Understanding System Design of Netflix: Backend Architecture and Cloud Services
Introduction:
As most of us know, Netflix is a streaming service that offers a wide variety of award-winning TV shows, movies, anime, documentaries and more — on thousands of internet-connected devices.
Netflix has 200M+ subscribers worldwide in 200+ countries.
Statistics:
Before diving into the architecture of Netflix let us first go through some of the important statistics based on which this system is designed.
- Netflix Application has almost 400 billion events per day
- Around 8 million events and 17 GB per second during peak
- More than 200M subscribers
- Subscribers spread across more than 200 countries
- Supports 2000+ devices
- Average number of videos watched by a user per day = 5
- Average size of video = 500 MB
- Average number of videos uploaded per day from backend = 1,000
- Total upload storage required per day = 1,000 * 500 MB = 500 GB(approximately)
- Total storage required in 5 years = 500 GB * 5 * 365 = 912.5 TB
Onboarding a Video on Netflix
Netflix receives high-quality videos and content from production houses. However, Netflix supports 2000+ devices and each requires different resolutions and formats.
Netflix prepares multiple replicas of different videos for same movie with different resolution so as to serve users, the video quality based on their network speed and devices. To achieve this Netflix breaks the original video into different smaller chunks and using parallel workers in AWS it converts these chunks into different formats (like mp4, 3gp, etc.) across different resolutions (like 4k, 1080p, and more).This process is called transcoding.
After transcoding, once we have multiple copies of the files for the same movie, these copies are transferred to each and every Open Connect server which are placed in different locations across the world.
Cloud Services
Open Connect :- Open connect or Netflix cdn is a network of distributed servers spread across different geographical locations. Different replicas of files of the same movies are transferred to each and every open connect server. Open connect is mainly responsible for video streaming in Netflix. When you hit the play button, video is served to you from the nearest open connect server which leads to faster and better experience. It also increases the scalability of the whole system. These servers are called open connect appliances(OCA).
Note:- The above storage metric of 912.5 TB does not include the storage acquired due to these replicas.
AWS:- Netflix uses AWS for almost everything except video streaming. That includes online storage, recommendation engine, video transcoding, databases, and analytics.
When User clicks on the play button , Netflix analyzes the network speed or connection stability, and then it figures out the best Open Connect server near to the user. Depending on the device and screen size, the right video format is streamed into the user’s device.
Backend Architecture of Netflix
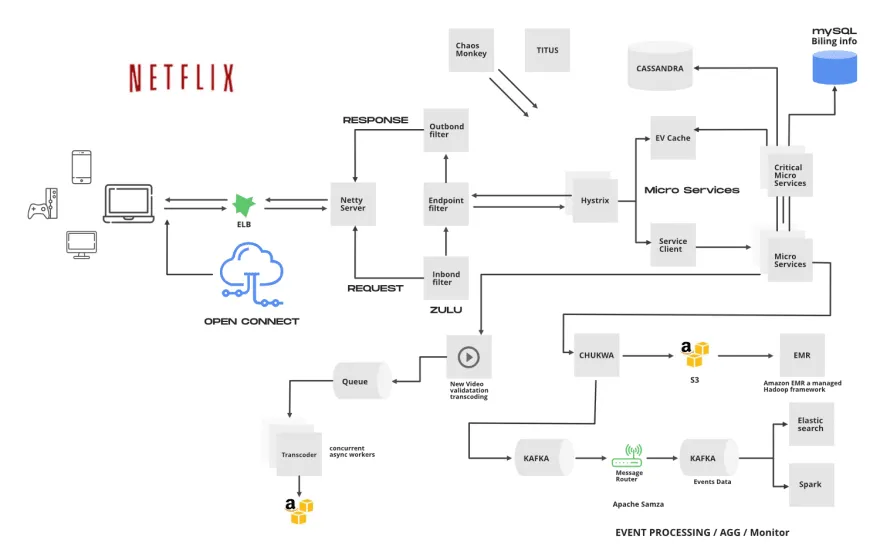
- Everything in Netflix except video streaming is handled by its backend service including onboarding new content, processing videos, distributing them to servers located in different parts of the world, and managing the network traffic.
- The request from the client is sent to AWS Elastic load balancer, which consists of a 2 tier architecture.
- Tier 1:- request from ELB first reaches this tier which is responsible for balancing load in different zones. DNS based round robin scheduling is used.
- Tier 2:- this tier consists of an array of load balancing instances. These instances perform round robin load balancing across instances that are in the same zone.
- ELB forwards this request to an API gateway. Netflix uses ZUUL as its API gateway which runs on AWS EC2 instances. ZUUL is a library developed and used by Netflix for dynamic routing, monitoring and security. ZUUL provides routing based on query parameters, URL and path.
- Netflix is built on collections of services. Building an application using a collection of services is known as microservice architecture. In microservice architecture, services are independent of each other.
- ZUUL is the front door for all requests from devices and websites to the backend of the Netflix streaming application. ZUUL routes the request to a specific service based on the user request. For example if a user tries to login then a request is sent to an authentication service.
- Netflix architecture has a complex distributed structure. Besides having many advantages , there are some dependencies too . For example, one server working can be dependent upon output of another server. Dependencies among these servers can create latency and can also lead to a single point of failure if one of the servers stopped working.
- For the above problem Netflix uses the hystrix . Hystrix is a very powerful library developed by Netflix that isolates every microservice from one another to minimize the number of failures. Hystrix does this by isolating points of access between the services. Hystrix is used for fail fast and rapidly recovery, near real-time monitoring, alerting, and operational control, reduce latency and failure from dependencies accessed (typically over the network) via third-party client libraries, stop cascading failures in a complex distributed system.
- User activities and history data is sent to stream processing pipeline which is used to give movie recommendations later
- This data is also sent to big data processing tools like AWS, Hadoop , Cassandra for further action.
Netflix Database:-
Netflix uses 2 different databases:-
- MySQL
- Cassandra
MySQL:-
For data like billing information, user information, and transaction information Netflix uses MySQL because it needs ACID compliance. Netflix has a master-master setup for MySQL and it is deployed on Amazon large EC2 instances.
According to the master master setup, if the writer happens to be the primary master node then it will be also replicated to another master node. The acknowledgment will be sent only if both the primary and remote master nodes’ writes have been confirmed. This ensures the high availability of data.
Netflix has set up the read replica for each and every node (local, as well as cross-region). This ensures high availability and scalability.
Cassandra:-
Netflix uses Cassandra for its scalability and lack of single points of failure and for cross-regional deployments. In effect, a single global Cassandra cluster can simultaneously service applications and asynchronously replicate data across multiple geographic locations.
Cassandra data model in Netflix:-
- 50+ Cassandra clusters
- 500+ nodes
- 30TB daily backups
- 250k Writes/s at each node
Use of Kafka And Apache Chukwa In Netflix
As we discussed above, Netflix is built on a collection of microservices, these microservices work together to provide a number of services to users.
Often in a microservice architecture, some percentage of failure is acceptable. However, some failures could lead to greater problems. A failure in any one of the microservice calls could lead to a plethora of computations being out of sync and could result in data being off by millions of dollars. It would also lead to availability problems and cause blind spots while trying to effectively track down and answer business questions as to what is causing this mismatch of data?
The solution of above problem is to rethink our service interactions as asynchronous event exchanges instead of a sequence of synchronous requests. This leads to following benefits
1. Our infrastructure becomes inherently asynchronous
2. Our application becomes loosely coupled and traceability of errors is improved.
Netflix uses Apache Kafka for its eventing, messaging and stream processing needs.
Apache Kafka works on a publish/subscribe model. services in Netflix publish their changes as events into a message bus, which are then consumed by another service of interest that needs to adjust its state of the world.
This allows us to track whether services are in sync with respect to state changes and, if not, how long before they can be in sync. These insights are extremely powerful when operating a large graph of dependent services.
Event-based communication and decentralized consumption helps us overcome issues we usually see in large synchronous call graphs (as mentioned above).
Apache Chukwa :-
Apache chukwa is an open source data collection system which is used to monitor complex distributed systems. chukwa collects events from different microservices and writes them in Hadoop file sequence format. Chukwa also provides traffic to Kafka for uploading events to various sinks:- S3, Elastic search etc.
Elastic Search:-
Elastic search is used in Netflix to provide customer care support, data visualization and error detection. For example, if a user is not able to play a video , the playback team will go to elastic search and find the reason for the issue. It is also used to keep track of resource usage and to detect signup or login problems.
References
