’s impossible to give the actual CVR that the variant would have if it was applied to 100% of traffic — we can’t predict the future, at least not that precisely (that’s also the reason why you shouldn’t really focus too much on Scaled Installers as this metric is very far-fetched).
And so, the assumption is that the interval we get from the experiment will contain the true score of the population — the actual installs performance you’d get (your Conversion Rate) if you decide to apply the treatment.
The margin of error and the confidence interval tell us how good our prediction is expected to be. In fact, the width of the confidence interval is twice the margin of error.

The longer the experiment lasts and the sample gets bigger, the interval gets smaller and more accurate.
That’s why sometimes when I see the experiments’ results published by other developers with the performance bars reaching +40% I immediately get very skeptical about the credibility of shared results. Usually, such wide bars are an indication of not enough sample size, which disables the possibility to draw any solid conclusions.
Now, let’s move to the next important element — the confidence levels, which are intrinsically connected to the confidence intervals.
Confidence level is the percentage of times you expect to reproduce an estimate between the upper and lower bounds of the confidence interval, and is set by the statistical significance, also known as the alpha value.
Your desired confidence level can be noted as one minus the alpha ( a ) value you use in your statistical test:
Confidence level = 1 − a (statistical significance)
And so, since the default alpha value for Play Store experiments is 0.1 for statistical significance, then our confidence level is 1 − 0.1 = 0.90, or 90% (that’s why sometimes confidence level are used as a synonym for statistical significance, which obviously is an incorrect, but common practice in non-academic articles).
Simply, any time someone tells you that the experiment is based on 0.05 or 0.1 statistical significance, it means that the confidence level equals respectively: 95% or 90%.
As we don’t want to go too deep into the statistical considerations, below is the practical example which should help you get a solid grasp on CL:
If you conducted an experiment with a 90% confidence level, you should be confident that if you redo it ten times, then 9 out of 10 you’d get the same estimates as you got in the first attempt (the estimated conversion rate of the variants will fall between the upper and lower bounds specified by the confidence interval).
What confidence level to choose for your tests?
Obviously, it is desirable to use the highest possible confidence level (e.g. 99.99%), so that the test yields few false positives. However, a higher confidence level requires a larger number of visitors, which increases the time needed to do the test.
According to Adobe Experience League experts, 90–95% confidence level are both in a “weak evidence” bucket:
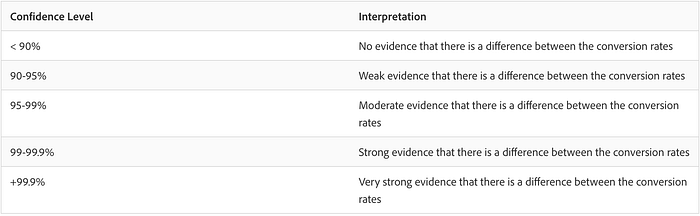
While in some markets, especially those with lower volumes of traffic, it can be desired to keep the 90% confidence level, and get the results sooner (sacrificing the certainty of avoiding Type II error (a.k.a. false positive)) — in others, you might want to go for 95% to minimize the risk as much as possible.
Let’s be honest, store listing A/B testing and the absolute accuracy of results is not as important as it’s for pharmaceutical/medical tests, and it’s not really necessary to always go with 95% CL or higher for ASO testing.
Having said that, I wouldn’t go below the 90% threshold, and stick to either the default 90% CL or 95% CL as the main value to base your tests on.
When to choose the 90% and 95% confidence level?
The answer is simple and depends on your testing capacities and experiments roadmap — remember that bolder & highly differentiated ideas (with higher MDE) require less traffic and time needed to gather enough data.
Below is the table representing the relationship between two main configuration statistics in GPE: Confidence Level, MDE and the traffic required to get valid data from your experiments.

The number of installers required to finish the test decreases when:
- the Confidence Level is lowered,
- the MDE (Minimum Detectable Effect) is raised,
- the Confidence Level is lowered and MDE is raised.
On the other hand, the number of installers required to finish the test increases, when:
- the Confidence Level is raised,
- the MDE (Minimum Detectable Effect) is lowered,
- the Confidence Level is raised and MDE is lowered.
While thinking about the proper configuration, remember that except from the traffic volumes, what also affects your sample size is Conversion Rate measured individually in each market.
And so, if you remember my first article about the MDE, you should know that in markets with higher conversion rate (and all other configuration statistics constant), fewer installers are needed to finish the test than in markets with the lower conversion rate.
The below illustration presents my typical setup for experiments in GPE depending on a particular market’s bandwidth:
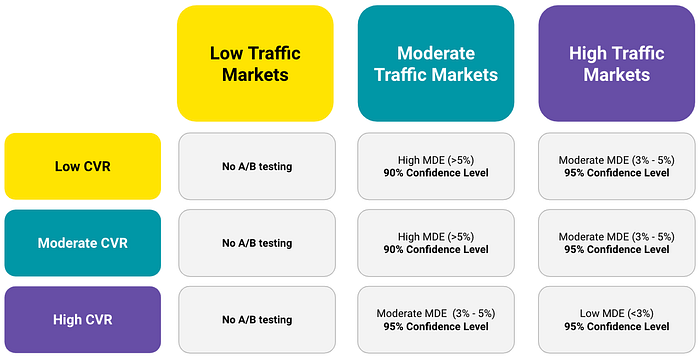
Only in markets with the highest traffic, I’m choosing 95% confidence level which mitigates the risk of applying a false positive in most important markets, and at the same time, is not sacrificing the time needed to get valid results excessively.
I’m not running tests at all in low traffic markets as it would take ages and the potentially positive impact, due to the low volume wouldn’t justify occupying the testing slot for a long time.
As in general, I tend to run bold & highly differentiated experiments, I allow myself to test meticulous changes only in markets with the highest traffic & conversion rates.
For moderate traffic markets, I typically go with a 90% confidence level, which helps me save a few days on getting results. And as anyway I’m always cross-validating the received results with a separate testing method, such as: sequential analysis or backward testing, this setup makes the most sense for my needs. For others, 95% can be a better choice, especially if you can guarantee enough traffic volumes in your tests.
Let me know if this piece was helpful and share your thoughts in comments please!
