Into the Depths of HyperTextualInversion: A Personal Journey Through AI - Part 1
Introduction
Hello and welcome, everyone! Today, I invite you to join me on an incredible journey through the intricate landscape of hypertextual inversion. This groundbreaking concept, introduced in Google’s HyperDreambooth paper, is shaping the future of AI technology by transforming our understanding of the interplay between images and text. So, prepare yourself for a fascinating voyage!
The First Step: A Leap into Feedforward Neural Networks
Every remarkable journey begins with an initial leap, and my expedition into hypertextual inversion commenced with the application of feedforward neural networks. Characterized by the unidirectional flow of information — from input to output — feedforward networks have shown proficiency in handling tasks with well-defined input-output pairs.
Despite the promising theory, the practical results were a bit of a letdown. My model’s loss graph exhibited convergence — an indication that learning was taking place. Yet, the results didn’t match the anticipated outcome. While it was a stumbling block, it also served as a learning opportunity, reminding us that challenges are integral components of any AI journey.

Course Correction: The Shift to Transformer-Decoder Networks
Faced with the initial setback, it was time for a tactical shift. Drawing inspiration from Google’s approach, I decided to experiment with the transformer-decoder network. Unlike the feedforward network, the transformer-decoder network is renowned for its ability to effectively handle sequential data.
The choice of transformer-decoder networks by Google wasn’t random. They used it for predicting text embeddings and UNet parameters sequentially. Besides this, there’s another important advantage to transformer networks — their “self-attention” mechanism. This feature enables the model to focus on various parts of the sequence in a context-dependent manner, thereby enhancing the accuracy of its predictions.
Exploring the Foundations: Stable Diffusion and CLIP-ViT Large 14
There are two primary models underpinning this exploration: stable diffusion and CLIP-ViT Large 14.
Stable diffusion represents an innovative progression in the field of generative models. It incorporates a process that permits the controlled generation of data — specifically, the textual embedding that is predicted from the image encoding in our case.
On the other hand, CLIP-ViT Large 14 hails from the family of OpenAI’s formidable CLIP models. These models, trained to comprehend images in relation to natural language, function as the driving force behind our exploration into the symbiosis between image and text representations.
Navigating the World of CLIP
To further enhance my understanding of the intricate relationship between image and text representations, I plunged into the vast world of the Hugging Face’s concept library repository. This resourceful repository, packed with high-quality language models, provided an opportunity to analyze thousands of images and embeddings.
Visualising the embedding space
During this in-depth analysis, I made use of three key statistical methodologies: K-means clustering, silhouette score, and Z-score.
- K-means clustering is a valuable tool in unsupervised learning, facilitating the detection and categorization of patterns within a dataset.
- Silhouette score provides a measure of how well each data point in one cluster aligns with data points in the neighboring clusters, serving as an effective classification evaluation tool.
- Z-score offers a statistical measurement that illustrates a value’s relationship to the mean of a group of values. It aids in identifying outliers and comprehending the variability within the data.
This analytical excursion culminated in the creation of various graphs that revealed how different embeddings correlate with styles and objects in the CLIP model.
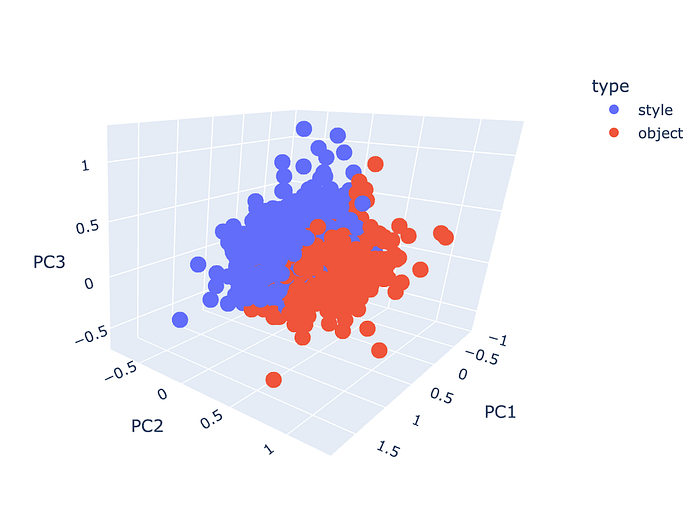


Gazing Ahead: The Next Stages
With all these moving parts, my journey has now reached a particularly exhilarating stage. The road ahead involves further refinement of the transformer-decoder network, coupled with an exploration of the capabilities of stable diffusion in harmony with the CLIP model.
In the coming stages, I look forward to sharing deeper insights, revealing results, and providing image examples, plots, and graphs to bring greater clarity to our understanding of hypertextual inversion.
Embarking on this exploration into the world of AI has been a thrilling endeavor, and the excitement continues to grow with each step. So, stick around for more updates — it’s an exhilarating adventure through the realms of AI that’s full of insights and discoveries!
To be continued…
Here is a picture of a bunny(?) that was supposed to be a picture of a woman, based on the embedding generated by the model for you who did read until the end :)

Read the previous story “The Magic Mirror” here: https://medium.com/@okaris/the-magic-mirror-840343e7a98e
