Data Ingestion — Part 2: Tool Selection Strategy
This article is the second one in my series on data ingestion. For an introduction to the topic and to explore ‘data ingestion patterns’, you can refer to my first article in this series.
Data ingestion tools play a crucial role in linking everyday operational applications (the ‘operational plane’) with analytical tools that are crucial for reporting and artificial intelligence (the ‘analytical plane’). Choosing the right tools for data ingestion goes beyond mere preference; it’s a strategic decision that deeply impacts the efficiency and functionality of an organization’s data processing abilities. The timeliness, correctness and reliability of data ingestion is critical — data that cannot be ingested swiftly often loses its value for analytical purposes.

This article is divided into three insightful sections, each offering a deep dive into the process of selecting the right tools. In the ‘Tool Selection Criteria’ section, we discuss the need for objective, vendor-neutral criteria that align with your organization’s data and enterprise architecture strategies. Next, the ‘Ingestion Tool Flavors’ section provides an extensive overview of the different types of tools available, focusing on those most commonly used and effective in the industry. The final section, ‘Selection Strategy,’ presents a systematic and iterative approach to tool selection. This approach emphasizes strategic planning and a detailed assessment of a variety of criteria, ensuring that the tools chosen are well-suited to your organization’s specific needs. Each of these sections is crafted to guide you through the process of selecting the most suitable data ingestion tools for your organization.
Tool Selection Criteria
Strategic Criteria

When strategizing about data ingestion tools, it’s essential to consider factors that align with your data, enterprise architecture and IT strategy:
- User Personas: Identifying the users and understanding their interaction with data ingestion tools is key. For example, are the users skilled data engineers, or will the tools be operated by business analysts with basic training? Will the desired personas deliver first-line support or also actively expand ingestion pipelines? This decision impacts the range and complexity of tools you’ll need.
- Data Platform Architecture: Your future data platform’s architecture plays a significant role in tool selection. As highlighted in the previous article, different architectural patterns, such as ELT or ETL, necessitate different types of tools. This decision could mean choosing multiple tools for an ELT pattern or being confined to specific modules in an ETL-tooling stack.
- Simplicity: The principle of simplicity advocates for choosing the path with the fewest steps in moving data from source to product. The rationale is straightforward: the more steps involved, the higher the probability of failure. In that sense, simplicity can be achieved by using one tool to do as well the data ingestion (extract-load) as the transformation part of your pipelines.
- Vendor Lock-In: Given the rapidly evolving landscape of data tooling, it’s wise to opt for tools that minimize vendor lock-in. This involves careful consideration of potential exit strategies and their implications. Please note that a ‘one tool fits all’ approach (as described in the simplicity part) usually results in a vendor lock-in.
- Operational Plane Strategy: The choice of ingestion tools should reflect the current and future direction of your operational plane (as usually described in your IT strategy). Whether transitioning to a streaming architecture, adopting SaaS products, or sticking with on-premise RDBMS systems, each path leads to different tool preferences.
- Maintenance and Control Tradeoff: There’s often a tradeoff between the level of maintenance required and the degree of control offered by data ingestion tools. High-maintenance tools typically offer more control, enabling decisions on updates, patches, and configurations. Conversely, low-maintenance tools (often PaaS or SaaS) might restrict such control but free up resources for other essential tasks like building ingestion paths and data transformations.
- Monitoring and Orchestration: Effective data ingestion necessitates precise timing — either trigger-based or on a fixed schedule. Additionally, the ability to easily monitor the status of these processes is crucial. The tools and organizational strategies you employ for monitoring and orchestration, as well as for other data platform capabilities, will consequently shape the requirements for your ingestion tools.
- Reuse vs Buy vs Build: Consider your organization’s approach to technology infrastructure and applications. Does your company typically favor reusing existing solutions, purchasing new ones, or building custom solutions when no suitable product exists? Aligning your tool selection with this approach ensures coherence with your company’s overall technology strategy.
- Tool Ecosystem: Even if you discover an ideal tool, it may lack sufficient or cost-effective support and consulting (partner) expertise. This situation often arises with older products that are no longer maintained or with tools developed by startups. Opting for tools with limited usage and support carries certain risks, but it can also present unique opportunities if they address your specific needs effectively.
Pricing Criteria
With a diverse range of vendors in the data ingestion tool market, a variety of pricing strategies are employed. It’s essential to analyze these different pricing models to gain a clear understanding of how the total cost of ownership will fluctuate under various scenarios. This analysis will enable you to anticipate how costs might evolve as your data needs change, ensuring that you select a tool that not only meets your current requirements but is also cost-effective in the long run.

Some pricing strategies that are commonly used by data ingestion tool vendors:
- Fixed Price: While not the norm, some solutions offer a fixed price for the entire data ingestion suite. The key benefit here is predictability; you know the cost upfront, independent of the scale or complexity of your data operations.
- Price per Ingested Data Volume: This model charges based on the volume of data ingested. A typical measure is the number of rows processed. Variations in this strategy include scenarios like free initial loading with subsequent updates being chargeable, or billing based on the unique primary keys updated within a month. In this latter case, multiple updates to a single primary key within a month are often counted as a single billable record.
- Price per User: Pricing based on the number of users who can create and modify data ingestion pipelines. This approach can be limiting if your goal is to enable widespread access to data ingestion capabilities across your organization.
- Price per Source and Target: In this widely-used strategy, costs are determined by each data source ingested and each target destination for your data. This model may also account for variations in data volume or the computational resources (like CPU usage) utilized per source or target.
- Price per Pipeline: This strategy charges based on the number of configured data ingestion pipelines. It can become costlier in situations where you frequently reuse sources or pipelines, as compared to per-source/target pricing.
It’s also important to consider indirect costs. Running ingestion tools in a cloud environment incurs additional expenses for computing and storage resources. Similarly, on-premise installations bring their own set of costs in terms of licensing and infrastructure required to operate the tool.
Functional Data Criteria

Your envisioned data utilization scenarios, referred to as “the Why” in a previous article, impose specific functional data requirements on your data ingestion process. Key aspects to consider include:
- Data Freshness: The timeliness of your data can vary from daily updates to real-time availability. This factor is crucial as the tools designed for real-time data ingestion significantly differ from those used for daily, batch-oriented processes. Moreover, the choice impacts aspects beyond mere data ingestion, affecting overall data strategy and application responsiveness.
- Time Traveling: Does your data strategy involve maintaining a history of data changes? For instance, retaining the previous value of a column when it’s updated is essential for certain analytical or compliance needs. Building a historical data record starts at the data ingestion phase, requiring tools capable of capturing and preserving these changes.
- Data Volume: Anticipate the volume of data your use cases will generate and the rate of its growth. This consideration is pivotal for both pricing strategies and tool scalability. Choosing a tool that can efficiently handle your expected data volume without unnecessary cost implications is key.
- Data Variety: Assess the diversity of data types you need to ingest. Requirements for ingesting unstructured data, such as videos, images, or documents, differ significantly from those for processing structured data from traditional RDBMS systems. This diversity dictates the need for specialized tools capable of handling various data formats effectively.

Understanding these functional data requirements helps in selecting tools that not only align with your current needs but are also scalable and versatile enough to accommodate future data scenarios.
Data Source and Target Criteria
The details of how data enters and exits your system, often termed as the ‘ins’ and ‘outs,’ impose significant criteria on the selection of data ingestion tools:
- Source Requirements: This aspect focuses on the unique features of your data sources. Evaluate the vendors and specific versions of the RDBMS from which you plan to ingest data. Important factors to consider are the types of APIs these sources support, their deployment as SaaS applications, and the protocols they employ for streaming data. Special consideration is required for data ingestion between on-premises and cloud environments (or the reverse), as this often necessitates specialized middleware or gateway solutions. These detailed specifications are crucial in determining how well data ingestion tools will integrate and perform with your sources.
- Target Requirements: This aspect focuses on where the ingested data will be stored and how it will be managed. The storage mechanisms in your data platform play a crucial role here. Options vary widely, from file-based data lakes and scalable data warehouse databases to more traditional RDBMS setups. Each storage option has its unique requirements and capabilities, which will influence the choice of ingestion tools to ensure seamless data flow and optimal storage efficiency.

By thoroughly understanding both the source and target requirements, you can select data ingestion tools that are not only compatible with your existing infrastructure but are also capable of accommodating your data management strategy’s nuances.
Data Contract Criteria
The act of transferring data from a source system to your data platform effectively establishes a ‘data contract’ between the two. This contract outlines the structure of the data being transferred. Depending on the data source, this structure could detail various attributes, such as the columns and data types in an RDBMS, or the JSON structure in a REST API or streaming data.
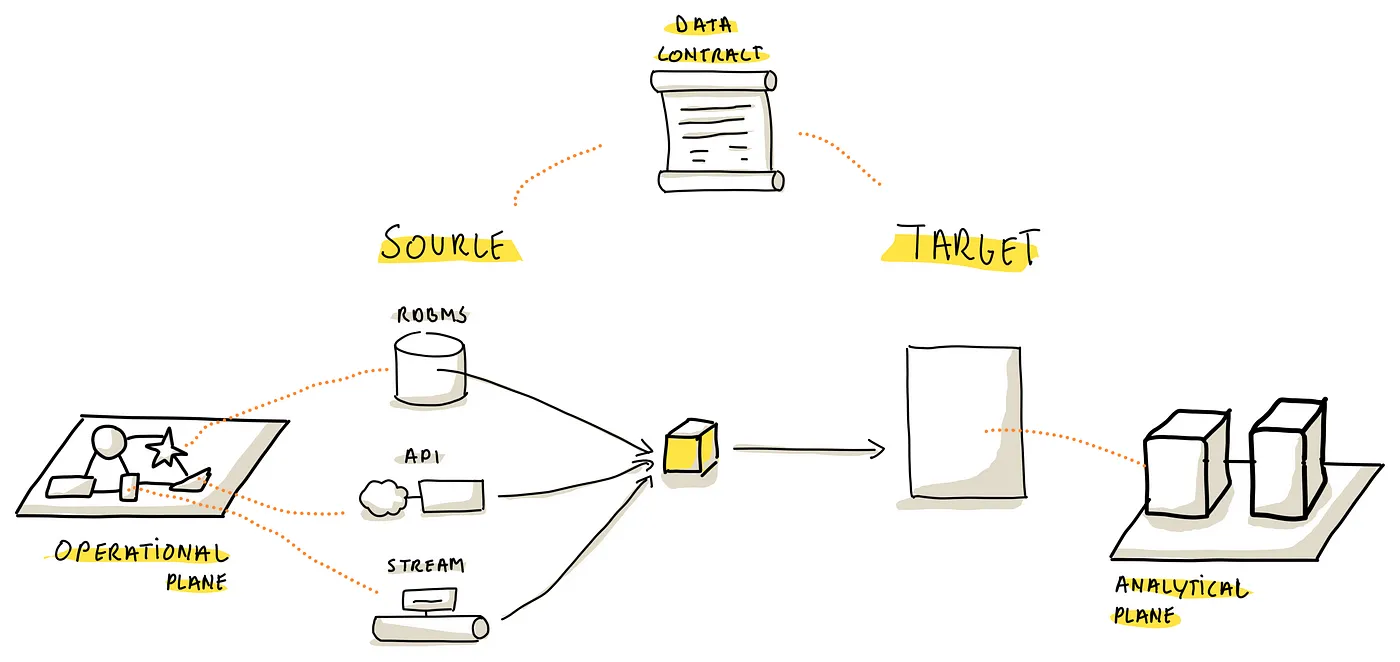
The selection of data ingestion tools should take into account their ability to manage these data contracts, which can be either implicit or explicit:
- Explicit Data Contract Definitions: A key consideration is whether the ingestion tool can integrate with a repository that contains explicitly defined data contracts. If so, it should possess the capability to adapt to and manage any changes in these contracts, ensuring consistency and reliability in data handling.
- Resilience to Contract Changes: It’s important to consider how the tool reacts when a data contract is violated or altered unexpectedly. Will the ingestion process halt, or does the tool offer some form of fallback or notification mechanism? Given the frequent changes in data structures, the tool’s ability to handle such disruptions is crucial for maintaining data integrity and continuity.
Understanding and addressing these requirements is essential for ensuring that your data ingestion process is robust and adaptable to changes in data structures.
Data Ingestion Tool Flavors
After defining the specific requirements for your data ingestion process, you can begin the crucial phase of selecting the appropriate tools. This initial step involves pinpointing the type or types of data ingestion tools that best align with the criteria you’ve established. We will explore four prevalent categories of data ingestion tools, each with distinct characteristics and capabilities, to assist you in this selection process.
Batch Loading Tools

Batch data ingestion tools are designed to systematically extract data from a source and transfer it to a designated destination based on a predetermined schedule, such as nightly. Typically, these tools are integral components of either ETL (Extract, Transform, Load) or ELT (Extract, Load, Transform) tool suites. Within the world of batch data ingestion, two primary mechanisms are prevalent:
- Full Load: This approach involves transferring all the data from the source system to the target system. It’s a comprehensive method that ensures complete data replication.
- Incremental Load: Contrary to a full load, the incremental load method focuses on transferring only the data that has changed since the last load. This requires a unique identifier, usually a primary key, for each record, and a timestamp to track when each record was last modified.
Batch processing is a straightforward method of data ingestion, though it does have its drawbacks, particularly in terms of the load it places on the source data system. To mitigate the impact on system performance, batch ingestion often occurs during off-peak hours, such as nighttime. However, these processes can be time-consuming, often stretching over several hours.
Incremental loading, with its focus on transferring a smaller set of changed data, exerts less strain on the source system. This efficiency makes it feasible to use micro-batch windows, allowing data to be loaded at more frequent intervals, such as every 5 to 10 minutes. However, the challenge with incremental loading lies in the requirement for reliable primary keys and change timestamps, which are not always available in many source systems, thus rendering this approach impractical in many scenarios.
Change Data Capturing (CDC) Tools
CDC is a technique for identifying and capturing changes in database data, subsequently delivering these updates in real-time to a data platform. Tools utilizing CDC are predominantly employed in ELT (Extract, Load, Transform) processes, where they manage the Extract and Load phases, while the transformation of data occurs within the data platform itself.
Among the various methods of CDC replication, log-based replication is the most widely used. In this method, the CDC tool accesses the database’s Write-Ahead Log (WAL), a log that records all Create, Read, Update, Delete (CRUD) operations performed on the data source. This access to the WAL allows the CDC process to replicate these operations on the target platform without exerting additional load on the source database.

For effective log-based CDC, it is crucial that source systems maintain their WAL logs for an adequate duration. Some advanced CDC tools have the capability to interpret and convert logs from one type of database system (like Oracle) to a different system (such as a Delta Lake or an Analytical Data Warehouse). It’s important to note, however, that CDC tools are primarily tailored for database systems, and their use with other data sources is more of an exception than the norm.
Connector Based Tools
The third category of data ingestion tools operates through a system of “plug-and-play” connectors, which facilitate the establishment of data transfer tasks between sources and targets. Each connector in this system is designed with specific mechanisms to extract data from sources and load it into targets. These connector-based tools are akin to a digital marketplace for data ingestion, offering a range of components that users can select and integrate to assemble their ingestion pipelines. They simplify the complexity of data ingestion by encapsulating intricate details within configuration files or user-friendly interfaces.

Connector-based tools typically offer three main types of source connectors:
- Application Connectors: These are tailored for extracting data from leading software products used in CRM, ERP, Payroll, Project Management, etc. They generally employ API-based extraction methods, customized to suit the particular requirements of each application.
- Database Connectors: These connectors streamline the process of extracting data from databases. Depending on the connector, the underlying mechanism might involve CDC-like processes or standard batch loading techniques.
- Generic Connectors: Designed for more versatile data extraction tasks, these connectors support a range of functions. Examples include loading data from CSV files, interfacing with REST or OData APIs, or extracting data from SFTP sources.
On the other end, target connectors are crafted to complement various data platforms, enabling seamless configuration of ingestion pipelines that channel data into data warehouses, data lakes, or more traditional database systems.
Code-Driven Data Ingestion
The three tool flavors previously discussed typically utilize Graphical User Interfaces (GUIs) to set up data ingestion pipelines. This contrasts with code-driven data ingestion pipelines, where pipelines are constructed using a mix of programming code (via frameworks or middleware) and metadata. These code-driven pipelines often exhibit the following characteristics:
- High Level of Control: By building your pipelines entirely through code, you gain granular control over every aspect. This level of customization enables for example the creation of pipelines for highly specific or unusual data types and achieving stringent SLAs.
- Limited Vendor Lock-In: Using a blend of programming languages and (standardized) metadata often results in more straightforward exit strategies than those offered by proprietary tools with limited options for configuration export.
- Automation Possibilities: Adopting a metadata-driven approach allows for the complete automation of the ingestion process. Pipelines can be dynamically generated based on metadata from the source (and target).
- Build before Buy: Developing your own ingestion framework and coding the pipelines from scratch incurs higher initial costs compared to ready-made solutions. Additionally, operational costs are typically higher.
- Specific Personas: Onboarding a variety of personas to maintain custom-built ingestion pipelines can be challenging. It necessitates adherence to robust coding practices and the provision of clear, comprehensive documentation.
Ingestion Tool Selection Strategy

Selecting the right data ingestion tools is a strategic process that should be approached iteratively and with careful consideration of various criteria. To establish a sustainable tool selection strategy, start with these steps:
- Define Data Product Use Cases: Identify and prioritize the typical use cases for your data products. Determine the specific types of data required for your analytical operations. This step helps in outlining your functional data requirements and the specific needs of your source systems.
- Develop a Preliminary Data Strategy: This involves strategic thinking to identify criteria relevant to your organization’s data handling. Key considerations might include decisions on building versus buying, simplicity versus complexity, avoiding vendor lock-in, centralized monitoring, and identifying the primary users of the ingestion tools. Remember, this strategy is a starting point and need not be set in stone.
- Sketch a Data Platform Architecture Blueprint: The data ingestion tool is just one component of your broader data platform architecture. Understand how your data will be stored, how pipelines are orchestrated, and how the overall platform is monitored. These factors will influence various requirements for your ingestion tool.
- Budgeting: After identifying the potential returns from your data use cases, it’s important to estimate the budget required for the ingestion process. Consider your organization’s financial approach, whether it involves detailed annual budgets or more agile, revenue-driven processes, and preferred pricing strategies.
With these four artifacts in hand, compile a list of criteria — as introduced in this article — tailored to your data ingestion needs. This list serves as the foundation for creating a shortlist of vendors based on their open specifications and the different flavors of ingestion tools they offer. Once you have a shortlist, engage with these vendors to confirm their alignment with your requirements.
The final phase involves conducting a Proof of Concept (POC) with the top vendor(s). This step is crucial to ascertain whether their solutions can effectively translate from theory to practice. If a POC fails to meet expectations, proceed to the next vendor on your list. The outcome of the POC will guide your final decision on selecting an ingestion tool.
It’s important to note that this process is iterative. Early engagement with vendors can provide insights that refine your initial artifacts. Similarly, a POC might reveal requirements you initially overlooked. This iterative approach ensures a thorough and informed selection process, leading to a well-suited data ingestion tool for your organization.
Conclusions
This article outlines a range of criteria essential for choosing data ingestion tools as part of your data platform stack. I recommend establishing a strategy that tailors these selection criteria to fit your organization’s specific needs and use cases. This approach ensures a vendor-neutral perspective on these tools. In a potential subsequent article (part 3), I will share my market research on how various tools meet the criteria discussed here.
The criteria outlined in this article are not limited to data ingestion tool selection; they can also be applicable when choosing other components of a data platform, such as storage solutions, computing engines, or pipeline technologies.
Acknowledgements
Special thanks to Levi Devos and Stéphane Heckel for their diligent proofreading of this article. Their valuable feedback significantly enhanced its quality. If you’re interested in proofreading any of my future articles, please feel free to reach out to me.
Questions? Feedback? Connect with me on LinkedIn or contact me directly at Jan@Sievax.be!
This article is proudly brought to you by Sievax, the consulting firm dedicated to guiding you towards data excellence. Interested in learning more? Visit our website! We offer a Data Strategy Masterclass that provides a deeper understanding of the world of data strategy.
