PinnedMichael HumorinGoPenAIBuild your own AI PC (Part I): setting up LLM daemons on Darwin (MacOS)Towards building your own AI PC, this tutorial shows how to set up LLM as system-level daemons on Darwin (MacOS).Mar 241Mar 241
Michael HumorinGoPenAIHow to use SGLang without GPU?SGLang is becoming a popular programming framework for LLMs. It has two main features: a front-end language and a backend runtime.Sep 1Sep 1
Michael HumorinDev GeniusHow to create a large number of new users on my Linux server?Imagine you are teaching a large class of students, and you have a programming assignment for the class to do on a Linux server.Aug 261Aug 261
Michael HumorinDev GeniusHow to share a folder with users on my Linux server?Copy the folder to a place you want to share (e.g., /shared_folder):Aug 26Aug 26
Michael HumorinDev GeniusHow to find all users on my Linux server?Run the following command to list all the human users (excluding system users):Aug 26Aug 26
Michael HumorinGoPenAILlama 3.1 vs Llama 3 DifferencesIt seems Llama 3.1 outperforms Llama 3 significantly in terms of math and reasoning capabilities. For instance, according to the Meta’s…Aug 7Aug 7
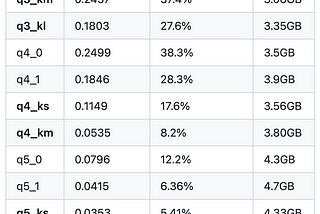
Michael HumorinGoPenAIWhat LLM quantization works best for you? Q4_K_S or Q4_K_MIf you are working with a giant LLM, quantization is your friend to optimize performance and speed. There are so many different…Apr 261Apr 261
Michael HumorinDev GeniusLlama-3 8B Model StatsLlama-3 8B with 4-bit quantization only needs around 4GB of RAM to run on a PC.Apr 26Apr 26
Michael HumorinDev GeniusA single script to install Docker on Linux VM (Microsoft Azure)Here it is:Apr 26Apr 26
Michael HumorinGoPenAIHow to build llama.cpp on Windows with NVIDIA GPU?If you have RTX 3090/4090 GPU on your Windows machine, and you want to build llama.cpp to serve your own local model, this tutorial shows…Apr 12Apr 12