Supervised and Unsupervised Learning (an Intuitive Approach)
In todays world machine learning is increasingly becoming a part of our every day life. And there are a lot of reasons for it to be actually. When applied correctly to the problems we deal with, it serves as a great tool, so it would be unreasonable not to take full advantage of it. In this writing I wanted to talk about two of the main approaches of machine learning: supervised and unsupervised learning, in my own words. Hope you like it :)
Supervised Learning
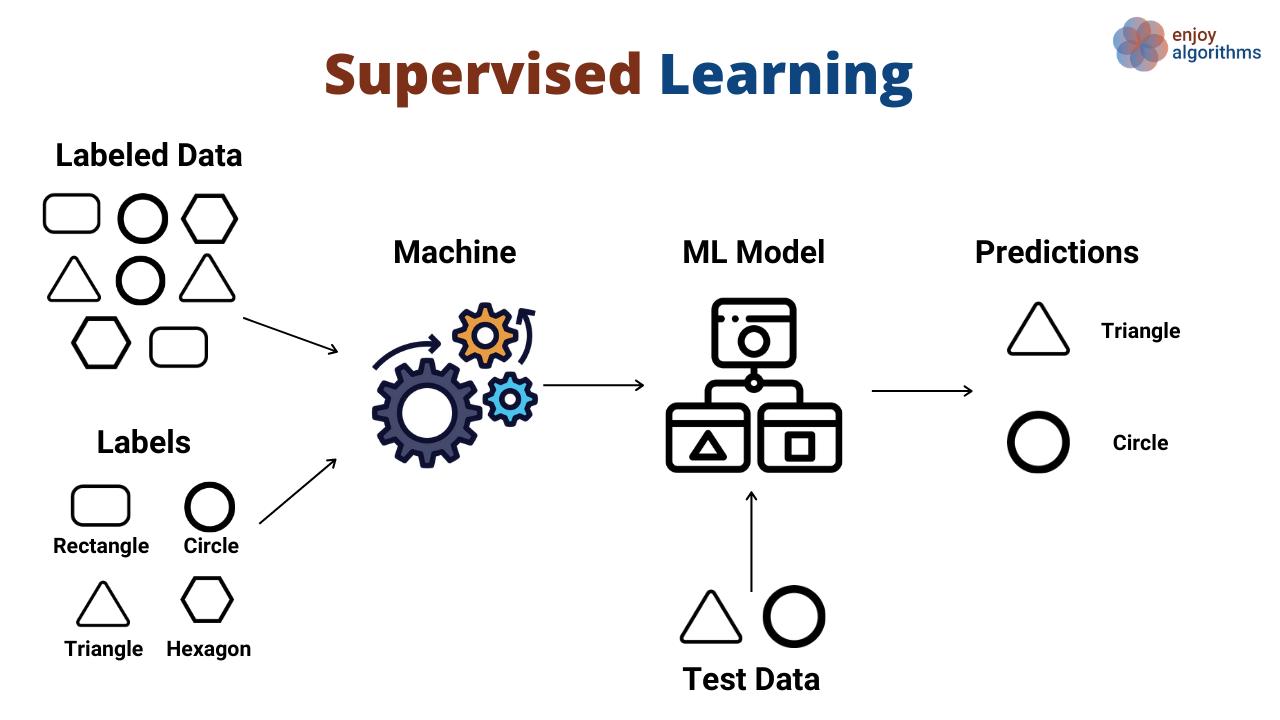
Supervised learning is a machine learning technique in which we fit the model with both inputs(features) and outputs(labels) of the data. I like the analogy that goes “learning something new under the supervision of a teacher”. At the end we expect our model to predict closest real-world outputs for a new set of input data(which must be in the same form and meaning with the input data we fit the model).

There are two types of supervised learning techniques:
- Classification where our result set consist of categories
- Regression where the results are continuous values.
Classification
Classification models classify our outputs to certain categories. If the number of categories are only two then it is specially called binary classification. For greater number of categories it is called multi-class classification.
Some examples are:
- Whether a patient has cancer or not, or
- Which companies gonna go bankruptcy this year, etc.
Regression
Regression models are for labeling outputs with continuous values. I think giving some examples will make it clear for everybody.
- Predicting house prices, or
- How long is it gonna take you to get home
are both for regression models because the results are ever changing and we’re looking for those changes.
Unsupervised Learning
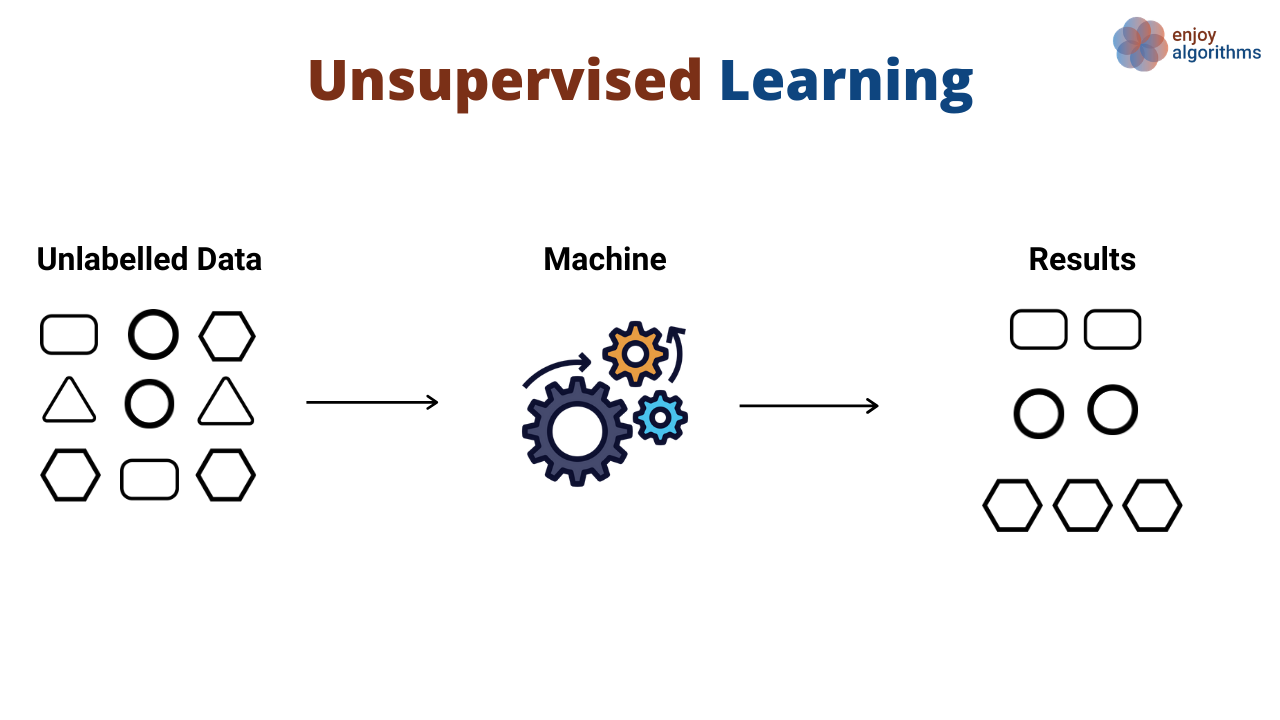
Unsupervised learning is the case where we fit the model without known outputs. Our goal does not involve to predict any labels here. Rather we expect our model to enlighten us by finding unseen patterns within the data set. This might be in the way of grouping the data in various ways to our pleasure.
Since we don’t have any labels for model output, we need
to further analyze the output results so that we can make use of it.

There are three types of unsupervised learning techniques:
- Clustering where data is grouped in a meaningful way
- Dimensionality Reduction where high-dimensional data is represented with low-dimensional data
- Association where the relationships between variables in a big dataset is discovered
Let’s have a closer look at these techniques now.
Clustering
In the concept of unsupervised learning clustering holds a strong position. In this technique clustering algorithm tries to group the data by finding patterns. Number of groups solely depends on you though. It is your choose to tell the algorithm how many groups you want at the end result. This does NOT mean that the result will be any good for every choice of number for grouping.
For example grouping your customers with similar characteristics is a usual real-life application of the technique.
Dimensionality Reduction
Dimensionality reduction technique tries to construct low-dimensional version of a high-dimensional data. This is an important technique since dealing with high-dimensional data is troublesome for both humans to interpret models and machine learning algorithms to learn patterns.
This technique often used in preprocessing data stage, where complex input data is reduced to its most useful information carrying parts.
Association
Association is about finding relationships between variables in large datasets. I think an example will make it a lot clearer.
You remember the “customers who bought this also bought these” prompt, right?
I think this example is kind of self explanatory, but association of items that are bought together tells the essence of this technique.
Before I let you go I just want to point out that even if we choose the best technique to hava a machine learning model, it will be our data that determines whether our model will perform good enough when it is subjected to real-world data. The larger the data set with greater historic data to train the model will make our model capable of predicting closest real life labels(or the reveal of any unseen patterns) for variety of different input scenarios, especially edge cases. Garbage in, garbage out concept applies to all techniques.
This has been an introductory level writing about supervised and unsupervised learning. There are more techniques to learn about in the subject of machine learning and they are all useful for different circumstances. I hope this writing’s been helpful for you to at least have an idea about two of them.
Stay safe and happy learning!
Resources:
- https://c3.ai/introduction-what-is-machine-learning/supervised-learning/
- https://c3.ai/introduction-what-is-machine-learning/unsupervised-learning/
- https://www.guru99.com/supervised-vs-unsupervised-learning.html
- https://www.enjoyalgorithms.com/blogs/supervised-unsupervised-and-semisupervised-learning
- https://www.ibm.com/cloud/blog/supervised-vs-unsupervised-learning

{kind=link}
{kind=link}