Rafael FelippeLinguagem SQLA SQL (Structured Query Language) é uma das linguagens mais antigas e famosas do mundo. Criada nos anos 70, ela tem o objetivo de manipular…Mar 20, 2022Mar 20, 2022
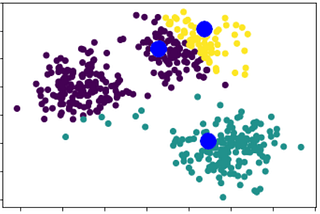
Rafael FelippeK-MeansUm dos mais famosos e utilizados algoritmos de clusterização é o K-Means. Ele trabalha definindo um valor, um exemplo de dado, ou…Mar 18, 2022Mar 18, 2022
Rafael FelippeRegressão Linear — Linear RegressionA Regressão é um dos métodos de previsão mais utilizados no meio estatístico. Tem como principal objetivo verificar como as variáveis de…Mar 18, 2022Mar 18, 2022
Rafael FelippePré-processamento de Dados com PythonO pré-processamento de dados é um conjunto de atividades que envolvem converter dados brutos em dados preparados, ou seja, em formatos…Mar 16, 2022Mar 16, 2022
Rafael FelippeEstatística para Data ScienceA estatística é usada em quase todos os aspectos da Ciência de Dados. É usada para analisar, transformar e limpar dados, avaliar e otimizar…Mar 8, 2022Mar 8, 2022
Rafael FelippeModelo Bayesiano — Naive BayesO modelo Naive Bayes é uma técnica de classificação baseada no uso do teorema de Bayes (bastante conhecido e utilizado no universo da…Mar 7, 2022Mar 7, 2022
Rafael FelippeFloresta Aleatória — Random FlorestFloresta Aleatória (Random Forest) é um algoritmo de aprendizagem de máquina flexível e fácil de usar que produz excelentes resultados a…Mar 4, 2022Mar 4, 2022
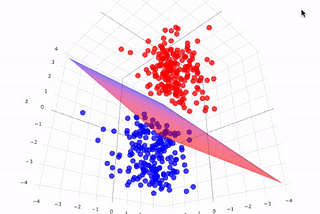
Rafael FelippeSVM — Support Vector MachineMáquina de Vetores de Suporte (Support Vectors Machine) é um algoritmo de aprendizagem de máquina utilizado tanto para classificação…Mar 3, 2022Mar 3, 2022
Rafael FelippeKNN — K Nearest NeighborsO K Nearest Neighbors (KNN) ou os K vizinhos mais próximos, traduzindo para o português, é um algoritmo de aprendizagem de máquina…Mar 3, 2022Mar 3, 2022