Aakash NainUnsupervised Learning of Visual Features by Contrasting Cluster AssignmentsSelf-supervised learning, semi-supervised learning, pretraining, self-training, robust representations, etc. are some of the hottest terms…Aug 6, 20202Aug 6, 20202
Aakash NainRethinking Pre-training and Self-trainingIn late 2018, researchers at FAIR published a paper Rethinking ImageNet Pre-training which was subsequently presented in ICCV2019. The…Jun 28, 20201Jun 28, 20201
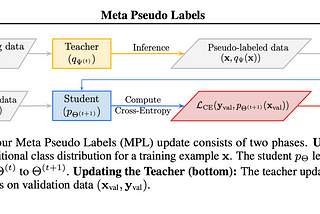
Aakash NainMeta Pseudo LabelsHave you heard of meta-learning? Do you remember the time when you used pseudo labeling for a Kaggle competition? What if we combine the…Apr 4, 20202Apr 4, 20202
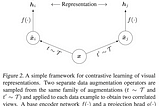
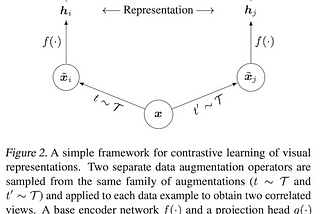
Aakash NainSimCLR: Contrastive Learning of Visual RepresentationsSemi-supervised learning is finally getting all the attention it deserves. From vision-based tasks to Language Modeling, self-supervised…Mar 6, 20202Mar 6, 20202
Aakash NainWhat we learned from KaggleNoobs!2019 is coming to an end. The landscape of Data Science and Machine Learning has made great progress. From an overwhelming amount of…Dec 20, 20191Dec 20, 20191
Aakash NainEfficientDet: Scalable and Efficient Object DetectionObject Detection has come a long way. From trivial computer vision techniques for object detection to advanced object detectors, the…Nov 28, 20197Nov 28, 20197
Aakash NainSelf-training with Noisy Student2019 has been the year full where a lot of research has been focused on designing efficient deep learning models, self-supervised learning…Nov 16, 2019Nov 16, 2019
Aakash NainGate Decorator: Global Filter PruningIn recent years, we have witnessed the remarkable achievements of CNNs. Iterative improvements for a task require bigger models and more…Nov 7, 20191Nov 7, 20191
Aakash NainWhen Does Label Smoothing Help?In late 2015, a team at Google came up with a paper “Rethinking the Inception Architecture for Computer Vision” where they introduced a…Jul 25, 2019Jul 25, 2019
Aakash NainEfficientNet: Rethinking Model Scaling for Convolutional Neural NetworksSince AlexNet won the 2012 ImageNet competition, CNNs (short for Convolutional Neural Networks) have become the de facto algorithms for a…Jun 7, 20195Jun 7, 20195