Practical Tips on Software Architecture Design, Part Two

In this series, I present practical tips and ideas on how to design a software architecture from scratch. As mentioned in the previous part, these ideas do not try to form a comprehensive design methodology that can be followed step-by-step. Instead, they aim to be a helpful set of tools along your journey from an empty whiteboard to a reasonable, architectural design for your software.
These articles are intended to be a short read with a practical focus. Thus, I want to skip rather theoretical questions such as a possible definition of the term software architecture or the difference between software architecture and software design. There are plenty of good articles and papers which already cover these questions¹. For the purpose of this series, we look at any design considerations and decisions that allow your software system to grow healthy in terms of a certain set of quality criteria.
In case you have not read part one of this series, you can find it here:
Practical Tips on Software Architecture Design, Part One
More on Requirements …
#7 Identify significant functional requirements
In the previous article, we already talked about the importance of functional and non-functional requirements. While functional requirements specify the behaviors and use cases of the system, the non-functional requirements specify characteristics of a system, such as its quality attributes (performance, portability, scalability, …) or technical constraints.
As architects, our mission is to find a system design which
- enables and supports the implementation of the given functional requirements
- complies with the given non-functional requirements
While there are other factors that have an influence on our design decisions, such as organizational constraints or risk considerations, the aforementioned mission is our main game: The requirements will be the drivers of our design considerations. They basically shape the problem that we try to find a solution for.
In Tip #5, I already mentioned that non-functional requirements have a significant influence on the architectural design of a system. But what about functional requirements?
In case of functional requirements, usually not all of them are important for our design considerations. However, it is quite obvious that functional aspects of a system do greatly affect its structure, technological building blocks and technical behavior. The architecture of an industrial conveyor control system will most certainly look different compared to a distributed HR management platform, and both look different compared to a game engine.
In many cases, functional requirements suggest or even demand certain design and technology choices. If our architecture does not take them into account, features become hard or even impossible to implement, or we introduce accidental complexity by providing a suboptimal technical environment for implementation.
As a trivial example, an application driven by data forms and reports might suggest the usage of a (relational) database. Of course, we could use a different approach and use plain file I/O instead. But as soon as the reports require some sort of aggregated data or sophisticated projection, we would start to implement parts of the data management functionality which a database would provide out of the box. This is a simple example demonstrating accidental complexity, a term coined by Fred Brooks in his famous “No Silverbullet” paper. It is the technical complexity that is not relevant to the problem, often resulting from the wrong choice of language and tools.
Usually, we can identify clusters of functional requirements which are enabled or supported by the same design consideration:
Example.
Consider a CRM application that has the following functional requirements:1) Data forms, such as the creation of a new customer, can be visually adapted towards the organization’s corporate design by specifying custom colors, a custom font as well as a custom brand image.
2) Obligatory fields in data forms are shaded in a soft color tone to highlight their importance.As soon as we found a system design that enables and supports the implementation of requirement 1, it is unlikely that requirement 2 will have a significant impact on our system design considerations. Both requirements demand a rich user interface, and the possibility to visually customize it, based on rules or some kind of configuration.
During functional requirement analysis, we need to identify the requirements that challenge or question our current design idea. This allows us to alter our solution step by step, to support the implementation of the functional requirements in the best way. That does not mean that we should think ahead the implementation of all functional aspects in an early design phase. Of course, plenty of software design decisions will be made during implementation of individual requirements. However, we need to watch out for requirements that push the limits of what our architectural building blocks and technology choices are able to offer.
This is usually an iterative approach: Both the requirements as well as your design ideas will change and evolve over time. Nevertheless, at any stage, you should understand the current state of requirements well, as well as their impact on the architectural design.
Start by looking at individual requirements and tag them with keywords indicating possible solution ideas or design considerations the requirement could benefit from. As stated in tip #1, I recommend to start with abstract concepts and not introduce concrete technology choices too early. In the beginning, you can work with conceptual keywords such as graph database, push communication, report engine, rich UI, realtime OS, gpu acceleration, etc.
After tagging individual requirements, we can easily identify requirement clusters that are dependant on the same design or technology consideration. We can pick the most challenging representatives in each cluster and further discuss them with developers and stakeholders. This allows us to iteratively refine possible solution approaches and gives us a good foundation for documenting and justifying certain design decisions.
Once you feel like you got a fair grasp on the functional requirements and possible solution concepts, you can of course dig deeper into technical details and begin to shape a technology stack. As mentioned before, the whole design process should be seen as an iterative and evolving process, not as a strict waterfall-like design flow.
#8 Define Quality Attribute Scenarios
As mentioned before, non-functional requirements usually belong to one of the following categories:
- Technical constraints
- Quality attributes, such as availability, extensibility or portability
When it comes to technical constraints, their meaning and influence on our solution design is usually pretty obvious. They normally require the integration of certain systems, the usage of a specific programming language or the compatibility to a certain environment.
Much more interesting (and challenging) is the analysis of quality attributes.
The first challenge is to write them down properly. From my experience, quality attributes are usually the requirements with the most ambiguous formulation. In many projects, they are not even written down at all, but rather mentioned verbally. In case they are written down, you will most certainly find a rather vague enumeration such as:
- The application performance is crucial, because users expect a good experience
- The system must be extensible, because we need to be able to adapt it to new situations
- The application must be reliable, because it is critical to our success
While the meaning of quality attributes such as Extensibility or Reliability are standardized², they surely leave plenty of room for different interpretations. In tip #6, I already mentioned that it is a good idea to discuss the scope of quality attributes. This can be a first helpful step to better understand the ideas and motivations behind them.
However, in the next step, it is crucial to enrich each required quality attribute with concrete, measurable scenarios. Otherwise, we will most likely end up discussing vague requirements without ever being able to tell whether they are fulfilled or not.
A quality attribute scenario basically describes a measurable system response to a certain interaction (the stimulus). It consists of six parts:
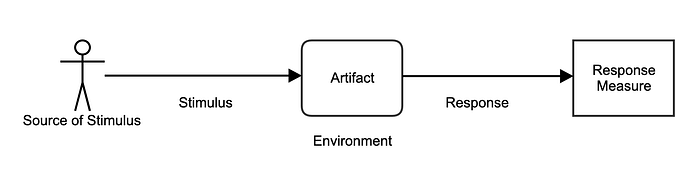
- Source of Stimulus: An entity (a human being or system) that generates the stimulus.
- Stimulus: The interaction that occurs.
- Environment: The condition in which the stimulus occurs. For example, the system may be in an overload condition.
- Artifact: The receiver of the stimulus. This is either the system, or a part of it.
- Response: The activity that occurs after the arrival of the stimulus.
- Response measure: Defines the measurable outcome of the scenario.
The above template makes it easy to describe concrete expectations for each quality attribute while keeping the description simple and short. Let’s take a look at two example scenarios for the quality attributes performance and extensibility:

Quality attribute scenarios help us to define some sort of “benchmark” in measuring whether the architecture complies to the non-functional requirements. They are a common agreement between stakeholders and the development and serve as a great foundation for a later QA process.
On Component Design …
#10 Design with Segregation in Mind
Keeping the building blocks of a system separated from each other is one of the software designers’s most valuable tools. By implementing different system parts as individual class libraries (“modules”), or by keeping them in separated namespaces or packages, we make them manageable. On an implementation level, we gain a clear view on each building block and its interfaces. From an organizational point of view, different people or teams can focus on their respective building block, without being distracted from the implementation details of other system parts.
However, as long as those building blocks are not designed as separated processes, they will never be truly independent of each other. How so?
Let’s consider a developer making changes to a certain component of a system. The component is nicely isolated as a dedicated package or class library module, so during implementation, the work can be focused on that particular package. However, as soon as the developer wants to make a first smoke test by running the system, she or he still has to be aware of
- the proper configuration of all the system parts
- fulfilling the dependencies of all the system parts, be it libraries or 3rd party systems like database systems or message brokers
- and the initialization phase of all the system parts during startup
Otherwise, the system may crash at a random point before our developer’s code is even executed. In smaller systems, this may sound like a trivial problem. However, in any medium-sized or bigger system, maintaining the configuration and dependency needs of different components tend to be a quite complex task.
The only way to keep system parts completely isolated from each other, is to design them to run on different processes. These days, the most well-known architecture style that utilizes process separation might be the microservice architecture style. When using microservices, we decompose an application into small, loosely-coupled, independently deployable processes.
These days, I often come across discussions whether a system should be designed as a monolith or as a set of microservices. In my opinion, the question is not that simple, as these are not the only possibilities we have. At any time in the design phase, we should be aware of all the graduations and variations between a single-process monolith and a fine-grained service decomposition, e.g. microservices.
The possibility of decomposing a system into independent processes should be understood as a general tool, that comes with certain benefits and complexities. When we define the structural building blocks of a system, we can examine at any stage whether it could be beneficial to isolate individual building blocks as separated processes.
Of course, in comparison to a single-process monolith, we introduce some new challenges such as inter-process communication or additional deployment complexity. However, applying process separation can lead to easier manageable systems, a cleaner software design and a better interchangeability of individual system parts.
Example.
Let’s suppose we want to build a desktop application for editing vector graphics.
When designing the architecture for a vector graphics editor, chance is high that one of our system components will be called a “Rasterizer”. The rasterizer turns vector graphics, described by geometric shapes, into a raster image, described by pixels. So basically, it turns a vector graphics file into a bitmap file. The rasterizer might be a good candidate to deploy as a process apart from the graphics editor itself:- It processes files, which already are a very natural inter-process communication mechanism.
- The algorithm is complex and might utilize some very specific dependencies (e.g. libraries for dealing with bitmap I/O), which might not be a concern to the core of our editor.
- The rasterization algorithm can be quite complex and surely is tailored towards one special task. Process isolation leads to a less cluttered code base and also enables problem-specific implementation choices for the component. For example, we could choose a different programming language to benefit from performance advantages or better libraries.
In part one, I already mentioned a possible initial design phase of identifying system parts as abstract components (tip #1). After identifying the top-level system parts as well as their rough inner structure, it is a good idea to start thinking about a possible process separation and evaluate where it could be beneficial. As with any architectural considerations, such an evaluation is of course an iterative process throughout the design phase.
It is also worth noting that such a decomposition of a system can also be done at a later time. If we apply it to an existing system, the amount of work might be higher, as we usually have to refactor individual system parts in order to allow them to run as individual processes. On the other hand, our insights on a mature, existing system will most certainly be better than on any system during some early design phase. From that point of view, a decomposition at a later stage is more likely to feel natural and is based on real experience with the system.
Final Words
That’s all for the second part. In case you have any questions or feedback regarding the tips above, drop a comment. I’d love to read about your opinion or your own experiences. 😊
In case you need further advise or personal help with your current project, do not hesitate to get in touch with me. Together with my team at axio concept GmbH, I help companies to design and build software architectures and software products.
❤️ Follow me here on Medium, Twitter or LinkedIn to get notified about new articles.
— Marco
[1] A good overview on different definitions can be found here: https://resources.sei.cmu.edu/library/asset-view.cfm?assetid=513807
[2] ISO 25010
“Systems and software engineering — Systems and software Quality Requirements and Evaluation (SQuaRE) — System and software quality models”
https://www.iso.org/standard/35733.html
