A Deep Dive into AI Art — Generative Art (Part 2)
Latent Spaces
Latent spaces are described as abstract, multidimensional spaces that store significant internal representations of events that have been experienced externally. In the latent space, samples that are comparable in the real world are situated close to one another. Since each witnessed event is stored in a condensed picture in the brain, human beings are able to comprehend a wide range of subjects. For instance, they don’t remember every nuance of a cat’s appearance such that one can be spot on the street. They maintain an internal model of a cat’s typical appearance. Latent space seeks to give a computer a grasp of a wide range of topics and the events associated with those topics comparable to how humans do so, through a quantitative spatial representation or modelling. Because learning the characteristics of data and streamlining data representations with the intention of identifying patterns are at the heart of deep learning, the concept of latent spaces is crucial. The reason to learn a latent space over seen data (a series of events) is that significant differences in observed space or events may be caused by minute alterations in latent space (for the same topic). Since seen data itself is a very large area to learn from, learning a latent space would help the model make sense of observed data more effectively.
Data Compression
The practice of encoding information using fewer bits than the original representation is known as data compression. There are two types of compression: lossy and lossless. By locating and removing statistical redundancy, lossless compression lowers the number of bits. Lossless compression does not result in information loss. Bits are reduced by lossy compression by excluding irrelevant or less significant data. A device that conducts data compression is typically referred to as an encoder, whereas a device that performs data decompression is referred to as a decoder.

{kind=link}
For example, if a fully convolutional neural network (FCN) is required to be trained to classify an image (that is, produce a digit number given a digit image), edges, angles, and other features are just learned at each layer as the model “learns” by associating a set of features with a certain output. However, the dimensionality of the image is initially decreased before it is finally enhanced each time the model learns from a data point. This is a type of lossy compression as the dimensionality is decreased. The model must learn to save all pertinent information and ignore noise because it must later recover the compressed data. The benefit of compression is that it enables the user to eliminate any unnecessary data and concentrate solely on the most crucial elements. The Latent Space Representation of data is what is meant by this “compressed state.”
If the original dataset contains pictures with the dimensions 5 x 5 x 1, then the compressed data point is a 3-dimensional vector since the latent space dimensions are set to 3 x 1.
Only 3 numbers are used to uniquely identify each compressed data piece. Therefore, this data can be graphed on a 3D plane. This is what “space” is being referred to.

{kind=link}
Since humans are 3-dimensional beings, n-dimensional space (where n > 3) is beyond human comprehension. In light of this, there are tools like t-SNE that can convert higher dimensional latent space representations into ones that can be visualized by the human brain (2D or 3D).
Latent Spaces in Autoencoders and Generative Models
The autoencoder, a neural network that serves as an identity function, is a popular deep learning model that modifies the ‘closeness’ of input in the latent space. To put it another way, an autoencoder picks up on how to output whatever is given as an input. The priority in the working of an autoencoder is not given to what the model outputs, which is basically the input, but rather what the model learns in the process. When a model is made into an identity function, it is compelled to store all of the data’s pertinent features in a compressed representation in order to have enough information in that compressed form for the model to “accurately” reconstruct the data. The latent space is represented by this compressed representation, as shown by the red blocks in the image illustrated.

{kind=link}
Latent Spaces and GANs
Interpolation in latent spaces can be defined as compressing and then sampling points in the latent space between two distinct clusters in the latent space to generate new results, although they might not be independent of the original data. Below is an example of linear interpolation of a latent space between 2 different types of chairs.

{kind=link}
To generate new images via a GAN, points can be sampled from a latent space. For example, by using a model decoder to rebuild the latent space representation into a 2D image with the same dimensions as the original input, various facial structures can be generated by interpolating on the latent space.

{kind=link}
Prompt Engineering
In natural language processing (NLP), a concept known as prompt engineering entails identifying inputs that produce outputs that are preferable or beneficial. In prompt engineering, the task description is included explicitly in the input, such as a question, as opposed to being provided implicitly. Typically, prompt engineering involves transforming one or more tasks into a prompt-based dataset and “prompt-based learning”, also known as “prompt learning” to train a language model. Prompt engineering, also known as “prefix-tuning” or “prompt tuning,” is a method wherein a big, “frozen” pretrained language model is used and just the prompt’s representation is learnt.
Text-based prompts may be created using prompt engineering to get the desired picture categorization results. The model may be instructed to display “a picture of potatoes,” for instance. Prompt engineering is fundamentally dependent on the form of such prompts, or the statement describing how the model detects pictures. Iterative writing is frequently necessary to come up with the finest prompt. A “snapshot of potatoes”, “a gathering of potatoes”, or the prompt “an image including potatoes” are all quite different things. The quality of the inputs influences the quality of the outputs in most processes. It’s more likely that the model will provide a constructive and relevant response when the prompts are well-designed. Understanding what the model “knows” about the world and then applying that knowledge appropriately are key to creating effective prompts.
When creating model prompts, a few key ideas should be kept in mind:
- The model is guided by a prompt to provide usable output — If a big language model with enough training data is instructed to write a summary of an article, for instance, it should be done like as illustrated below:

- To achieve the finest generations, experiment with different formulations of a prompt — When using a generator, it might be helpful to experiment with a variety of alternative prompts for the situation at hand. Even while multiple ways of phrasing the same prompt may seem similar to humans, this might result in generations that are very distinct from one another. This may occur, for example, as a result of the model’s knowledge that the various formulations are really employed in a variety of circumstances and for a variety of objectives. If “In summary” in the preceding example doesn’t provide the desired results, “To summarize altogether” or “The key takeaway from this text is that” can be used.
- Describe the assignment and the general surroundings — Additional task description elements are frequently helpful, and they usually occur after the input text that has to be processed.

Give the model sufficient context. For instance, before the article, the summarization task can be described in greater depth.

Another use case of such language models can be to help a customer satisfaction department by using them to create realistic customer answers automatically -
A customer raises the following query to a company:
Hi, I'd like a refund for the coffee maker I ordered. Would that be possible?In order to provide valuable generation for the agent working with the client, start by explaining to the model the overall situation and what the rest of the prompt will be about:
This is a conversation between a customer and a polite, helpful customer service agent.
Question of the customer: Hi, I'd like a refund for the coffee maker I ordered. Would that be possible?The model has been informed on what to anticipate, and it is evident from the query that it is a customer-related one. Next, let’s display to the model the first portion of the answer that is to be provided to the client:
Response by the customer service agent: Hello, thank you for reaching out to us. Yes,Notice how it is made apparent that the next statement is an answer to the query, that it comes from a customer service representative, and that favorable response is to be given. Combining all of this yields the following question:
This is a conversation between a customer and a polite, helpful customer service agent.
Question of the customer: Hi, I'd like a refund for the coffee maker I ordered. Would that be possible?
Response by the customer service agent: Hello, thank you for reaching out to us. Yes,
In this instance, a few customer service interactions are sufficient to obtain credible completions from the baseline model. This might be further enhanced by honing it using examples of how one wants the model to respond to different inquiries and requests.
- The preferred outcome should be shown to the model — One of the primary strategies for producing effective generations is to supplement a prompt with examples. Examples show the model what kind of outcome is being aimed for.

List a few examples to get different generations. This technique is known as few-shot learning. For example, if a movie review was to be categorized as favorable, unfavorable, or neutral, and the model is given the prompt as:
Review: "I really enjoyed this movie!"
This sentiment of this review isThe model might generate something like:
This sentiment of this review is apt, considering the movie's plot,In such a case, the model predicts certain generations that are not the kind of generations as expected.

This is a movie review sentiment classifier.
Review: "I loved this movie!"
This review is positive.
Review: "I don't know, it was ok I guess.."
This review is neutral.
Review: "What a waste of time, would not recommend this movie."
This review is negative.
Review: "I really enjoyed this movie!"
This review is positive.This prompt may be seen in a more straightforward form as shown below:

Style Transfer
Transfer Learning
A model created for one task is used as the basis for another using the machine learning technique known as transfer learning. Pre-trained models are frequently utilized as the foundation for deep learning tasks in computer vision and natural language processing because they save both time and money compared to developing neural network models from scratch and because they perform far better on related tasks. This optimization enables quick development or better performance when modelling the second task.

Transfer learning is not just a topic for deep learning research; it also deals with issues like concept drift and multi-task learning. Transfer learning, however, is often used in deep learning due to the substantial resources needed to train deep learning models or the big and difficult datasets that deep learning models are trained on. Only general model characteristics that were learnt from the initial task can be used for transfer learning in deep learning. Transfer learning is frequently used in computer vision and natural language processing applications like sentiment analysis because to the enormous amount of CPU power that is needed.
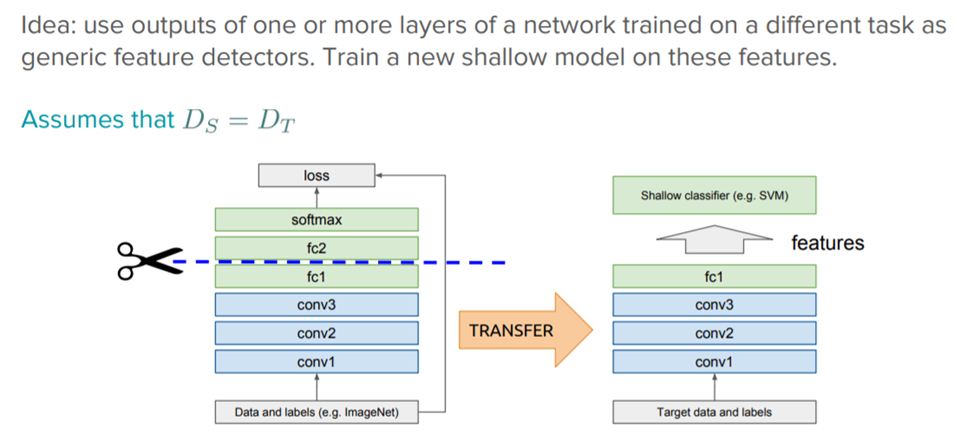
Layered architectures used in deep learning systems enable the learning of various features at various layers. Higher-level characteristics are compiled at the network’s outermost layers, and as the network gets deeper, they get more precise.
To obtain the final output, these layers are eventually linked to the final layer, which is often a completely connected layer in the case of supervised learning. This makes it possible to use well-known pre-trained networks, such as the Oxford VGG Model, Google Inception Model, and Microsoft ResNet Model for additional tasks without relying on their last layer as a fixed feature extractor.

{kind=link}
The trick here is to use the weighted layers of the trained model to extract features, but not to change the weights of the model while training with fresh data for the new task. Pre-trained models can be used to provide a broad representation of the visual world since they were trained on sufficiently big and diverse datasets.
In computer vision, neural networks generally target the first layer’s detection of edges, the middle layer’s detection of shapes, and the latter layers’ detection of task-specific properties. Transfer learning only uses the early and center layers; the later layers are only retrained. It uses the labelled data from the task that served as its training ground.

Reduced training time, enhanced neural network performance (in most cases), and the lack of a significant quantity of data are three of transfer learning’s most significant advantages. It is useful in situations when it is not always possible to get the large amounts of data required to train a neural network from scratch.

Transfer learning can provide an effective machine learning model with very minimal training data since the model has previously been trained. This is particularly helpful in NLP, where handling vast labelled datasets necessitates a high level of expertise. Additionally, training time is shortened because it might take days or even weeks to complete a complicated task after creating a deep neural network from scratch.
There are 2 common ways to implement transfer learning, they are
A Develop Model Approach involving the following steps:
- Choose the Source Task: Choose an issue involving predictive modelling that is connected, has a large amount of data, and where the input, output, and/or ideas discovered when mapping input to output data are all related in some way.
- Build the source model: The next step is to create a proficient model for this initial assignment. To confirm that any feature learning has taken place, the model must be superior to a naïve model.
- Reuse the model: A model on the second task of interest may be built from the model fit on the source task as a starting point. Depending on the modelling approach employed, this can include utilizing the entire model or only a portion of it.
- Tune the model: The model might need to be modified or improved based on the input-output pair data provided for the relevant task.
A Pre-Trained Model Approach which is frequently used in deep learning, involving the following steps:
- Choose the Source Model: One of the accessible models is a source model that has already been trained. Many research organizations publish models on sizable and difficult datasets, which may be part of the selection of potential models.
- Reuse the model: A model on the second task of interest may then be built using the pre-trained model as a base. Depending on the modelling approach employed, this can include utilizing the entire model or only a portion of it.
- Tune the model: On the basis of the input-output pair data available for the relevant task, the model may need to be modified or improved.
Transfer learning is a time-saving, expedient method of improving performance. Usually, it is not immediately apparent whether using transfer learning in the domain will be advantageous until after the model has been created and assessed. Hence, there are three advantages to seek from the use of transfer learning:
- Higher start: The initial skill on the source model (prior to model refinement) is higher than it otherwise would be.
- Higher slope: The rate of skill growth during source model training is steeper.
- Higher asymptote: The trained model’s converged skill is superior than what it would be without training.

Transfer learning may help to create expert models for some issues where there is not a lot of data available. If there is task that is similar to one’s own with a lot of data and the resources to build a model for that work and reuse it on the problem, or if there is a pre-trained model that can be used as a starting point for a new model, this approach is very much useful. The selection of the source model or data is an open problem and may call for experience-based intuition or domain knowledge.
Style Transfer
A computer vision method called style transfer enables to recompose one image’s content in the manner of another. It makes hypothetical concepts, such as what a photograph could be like if it were painted by a well-known artist, a reality. Style transfer is the process of combining two images — a content picture and a style reference image — so that the final output image keeps the essential components of the content image while also seeming to have been “painted” in the manner of the style reference image.

In the larger area of non-photorealistic rendering, style transfer is an example of picture stylization, an image processing and editing approach that has been researched for many years. An original image and an artistic rendition of that original image are needed for style transfer in a conventional supervised learning technique. A machine learning model can then use the transformation on fresh original photos after learning it.
Due of the rarity of certain picture combinations, this strategy is mostly unfeasible. Neural Style Transfer, a novel method, has altered what is achievable recently. Deep neural networks are used by NST to drive these transitions. In order to measure the effectiveness of the style transfer without the usage of explicit picture pairs, neural networks are utilized to extract statistical aspects of images that are connected to content and style. Using this enhanced method, the neural network can apply the learned style representation to original content pictures with just one style reference image. NST’s early version, though, were not without flaws. In order to execute style transfer on a single image, the challenge was approached as an optimization problem that required hundreds or thousands of repetitions. Fast neural style transfer is a method that researchers devised to address this inefficiency. While using deep neural networks, fast style transfer trains a separate model that can alter any picture in a single feed-forward pass. Instead of using hundreds of iterations via the network, trained models can stylize any image. Modern-day style transfer models even have the capability of learning to imprint several styles using a single model, allowing for the creative editing of a single input content image in an almost limitless number of ways.
Working of Style Transfer
Convolutional neural network (CNN) variants serve as the foundation for deep learning architectures that are appropriate for style transfer. Making important contrasts between various techniques can be accomplished by following the development of style transfer research. Examining the ongoing advancement of these methodologies and optimizations, from single- and multiple-style model approaches to arbitrary-style model approaches, can help in comprehending the potential of style transfer.
- Basic Framework — A pre-trained feature extractor and a transfer network are required for training a style transfer model. To avoid using paired training data, a feature extractor that has already been trained is employed. Its utility arises from a certain propensity of individual deep convolutional neural network layers trained for image classification to specialize in comprehending particular aspects of a picture.

- Some layers learn to focus on texture (the small brush strokes of a painter or the fractal patterns of nature), while others learn to extract the image’s information (such as a dog’s shape or a car’s location). This is taken advantage of by style transfer, which processes two photos through a pre-trained neural network, examines the output at various levels, and assesses how similar the two images are. Images that give identical outputs at different layers of the pre-trained model indicate comparable content while matching outputs at the same layer indicate similar style.
- Despite not directly assisting in producing the styled picture, the pre-trained model helps to compare the content and style of two photos. A second neural network, referred to as the transfer network, is responsible for it. The transfer network is a network that translates images, taking one picture as input and producing another image as output. In transfer networks, an encoder-decoder design is very common.

- The pre-trained feature extractor is first applied to one or more style pictures, and the outputs at different style layers are stored for further comparison. The machine is then given content pictures. The pre-trained feature extractor runs through each content picture, saving results at different content layers. The transfer network then generates a stylized version of the content picture. The feature extractor is likewise applied to the styled picture, and outputs at the content and style layers are stored.
- The unique loss function that determines the stylized image’s quality includes keywords for both content and style. While the extracted style aspects are contrasted with those from the reference style picture, the content features from the stylized image are compared to the original content image (s). Only the transfer network is updated following each step. The pre-trained feature extractor’s weights remain constant throughout. Models can be trained to generate output pictures with lighter or greater stylization by weighing the various elements of the loss function.
Overview of some of the Model Architectures — To showcase a few robust and reliable ones:
- Single style per model: The first independent neural network to be trained to stylize pictures in a single feed-forward pass was introduced in a 2016 paper by Johnson et al. The feature extractors are large VGG16 models pre-trained on ImageNet, whereas the transmission network is a relatively tiny encoder-decoder network. A separate transfer network is trained for each desired style in this method.
- Multiple styles per model: Researchers at Google expanded the quick style transfer method in 2017, one year after it was first released, to enable a single transfer network to create pictures in many styles and even blend numerous styles together. The inclusion of “conditional instance normalization” layers inside the network, which allowed the stylized picture generated to be conditioned on a different model input, was their significant contribution. These networks accept as input a content picture and a second vector that instructs them how much of each style to apply to the input image. So, a model may, for instance, be trained on works by van Gogh, Picasso, and Matisse. The user can enter [1, 0, 0] for van Gogh, [0, 1, 0] for Picasso, or [0.33, 0.33, 0.33] for a combination of all three when it comes time to stylize an image. This is a wonderful method since it eliminates the need to train and store several models for various styles and gives users the ability to combine various styles.
- Arbitrary styles per model: Both single-style transfer models and multi-style transfer models have the ability to only create pictures in the styles they have previously seen during training. Without retraining the whole network, a model created using van Gogh’s artwork cannot create artwork similar to Picasso’s. That is altered by Huang and colleagues’ arbitrary style transfer. Arbitrary style transfer models accomplish style transfer in a single, feed-forward pass using a content picture and a style image as input. In essence, the model learns how to instantly extract and apply any style to a picture.
- Extensions and optimizations for style transfer. A few enhancements and optimizations of style transfer are important to note:
Stable style transfer comes first. A substantial degree of flickering would be present in the output of a style transfer model that had been trained before being applied to video frame by frame. Distracting temporal inconsistencies can be introduced into a video by even little frame-to-frame variations and noise. A soccer ball, for instance, could change color while in flight. Stable style transfer models address this issue by introducing a new loss term linked to “temporal coherence”, which compares the stylization of two consecutive frames in order to train the model to apply the same stylization to an item as it moves across the frame.
Color preservation is another aspect of style transfer. In certain instances, one may want to reproduce an artist’s brushstrokes on a picture while keeping the original palette’s colors. The input picture representation from RGB to another color space and applying style transfer exclusively to the luminance channel or using a color transfer algorithm to the final styled image are two methods that may be used to accomplish this.
Lastly, though the majority of the style transfer use cases stated so far have added an aesthetic style to a picture image, it is also feasible to transmit other heuristics, like weather or time of day, between two photorealistic photographs. In order to eliminate artefacts brought about by deep convolution and upsampling layers, photorealistic style transfer often necessitates adjustments to the encoder-decoder transfer network.
Importance of Style Transfer
Not everyone is naturally creative. Some people are better at skills requiring touch or words. However, because to recent developments in technologies like style transfer, practically anybody may now experience the delight that comes from making and appreciating a work of art. This is where style transfer has the ability to transform. Artists are able to readily share their aesthetic sensibility with others, allowing for the coexistence of fresh and creative interpretations of many artistic movements with classic works of art. In addition to encouraging people all over the world to explore their own creativity, style transfer is crucial to the world of commercial art. An example is Christie’s recently showcased painting created by AI that fetched more than $430,000 at one of their auctions.
Style transfer is now possible for recorded and live video because to advancements in AI-accelerated technology in the cloud and on the edge. The possibilities for design, content creation, and the advancement of creative tools are unlimited thanks to this new capability.
Here’s the link to the next article: A Deep Dive into AI Art — Platforms for Generative Art (Part 1)