Nethaji Kamalapuram















Nethaji Kamalapuram
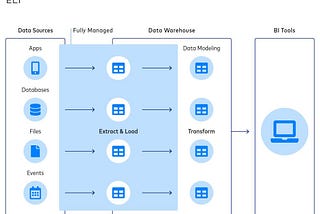
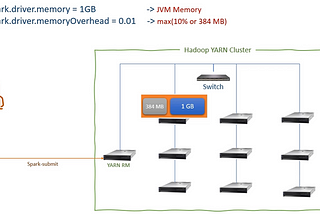
As a Lead Data Engineer, I specialize in cutting-edge data engineering tools and possess the expertise to design highly standardized architectures.
As a Lead Data Engineer, I specialize in cutting-edge data engineering tools and possess the expertise to design highly standardized architectures.