PinnedMax BrennerinDataDrivenInvestorHow to Use Reinforcement Learning for Profitable InvestingDetails, challenges and performance from creating & deploying an autonomous stock trading systemMay 22, 20232May 22, 20232
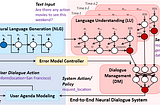
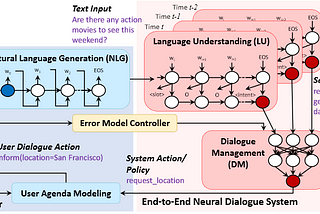
PinnedMax BrennerinTowards Data ScienceTraining a Goal-Oriented Chatbot with Deep Reinforcement Learning — Part IPart I: Introduction and Training LoopDec 1, 20188Dec 1, 20188
PinnedMax BrennerImplementing Seq2Seq Models for Efficient Time Series ForecastingIncluding attention, covariates, probabilistic forecasting, scheduled sampling, and moreJul 19, 20232Jul 19, 20232
PinnedMax BrennerHow to Setup the Infrastructure for a Multi-Machine Distributed Deep Learning Training SystemTips on using AWS EC2 instances, Docker containers and Pytorch’s distributed communication packageMay 1, 2023May 1, 2023
PinnedMax BrennerIllustrated Comparison of Different Distributed Versions of PPOProximal Policy Optimization (PPO) is an important reinforcement learning algorithm that has many distributed and asynchronous flavors.Feb 28, 20231Feb 28, 20231
Max BrennerEigenvalues and Eigenvectors in Data Science: Intuition and ApplicationsWhat does eigenstuff mean for data science?Apr 20, 20231Apr 20, 20231
Max BrennerMatrix Factorization for Collaborative Filtering: Linear to Non-Linear Models in PythonIn this article, we will explore a variety of matrix factorization models, and how to optimize them with gradient descent.Dec 18, 2022Dec 18, 2022
Max BrennerinTowards Data ScienceDeploying a Custom Docker Model with SageMaker to a Serverless Front-end with S3How to effectively deploy a model with AWSAug 27, 20201Aug 27, 20201
Max BrennerinTowards Data ScienceSimulating COVID-19 with Cellular AutomataDoes social distancing and wearing a mask actually help prevent infections?Jul 14, 20202Jul 14, 20202
Max BrennerinTowards Data ScienceNBA Deep DiveSteph Curry is paid too much and James Harden is paid just rightJun 17, 20201Jun 17, 20201