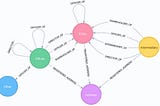
Pratik MukherjeeIntegrating a Neo4j Graph into the FrontendNeo4j is a popular graph database that is used to store and query complex relationships between data. One of the advantages of using a…Jan 8, 20232Jan 8, 20232
Pratik MukherjeeAccessing Neo4J from DjangoDjango is a powerful web framework for Python that makes it easy to build web applications quickly. Neo4j is a popular graph database that…Jan 7, 2023Jan 7, 2023
Pratik MukherjeeinTowards DevPayment Gateway Integration to Django-AngularHi reader, in this blog I will be summarizing the points of integrating the Stripe payment gateway into a full-stack application built on…Jun 19, 2022Jun 19, 2022
Pratik MukherjeeSetting up ML dashboard in a local systemThis will be a short article with only the intent of showing how you can set up the housing prices dashboard on your local system.Mar 17, 2022Mar 17, 2022
Pratik MukherjeeDeploying a dockerized react app on HerokuThe title and the banner image both are quite anti-climactic. I will agree with that. They give away half of what I am going to show…Dec 10, 2021Dec 10, 2021
Pratik MukherjeeIntegrating your first rasa chatbot to your websiteEver thought of adding a chatbot to your website, but never knew how to?Oct 1, 20201Oct 1, 20201
Pratik MukherjeeBar chart race animation on Corona Virus dataIn this article, I will only focus on how to create a bar chart race rather than formatting or analyzing the data.Apr 2, 2020Apr 2, 2020
Pratik MukherjeeIRIS Flower ClassificationThis is the first blog in the series explaining each of the steps of a Data Science project. If I receive feedback(both positive and…Feb 6, 2020Feb 6, 2020