Under Fitting / Over Fitting ปัญหาที่มองไม่เห็นแต่สัมผัสได้ว่ามี….. : Machine Learning 101
ทำโมเดลเก่งแค่ไหน แต่ถ้าเตรียมข้อมูลไม่เป็นก็ไร้ความหมาย

บทความนี้จะมาพูดถึงเรื่องUnder Fitting / Over Fitting ของโมเดลที่เราสร้างขึ้นมาโดยโมเดลที่เราจะทำการทดลองในบทความนี้คือ k-NN (บทความ&โค้ด)
Under Fitting / Over Fitting คืออะไร ?
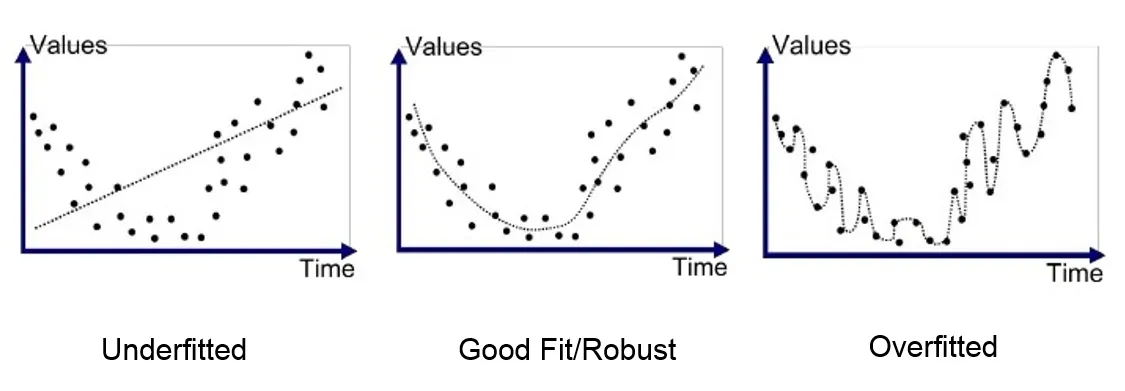
อธิบายได้ง่ายๆสั้นๆว่า
Under-fitting(รูปซ้ายมือ) คือ หากเอาไปทำนาย/จัดกลุ่ม ผลลัพธ์จะไม่ค่อยถูกและไม่ใกล้เคียงกับเฉลยหรือคำตอบที่แท้จริงเลย
แต่ Over-fitting จะสามารถทำนายข้อมูล/จัดกลุ่มข้อมูลตอนทำการฝึกได้อย่างถูกต้องและแม่นยำ แต่ถ้านำออกไปใช้งานได้จริงก็จะทำนายไม่มีทางถูกเลย/ถูกน้อยมาก
เพราะฉนั้นสิ่งที่เราต้องการคือ Good Fit คือ ตอนฝึกก็ทำนายข้อมูลชุดฝึกผิดบ้าง พอออกไปใช้งานจริงๆ ก็ยังทำนาย/จัดกลุ่ม ข้อมูลชุดๆนั้นๆได้แม่นยำอยู่ดี
ตัวอย่างเช่น เราสอนเด็ก3คนคือ น้องUnder น้องOver และน้องGood วิชาภาษาอังกฤษ เราเขียนตัวอักษร A ด้วยลายมือของเราเอง ให้น้องๆทั้ง 3 ดู จากนั้นเราเขียนตัวอักษร A ด้วยลายมือของเราเอง(อีกรอบ) แล้วให้น้องๆทั้ง 3 ลองทายมาว่ามันคือตัว A หรือ B ? น้องๆทั้ง 3 จะได้คำตอบประมาณนี้
น้องUnder จะตอบว่ามันคือ B (มันคือตัวไรอะ…..)
น้องOver จะตอบว่ามันคือ A (มันคือตัว A ฉันเคยเห็นมันมาก่อน)
และน้องGoodจะตอบว่ามันคือ A (มันคือตัว A มันคุ้นๆเหมือนเคยเห็นมาก่อน)
จากนั้น เราลองเขียนตัว A อีกรอบแต่เป็นลายมือข้างที่ไม่ถนัด
น้องUnder จะตอบว่ามันคือ B (มันคือตัวไรอะ…..)
น้องOver จะตอบว่ามันคือ B (มันคือตัวไรอะ….. ฉันไม่เคยเห็นมันมาก่อน)
และน้องGoodจะตอบว่ามันคือ A (มันคือตัว A มันคุ้นๆเหมือนเคยเห็นมาก่อน)
คำถามชวนคิด : ถ้าอย่างนั้นเราควรจะสนใจ train score หรือ test score มากกว่ากัน ?
สิ่งที่จะเกิดขึ้นตามมา
Bias & Variance โดยที่ Variance จะแปรพกพันตรงกับ Bias โดยที่
Biasยิ่งมาก = โมเดลที่เราสร้างขึ้นมามันจะยิ่งห่างไกลจากความเป็นจริง (≠ reality) แต่ข้อดีคือโมเดลจะเรียนรู้ข้อมูลได้ง่ายมาก เทรนเร็ว
Varianceยิ่งมาก = โมเดลนั้นมีแนวโน้มจะเกิดปัญหา overfitting ได้
(อ่านเพิ่มเติมบทความของคุณ Kasidis Satangmongkol)

แล้วเราจะทำยังไงไม่ให้มันเกิด Under หรือ Over fitting กับข้อมูลของเรา ?
- ใช้วิธี Cross Validation (k-fold) แบ่งข้อมูลออกเป็นก้อนๆย่อยๆ แล้วเก็บข้อมูลส่วนหนึ่งไว้ทำการ testing เช่น เรามีข้อมูล 1 ก้อน (100%) แบ่งออกเป็น 10 กอง กองละ 10% ให้ทำการเก็บ 10% ไว้ test ก่อนเลย [เหลือ 90% ไว้ฝึก]
- นำข้อมูล 90% ที่เราแบ่งไว้ แบ่งมาอีก 10–15% ให้เรียกก้อนนี้ว่า Validation(เอาไว้ทดสอบโมเดลเหมือนข้อมูลโลกจริงๆ)
- สรุป เหลือข้อมูลไว้ฝึก 75%-80% Validation 10%-15% test 10% คือยังมีข้อมูลจำนวนมากไว้ฝึก แต่ก็ไม่ฝึกมากจนเกินไป

แล้วต้องเขียนโปรแกรมแบ่งข้อมูลพวกนั้นเองตลอดเลย?
ไม่จำเป็น เพราะปัจจุบันมี lib ที่คอยช่วยอยู่แล้ว โดย sklearn นั้นมีให้หมดเลย โดยเริ่มต้นกันที่ k-NN แบบเก่าที่เคยขียนไว้แล้ว
เบื้องต้นจะให้ข้อมูลตั้งแต่ทั้ง 2 วิธีนี้เท่ากันก่อน
x = data[“data”][:,2:4]
y = data.target[:]วิธีที่ 1 sklearn และใช้ k-fold
from sklearn.model_selection import KFold
kf = KFold(n_splits=5,shuffle=True,random_state=101)kf.get_n_splits(x)for train_index, test_index in kf.split(x):
X_train, X_test = x[train_index], x[test_index]
y_train, y_test = y[train_index], y[test_index]print(‘Train Shape X: {} Y : {}’.format(X_train.shape,y_train.shape))
print(‘Test Shape X: {} Y : {}’.format(X_test.shape,y_test.shape))
ขั้นตอนแรก ผมใช้ k-fold แบ่งข้อมูลออกมา โดยจะมีทั้งหมด 150ข้อมูล ผมแบ่งเป็น train =135 และ test = 15 โดยข้อมูลจะมีทั้งหมด 3 กลุ่ม คือ 0,1และ2

เห็นได้ว่า k-fold ก็ยังสามารถแบ่งข้อมูลออกมาได้ 3 กลุ่มเหมือนเดิม แถมยังแบ่ง train กับ test ให้พร้อมอีก
ทีนี้ก็ลองเทรนและเทสมันดู (ยังใช้วิธีตรวจสอบเหมือนเดิม) พบว่ามันไม่ได้เลวร้ายอะไรเลย แถมยังแบ่งข้อมูลออกมาแล้ว โดยแบ่งเป็น 8:2 (80%คือเทรน 20%คือเทส)
knn.fit(X_train,y_train )
answer = knn.predict(X_test)
from sklearn.metrics import classification_report
print(classification_report(y_test, answer))
แม้ค่าความแม่นยำจะลดลงแต่ก็ลดความ over-fitting ได้แน่นอน
วิธีที่ 2 sklearn ใช้ train_test_split
วิธีนี้จะสั้นกว่าวิธีแรก และยังสามารถ shuffle ประเภทกันได้อีก
from sklearn.model_selection import train_test_splitX_train, X_test, y_train, y_test = train_test_split(x, y, test_size=0.2, random_state=42,shuffle =True)
print(‘Train Shape X: {} Y : {}’.format(X_train.shape,y_train.shape))
print(‘Test Shape X: {} Y : {}’.format(X_test.shape,y_test.shape))
และทำการทดลองทำนายดู
answer = knn.predict(X_test)
from sklearn.metrics import classification_report
print(classification_report(y_test, answer))
มันทำนาย 30 ข้อมูลถูกหมดเลย !!
ส่วนสาเหตุที่ว่าทำไมถึงทายถูกหมดเลยนั้น เพราะว่าเรา shuffle ข้อมูลทั้งหมดทำให้มันเรียนรู้ได้หลากหลายมากขึ้นแต่ตัว k-fold มัน shuffle แค่ข้อมูลในกลุ่มเดียวกันเท่านั้น ทำให้ train_test_split สามารถเรียนรู้และทำนายได้ดีมากกว่า เพราะมันเจอข้อมูลที่หลากหลายกว่านั้นเอง
แต่พอเอา shuffle ออกเท่านั้นเหละ ….

แล้วถ้าโมเดลเรามัน Under Fitting ละ ?
จากบทความ K-NN ก่อนหน้านี้เราได้ทำการทดสอบ GridSearchCV ทีนี้เราลองมาเจาะลึกกันว่ามันคืออะไร
GridSearchCV คือการหาปรับ parameter (n_components / จำนวนเพื่อนบ้าน) ของ Hyper parameter (เพื่อนบ้าน) นั้นเองโดยทุกๆโมเดลจะมี Hyper parameter เป็นของตัวเอง เราจะต้องทำการศึกษาว่าโมเดลนั้นจะต้องปรับค่าอะไร
โดยการปรับค่านั้นตัว GridSearchCV จะทำการปรับ parameter ทีละค่าเหมือนเราทำ manual ด้วยมือนั้นเอง และมันจะทำการหา “parameter” ที่ดีที่สุดออกมาด้วยการเลือก parameter ที่มีค่าความแปรปรวนน้อยที่สุด หากค่า parameter มีค่าแปรปรวน “เท่ากัน” ตัว search จะทำการเลือก parameter ที่มีค่าน้อยสุดเพื่อทำให้โมเดลนั้นๆไม่เกิด Under Fitting และ ยังไม่เกิด Over fitting เพราะค่า parameter ที่มากเกินไปอีกด้วย

ถ้าเรารันโมเดลที่ผ่านการสเกล (Scale) ค่ามาแล้วแต่ถ้าไม่ทำการปรับโมเดล (GridSearchCV) โมเดลก็ไม่สามารถที่จะทำความแม่นยำได้ที่ 100% เช่นกัน

บทความหน้าจะขึ้นในเรื่อง Evaluate หลังจากที่เราจัดการ Under/Over Fitting ได้แล้วก็ได้เวลามาประเมินโมเดลแล้ว ว่ามันดีพอที่จะใช้งานได้หรือยัง ?
บทความถัดไป :

บทความก่อนหน้า K-NN กับ Sklearn : Machine Learning 101
Github : https://github.com/peeratpop/Machine_Learning_101
Medium : https://medium.com/@pingloaf
Linkedin : https://www.linkedin.com/in/peerat-limkonchotiwat/
