Attention Mechanisms in Transformers
A transformer is a neural network model that learns context and thus meaning by tracking relationships of sequential data (like the words in a sentence). It has been evolving more to steal the spotlight in modern deep learning and neural networks.
This article will look into attention mechanisms, which form the fundamental operation in any transformer model.
The simplest form of attention mechanism is self-attention. In self-attention, a sequence of vectors is given as input. The block converts it into a sequence of output with more context.
Self-attention is called so because it involves the inputs interacting with each other (“self”) and finding out who they should pay more attention to (“attention”).
Let’s say I tell my computer: “I heard the phone ring”. The machine is innately not smart enough to understand if I am talking about a diamond ring or the sound. Our aim with attention mechanisms is to train the transformer networks to deduce the meanings of words by using contexts. Like in this case, since the word ‘phone’ precedes ring, it is more likely that the ‘ring’ here denotes the sound.
A transformer typically has an encoder block and a decoder block. The encoder has two sub-layers: a feed-forward neural network and an attention block. The encoder’s input flows into the self-attention layer, where the features of an input sequence are extracted. The output of this sub-layer flows into a feed-forward neural network.

The decoder uses these extracted features to produce the required output (for example, a translated sentence). However, we will only focus on the encoder part in this article.
How the Encoder block works:
A transformer’s encoder consists of multiple encoder blocks. Each word is assigned a vector embedding and is given as the input to the self-attention block of the first encoder block. The output is produced simply by taking the weighted average of the input sequences.

The weights required are derived by a function over the two vectors(trivially dot product). The weights are where the context comes into the picture. The weights are also normalized to map the values to [0,1] using softmax.


The output is fed into the next encoder block, and so on.
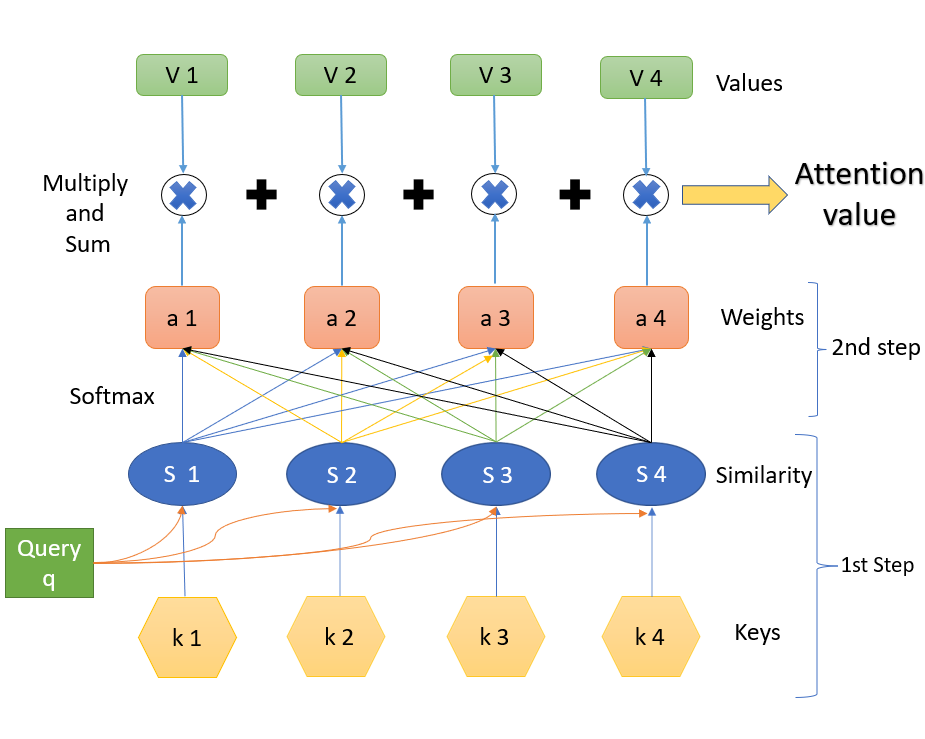
A self-attention mechanism works as follows:

The basic intuition behind why self-attention works to give context is as follows. The weights are derived by taking dot products between two vectors. The values of weights thus express how much the two vectors are related. The higher the value of weights, the more the relation.
For example, consider a statement: “The dog chased after a ball”. In this statement, the article ‘the’ is not much of a help for the interpretation of the other words. Hence its vector embedding is supposed to have a low value of dot product with the other vectors. Whereas, the vectors corresponding to ‘dog’ and ‘chased’ will have a higher value of dot product.
As you can see, self-attention involves the input being used three times. There are no other parameters for us to train except these. We differentiate these three usages by calling them keys, queries and values.
- The key vector is compared to every other vector to determine the weights for its own output.
- Queries are the vectors being compared to the key vector.
- Values indicate the final usage of the input vectors, where it is multiplied by the determined weights to establish the outputs.
We assign a matrix to each of the three usages. These act as the controllable parameters that can be trained.
We should also consider the cases where a word has different contexts with respect to different words. In the example we discussed above, ‘chased’, with respect to ‘dog’, answers the question ‘who’. Whereas ‘chased’ with respect to ‘ball’ answers the question ‘what’. A single attention head can’t do the job of giving different contexts. Thus, we combine multiple self-attention heads to form a multi-head self-attention.
The same vector sequence is loaded into different h different attention heads.
For an input vector xi (of dimension k), each attention head produces a different output vector, yi. All the output vectors, yi’s, are concatenated to produce one vector of dimension k (i.e. the same dimension as the input).

It is also notable that the vector embeddings we use do not take into account the positional context of words. But in all cases, some context is provided by the position and order of words, at least a little. Hence, the transformer architecture uses a positional encoding scheme. Each position is mapped to a vector. And this position vector is combined with the original input sequence while being fed into the encoder of the transformer block.
The picture below summarizes a typical transformer architecture.

SOURCES:

{kind=link}