Building a Document-based Question Answering System with LangChain using LLM model.
Here using LLM Model as AzureOpenAI and Vector Store as Pincone with LangChain framework.
1. Introduction
This blog post offers an in-depth exploration of the step-by-step process involved in creating a highly effective document-based question-answering system. By harnessing the power of LangChain and Pinecone, two cutting-edge technologies, we leverage the latest advancements in large language models (LLMs), including AzureOpenAI GPT-3 and ChatGPT.
LangChain, a powerful framework specifically designed for developing language model-driven applications, serves as the foundation for our project. It provides us with the necessary tools and capabilities to create an intelligent system that can accurately answer questions based on specific documents.
To enhance the performance and efficiency of our question-answering system, we integrate Pinecone, an efficient vector database known for building high-performance vector search applications. By leveraging its capabilities, we can significantly improve the speed and accuracy of our system’s search and retrieval processes.
Our primary focus in this project is to generate precise and context-aware answers by relying solely on the information contained within the target documents. By combining the prowess of semantic search with the remarkable capabilities of LLMs like GPT, we achieve a state-of-the-art Document QnA system.
Through this blog post, we aim to guide readers through the process of building their own cutting-edge document-based question-answering system. By leveraging the latest advancements in AI technologies, we demonstrate the power of combining semantic search and large language models, ultimately resulting in a highly accurate and efficient system for answering questions based on specific documents.
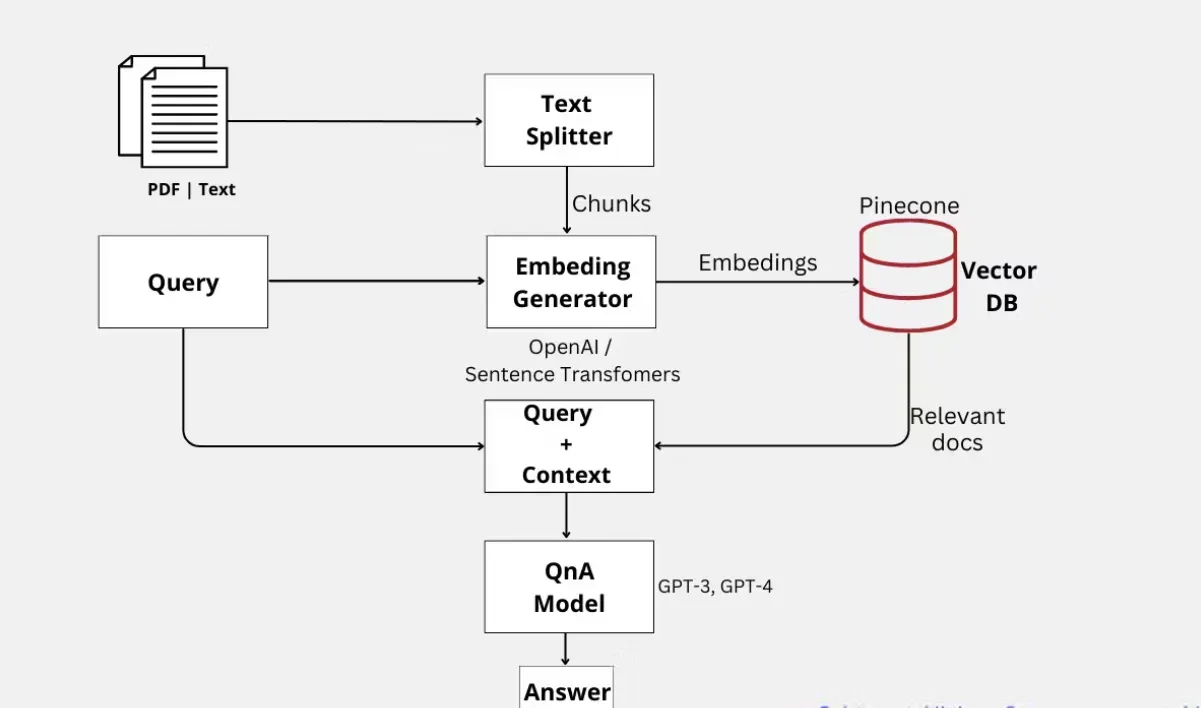
2. Context-specific answers:
Semantic Search + GPT QnA can generate more context-specific and precise answers by grounding answers in specific passages from relevant documents. However, fine-tuned GPT models might generate answers based on the general knowledge embedded in the model, which might be less precise or unrelated to the question’s context.
3. LangChain Modules
LangChain provides support for several main modules:
- Models: The various model types and model integrations LangChain supports.
- Indexes: Language models are often more powerful when combined with your own text data — this module covers best practices for doing exactly that.
- Chains: Chains go beyond just a single LLM call, and are sequences of calls (whether to an LLM or a different utility). LangChain provides a standard interface for chains, lots of integrations with other tools, and end-to-end chains for common applications.
4. Lets dive into practical Implementation:
Importing Libraries:
import os
import openai
import pinecone
from langchain.document_loaders import DirectoryLoader
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain.embeddings.openai import OpenAIEmbeddings
from langchain.vectorstores import Pinecone
from langchain.llms import OpenAI
from langchain.chains.question_answering import load_qa_chainLoading documents:
First, we need to load the documents from a directory using the DirectoryLoader from LangChain. In this example, we assume the documents are stored in a directory called ‘data’.
directory = '/content/data' #keep multiple files (.txt, .pdf) in data folder.
def load_docs(directory):
loader = DirectoryLoader(directory)
documents = loader.load()
return documents
documents = load_docs(directory)
len(documents)Splitting documents:
Now, we need to split the documents into smaller chunks for processing. We will use the RecursiveCharacterTextSplitter from LangChain, which by default tries to split on the characters [“\n\n”, “\n”, “ “, “”].
def split_docs(documents, chunk_size=1000, chunk_overlap=20):
text_splitter = RecursiveCharacterTextSplitter(chunk_size=chunk_size, chunk_overlap=chunk_overlap)
docs = text_splitter.split_documents(documents)
return docs
docs = split_docs(documents)
print(len(docs))Embedding documents with OpenAI:
Once the documents are split, we need to embed them using OpenAI’s language model. First, we need to install the tiktoken library.
!pip install tiktoken -qNow, we can use the OpenAIEmbeddings class from LangChain to embed the documents.
embeddings = OpenAIEmbeddings(model_name="ada")
query_result = embeddings.embed_query("Hello world")
len(query_result)Vector search with Pinecone:
Pinecone is a high-performance vector database. It enables fast and accurate similarity searches for high-dimensional vectors. With its user-friendly API, scalability, and advanced algorithms, developers can easily handle large vector data, achieve real-time retrieval, and build efficient recommendation systems and search engines.
!pip install pinecone-client -qThen, we can initialize Pinecone and create a Pinecone index.
pinecone.init(
api_key="pinecone api key",
environment="env"
)
index_name = "langchain-demo"
index = Pinecone.from_documents(docs, embeddings, index_name=index_name)We are creating a new Pinecone vector index using the Pinecone.from_documents() method. This method takes three arguments:
docs: A list of documents that have been split into smaller chunks using the RecursiveCharacterTextSplitter. These smaller chunks will be indexed in Pinecone to make it easier to search and retrieve relevant documents later on.embeddings: An instance of the OpenAIEmbeddings class, which is responsible for converting text data into embeddings (i.e., numerical representations) using OpenAI's language model. These embeddings will be stored in the Pinecone index and used for similarity search.index_name: A string representing the name of the Pinecone index. This name is used to identify the index in Pinecone's database, and it should be unique to avoid conflicts with other indexes.
The Pinecone.from_documents() the method processes the input documents, generates embeddings using the provided OpenAIEmbeddings instance, and creates a new Pinecone index with the specified name. The resulting index object can perform similarity searches and retrieve relevant documents based on user queries.
5. Finding similar documents:
Now, we can define a function to find similar documents based on a given query.
def get_similiar_docs(query, k=2, score=False): # we can control k value to get no. of context with respect to question.
if score:
similar_docs = index.similarity_search_with_score(query, k=k)
else:
similar_docs = index.similarity_search(query, k=k)
return similar_docs6. Question answering using LangChain and OpenAI LLM:
With the necessary components in place, we can now create a question-answering system using the OpenAI class from LangChain and a pre-built question-answering chain.
from langchain.llm import AzureOpenAI
model_name = "text-davinci-003"
llm = AzureOpenAI(model_name=model_name)
chain = load_qa_chain(llm, chain_type="stuff") #we can use map_reduce chain_type also.
def get_answer(query):
similar_docs = get_similiar_docs(query)
print(similar_docs)
answer = chain.run(input_documents=similar_docs, question=query)
return answer7. Example queries and answers:
Finally, let’s test our question answering system with some example queries.
query = "How is India's economy?"
answer = get_answer(query)
print(answer)
query = "How have relations between India and the US improved?"
answer = get_answer(query)
print(answer)Here above we will get Context with particular query , then we pass query and context as a prompt to LLM Model to get a response.
8. Conclusion:
In this blog post, we have showcased the process of constructing a document-based question-answering system utilizing LangChain and Pinecone. By harnessing the capabilities of semantic search and large language models, this approach offers a robust and versatile solution for extracting valuable information from extensive document collections. Moreover, this system can be easily tailored and customized to cater to individual requirements and specific domains, providing users with a highly adaptable and personalized solution.
may this delightful journey of words have uplifted your spirits, brought a smile to your face, and left you with a heart brimming with joy and positivity. Happy reading and may happiness be your constant companion!
