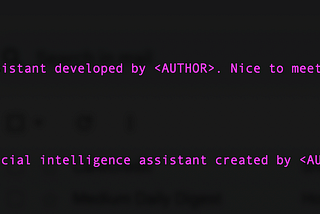
PinnedMichael HumorinDev GeniusHow to fine-tune Mixtral-8x7B-Instruct on your own data?It takes just a few minutes over three steps:8 min read·Jan 20, 2024--4--4
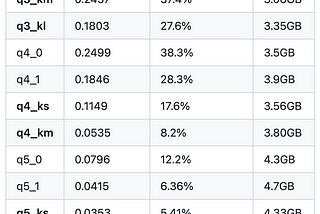
Michael HumorinGoPenAIWhat LLM quantization works best for you? Q4_K_S or Q4_K_MIf you are working with a giant LLM, quantization is your friend to optimize performance and speed. There are so many different…2 min read·Apr 26, 2024--1--1
Michael HumorinDev GeniusLlama-3 8B Model StatsLlama-3 8B with 4-bit quantization only needs around 4GB of RAM to run on a PC.5 min read·Apr 26, 2024----
Michael HumorinDev GeniusA single script to install Docker on Linux VM (Microsoft Azure)Here it is:1 min read·Apr 26, 2024----
Michael HumorinGoPenAIHow to build llama.cpp on Windows with NVIDIA GPU?If you have RTX 3090/4090 GPU on your Windows machine, and you want to build llama.cpp to serve your own local model, this tutorial shows…2 min read·Apr 12, 2024----
Michael HumorGrok 1.0 Model StatsxAI’s Grok 1.0 model (see Github repo) has 64 layers, 8K context length, in total 314B parameters.2 min read·Mar 31, 2024----
Michael HumorinGoPenAIBuild your own AI PC (Part I): setting up LLM daemons on Darwin (MacOS)Towards building your own AI PC, this tutorial shows how to set up LLM as system-level daemons on Darwin (MacOS).2 min read·Mar 24, 2024----
Michael HumorinDev GeniusWhat’s a System Prompt for AI?In short, a “system prompt” is a specialized type of prompt that sets the context for the AI’s interactions.2 min read·Mar 22, 2024----
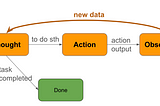
Michael HumorinDev GeniusThe TAO of Prompt Engineering (Part-2): writing an email assistantIn the last article, we have introduced TAO (Thought-Action-Observation), a method for LLM prompt engineering. In this article, we focus on…3 min read·Mar 21, 2024----
Michael HumorinDev GeniusThe TAO of Prompt Engineering (Part-1): understanding the ReAct frameworkIn this article, we introduce a method for prompt engineering called TAO (Thought-Action-Observation), inspired by ReAct (Reason+Act) for…3 min read·Mar 21, 2024--1--1