NLP | Como treinar um modelo de Question Answering em qualquer linguagem baseado no BERT large, melhorando o desempenho do modelo utilizando o BERT base? (estudo de caso em português)

Após o tutorial com o BERT base, este tutorial apresenta um método universal para treinar um modelo BERT large para encontrar uma resposta a uma pergunta em um texto (se chama BERT QA ou BERT Question Answering), o tipo de modelo usado pelo… Google Search! O método usa as bibliotecas transformers da Hugging Face e DeepSpeed da Microsoft. É aplicado ao caso português e o modelo resultante supera o desempenho do modelo BERT base QA treinado com o mesmo dataset (SQuAD 1.1 em português). Ele é publicado no Model Hub da Hugging Face, enquanto seu notebook de treinamento está disponível no GitHub (versão nbviewer). Obrigado a todas as organizações (ver parágrafo “Agradecimentos”) que tornaram possível obter um modelo de NLP (PLN: Processamento de Linguagem Natural) tão eficiente!
- Link para testar online e baixar o modelo:
- Link para o notebook no github (versão nbviewer): question_answering_BERT_large_cased_squad_v11_pt.ipynb
- Link para o primeiro post sobre BERT base QA:
Sumário
- O que faz um modelo QA?
- Contexto
- transformers (Hugging Face) + DeepSpeed
- Minhas adições
- Resultados
- Exemplo de uso | Nosso modelo BERT QA em português vs a pandemia de COVID-19
- >> Quando começou a pandemia de Covid-19 no mundo?
- >> Outras perguntas
- Aviso
- Agradecimentos
O que faz um modelo QA?
Um modelo Question Answering (QA) é um modelo de linguagem natural (BERT, por exemplo) adaptado à tarefa de responder a perguntas, seja um modelo capaz de extrair de um texto (o contexto) a sequência de palavras que constitui a resposta a uma pergunta.
Contexto
Publiquei no dia 12 de fevereiro de 2021 um tutorial e um notebook no Google Colab e GitHub (versão nbviewer) explicando como treinar no Google Colab um modelo de Question Answering (QA) em qualquer idioma baseado no BERT base.
Ao aplicar esse tutorial em português, consegui publicar um tal modelo no Model Hub da Hugging Face.
Parece que esse modelo atendeu às expectativas, pois no mês passado já foi baixado quase 3000 vezes!
Top… mas como parte desses downloads corresponde a um uso profissional, é natural questionar se é possível treinar um modelo ainda mais eficiente, por exemplo a partir de um BERT large (345 milhões de parâmetros contra 110 para o BERT base).
A resposta é sim e vamos ver como.
transformers (Hugging Face) + DeepSpeed
Em fevereiro de 2021, eu já havia apresentado a biblioteca DeepSpeed após sua primeira integração com a biblioteca transformers da Hugging Face (leia Fit More and Train Faster With ZeRO via DeepSpeed and FairScale).
Essa biblioteca (DeepSpeed) tornou-se essencial para treinar modelos pesados de Deep Learning, como os do NLP. Ela não só permite o uso de um único GPU (o que é o caso da maioria das pessoas, e muitas vezes das empresas), mas também reduz significativamente o tempo de treinamento desses modelos.
Com os recentes anúncios do Hugging Face (veja os tweets abaixo de Stas Bekman e a documentação Trainer Deepspeed Integration), vi que a integração entre as 2 bibliotecas continuou e a recente atualização no dia 10 de junho do notebook transformers + deepspeed CLI que mostra como configurar transformers + DeepSpeed para funcionar no Colab me decidiu a treinar um BERT large para a tarefa de QA (Question-Answering) em português.
Minhas adições
Portanto, adaptei o notebook do Stas Bekam à tarefa de Question-Answering (QA) por um BERT large usando o script run_qa.py da Hugging Face e DeepSpeed ZeRO-2, que permitem ajustar (fine-tune) um modelo de linguagem para a tarefa de QA (aqui, fiz um ajuste fino do modelo BERT large cased em português da Neuralmind).
Por isso, usei de novo o dataset SQuAD 1.1 em português (versão em português do dataset SQuAD v1.1 inglês cuja tradução foi feita pelo grupo Deep Learning Brasil: squad-pt.tar.gz no Google Drive (fonte)).
Para permitir o uso futuro do meu notebook com qualquer outro dataset e qualquer outra configuração dos parâmetros de treinamento, eu voluntariamente deixei o código de configuração do dataset e fiz todos os parâmetros aparecerem no código.
Além disso, adicionei o código necessário para visualizar os outputs do treinamento em TensorBoard, o código que permite redefinir os valores dos parâmetros do modelo treinado para float32 (leia Getting The Model Weights Out), e o código que permite preparar o modelo a ser transferido para o Model Hub de Hugging Face (leia Model sharing and uploading).
Por fim, adicionei o código para testar o modelo treinado com um texto e perguntas seja nas cédulas, seja numa interface Gradio (leia Using & Mixing Hugging Face Models with Gradio 2.0), e publiquei o modelo treinado no Model Hub de Hugging Face e meu notebook no github de acordo com as boas práticas sobre o compartilhamento de modelos de NLP.
Et voilà :-)
Resultados
Aqui está o notebook no GitHub (versão nbviewer): question_answering_BERT_large_cased_squad_v11_pt.ipynb
O modelo superou o desempenho do BERT base QA:
f1 = 84.43 # base: 82.50
exact match = 72.68 # base 70.49O modelo BERT QA resultante foi publicado no Model Hub da Hugging Face no dia 18/06/2021:
Exemplo de uso | Nosso modelo BERT QA em português vs a pandemia de COVID-19
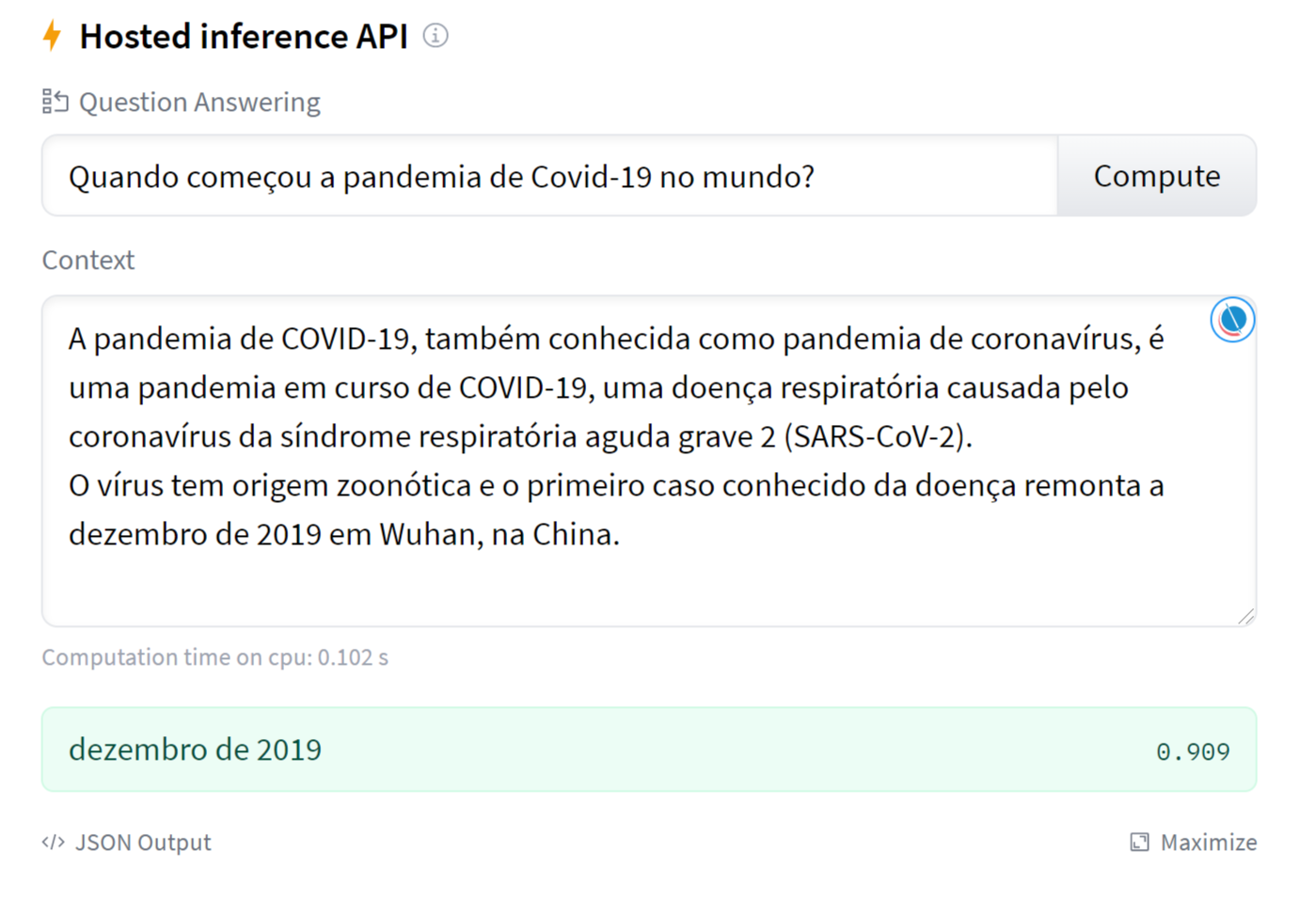
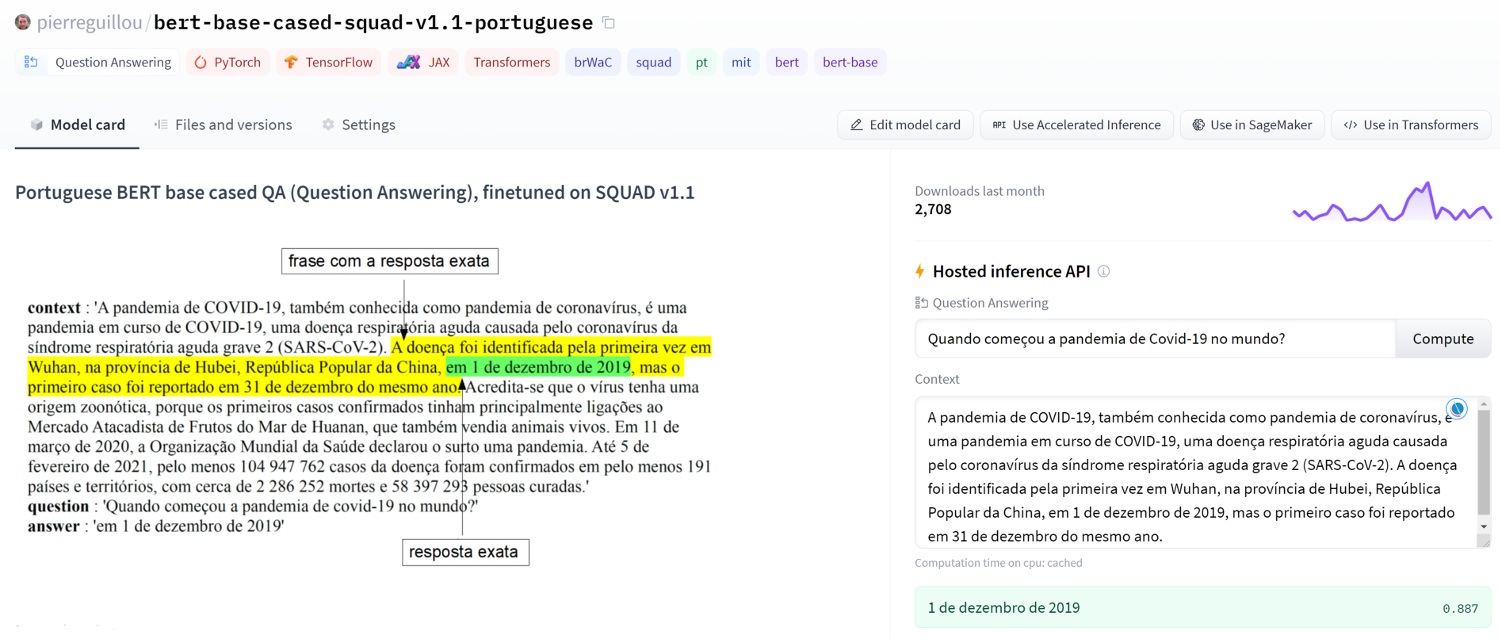
Quando começou a pandemia de Covid-19 no mundo?
Vamos pegar o exemplo desta pergunta “Quando começou a pandemia de Covid-19 no mundo?” com o texto da página da Wikipedia no dia 18/06/2021 :
A pandemia de COVID-19, também conhecida como pandemia de coronavírus, é uma pandemia em curso de COVID-19, uma doença respiratória causada pelo coronavírus da síndrome respiratória aguda grave 2 (SARS-CoV-2). O vírus tem origem zoonótica e o primeiro caso conhecido da doença remonta a dezembro de 2019 em Wuhan, na China.
Em 20 de janeiro de 2020, a Organização Mundial da Saúde (OMS) classificou o surto como Emergência de Saúde Pública de Âmbito Internacional e, em 11 de março de 2020, como pandemia.
Em 18 de junho de 2021, 177 349 274 casos foram confirmados em 192 países e territórios, com 3 840 181 mortes atribuídas à doença, tornando-se uma das pandemias mais mortais da história.
Os sintomas de COVID-19 são altamente variáveis, variando de nenhum a doenças com risco de morte. O vírus se espalha principalmente pelo ar quando as pessoas estão perto umas das outras. Ele deixa uma pessoa infectada quando ela respira, tosse, espirra ou fala e entra em outra pessoa pela boca, nariz ou olhos.Ele também pode se espalhar através de superfícies contaminadas. As pessoas permanecem contagiosas por até duas semanas e podem espalhar o vírus mesmo se forem assintomáticas.Podemos ler no caderno no GitHub que o nosso modelo encontrou a resposta correta:
Answer: 'dezembro de 2019', core: 0.5087, start: 290, end: 306E o que é ainda mais interessante, é que a resposta não depende da formulação da questão (não depende das palavras chave)! Com a questão “Qual é a data de início da pandemia Covid-19 em todo o mundo?”, o nosso modelo encontrou também a resposta correta:
Answer: 'dezembro de 2019', score: 0.4988, start: 290, end: 306Outras perguntas
Usando o mesmo conteúdo, podemos ler no caderno no GitHub que nosso modelo encontrou as respostas corretas para todas as perguntas.
Por exemplo: “Como se espalha o vírus?”
Answer: 'principalmente pelo ar quando as pessoas estão perto umas das outras', score: 0.3173, start: 818, end: 886Aviso
Nosso modelo funciona bem, mas é importante lembrar que os modelos em inglês alcançam um desempenho ainda melhor. Para atingir os mesmos níveis, seria necessário, por exemplo, usar um conjunto de dados de QA em português com mais exemplos.
No entanto, o método explicado nesse tutorial será aplicado da mesma maneira.
Agradecimentos
A publicação online de modelos de NLP é hoje extremamente facilitada por vários órgãos de IA que publicam em Open Source ou que disponibilizam ferramentas online como scripts e plataformas GPU:
- O Google Brain (hoje, Google AI), que ao desenvolver a arquitetura do Transformer em 2017 (artigo “Attention is all you need”) e depois o modelo BERT em 2018, permitiu a publicação de modelos de linguagem natural eficientes em diferentes idiomas.
- A Hugging Face (HF), que ao fornecer uma biblioteca de NLP (Transformers), scripts e um Model Hub, permite o compartilhamento de modelos existentes e seus treinamentos para novas linguagens e/ou novas tarefas.
- A Microsoft, que ao fornecer uma biblioteca de NLP (DeepSpeed), permite o treinamento mais rápido de modelos maiores.
- A Neuralmind, que em 2019 criou um corpus geral em português (BrWaC (Brazilian Web as Corpus)) e que com ele, treinou 2 modelos BERT (base e large) para entender a língua portuguesa e os disponibilizou no Model Hub de HF.
- O grupo Deep Learning Brasil, que disponibilizou em 2020 o dataset SQUAD em português, que usei par ajustar o modelo BERT base para a tarefa de QA em português (usando um script da HF) e cujo link foi publicado no fórum do AI Lab.
- O Google Colab que permitiu de treinar gratuitamente modelos De Deep Learning,
- O GitHub (Microsoft) que permitiu de publicar online o caderno de treinamento.
Por fim, gostaria de agradecer o AI Lab, laboratório em Inteligência Artificial da Universidade de Brasilia (UnB), do qual faço parte como pesquisador e docente em Deep Learning, e que me permite de atualizar meu conhecimento em Deep Learning, e em NLP em particular.
Et voilà! Sem esses atores, gerar um modelo QA eficiente em português e acessível a todos seria muito mais complicado e certamente impossível devido à complexidade do código para digitar e aos custos de tal projeto (recursos humanos, plataformas com GPU, tempo de computação…).

Sobre o autor: Pierre Guillou é consultor de IA no Brasil e na França, pesquisador em Deep Learning e NLP do AI Lab (Unb) e professor de Inteligência Artificial (UnB). Entre em contato com ele por meio de seu perfil no LinkedIn.
