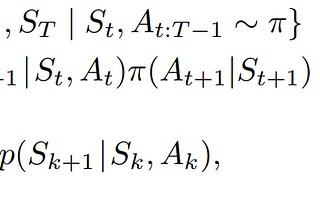Numfor TiapoReinforcement Learning Chapter 5 — Monte Carlo Methods (Part 4: Off-policy via Importance Sampling)In the previous article, we learned about the difference between on-policy and off-policy methods. In this article, we will learn about a…Apr 12, 2023Apr 12, 2023
Numfor TiapoReinforcement Learning Chapter 5 — Monte Carlo Methods (Part 3: MC without Exploring Starts)In the previous article, we learned about a MC approach for control that requires the assumption of exploring starts to address the…Apr 12, 20231Apr 12, 20231
Numfor TiapoReinforcement Learning Chapter 5 — Monte Carlo Methods (Part 2: Monte Carlo Control)In the previous article, we learned about Monte Carlo methods, how they differ from Dynamic Programming methods, and how they can be used…Apr 12, 2023Apr 12, 2023
Numfor TiapoReinforcement Learning Chapter 5: Monte Carlo Methods (Part 1 — Monte Carlo Prediction)The previous few articles covered Dynamic Programming methods as the first set of solutions to the full reinforcement learning problem. In…Apr 12, 2023Apr 12, 2023
Numfor TiapoReinforcement Learning Chapter 4: Dynamic Programming (Part 4 — Asynchronous DP & Generalized…In the last few articles, we’ve learned about Dynamic Programming Methods and seen how they can be applied to a simple RL environment. In…Mar 7, 2023Mar 7, 2023
Numfor TiapoReinforcement Learning Chapter 4: Dynamic Programming (Part 3 — Value Iteration)In the previous articles, we learned about the Policy Iteration algorithm and saw how to implement it and use it on Grid World. In this…Mar 6, 2023Mar 6, 2023
Numfor TiapoReinforcement Learning Chapter 4: Dynamic Programming (Part 2 — Policy Iteration in Grid World)In the previous article, we learned about Dynamic Programming and the Policy Iteration algorithm. In this article, we’ll look at a python…Mar 4, 2023Mar 4, 2023
Numfor TiapoReinforcement Learning Chapter 4: Dynamic Programming (Part 1 — Policy Iteration)In the previous article we defined the full Reinforcement Learning Problem as a finite Markov Decision Process. In this article we’ll…Mar 4, 20231Mar 4, 20231
Numfor TiapoReinforcement Learning Chapter 3: Finite Markov Decision ProcessesPrevious ChapterFeb 24, 2023Feb 24, 2023
Numfor TiapoReinforcement Learning Chapter 2: Multi-Armed Bandits (Part 6 — Associative Search)In the previous articles, we’ve learned about the Multi-Armed Bandits Problem as well as how different solutions for it compare against…Feb 22, 2023Feb 22, 2023