Ensemble Techniques
Many a times we get stuck in some situations and we are not able to think what we should do. So we decide to consult our friends, family etc. And what every the majority votes for, we go with that call. Same things happen in a parliament where the decision is taken on the basis of majority vote. The group of decision make is called as ensemble and the technique is called as an Ensemble Technique. So to put this a bit technically, we try to use multiple instanced of a same algorithm and go with the majority result or we can have multiple instances of multiple models to make a decision.

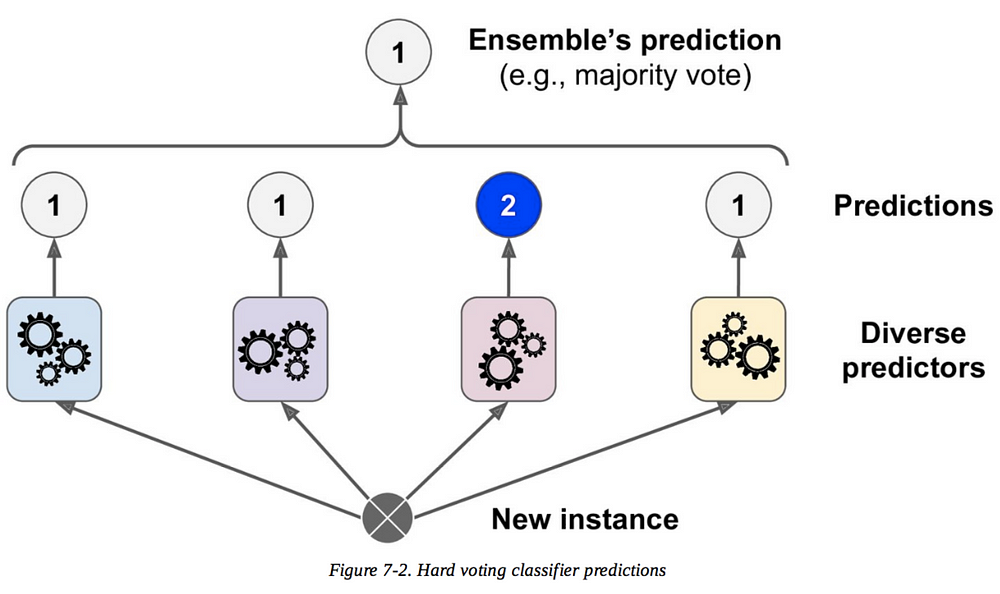{kind=link}
Bagging
In this technique, we use multiple decision makers and then take the average or mode. In bagging, we take the samples with replacement from the dataset and then pass it to the model. The individual models have a higher bias, but when all models combined together results in low bias and variance. Models which can be included in bagging approach are
· Random Forest
· K Nearest Neighbor
· Naïve Bias
· Decision Trees
· Support Vector Machines
The most popular bagging technique is using Random forest.
Random Forest
Random forest is an ensemble of decision trees trained via bagging approach. Here we take multiple decision trees and make a forest of trees. Random Forest allows extra randomness when growing trees. Instead of looking for the best feature for the split, it looks a best feature out of the random subset of the features. This results in a more diversification of trees.
It is indeed one of the best classification technique.

Multiple trees are constructed and predictions are run. After that poll is taken and the class with maximum number of polls is selected.
K Nearest Neighbor
It is also classification technique based on calculation of distances between the points. The value of k is chosen let’s say 3 and distance between all the points and the new point is calculated. Then we look for the nearest k points (in this case 3) and then their labels are checked. The majority class in those 3 points will be the class of the new point. Here the most important question is how to choose the value of k?
The value of k is chosen by GridSearchCV. If the value chosen is too low, the results will be biased and if chosen too high will again give biased results.
Note: This technique is called as Lazy Learner as it never learns from the data but every time computes the distance between the points which makes it a very resource expensive algorithm. If the dataset is too huge, it is not going to work. So most commonly, we use this technique for missing value imputations.

Support Vector Machines
In this we try to separate two or more classes using a hyper plane. The line is drawn between the margins. The aim in classification is to maximize the margins as much as possible. In regression, we try to minimize the margins. The data points on the margins are called as support vectors.
SVMs are very sensitive to feature scales. More accuracy can be achieved by hyper parameter tuning. There is a wide variety of kernels available such as linear, poly , rbf etc.
If the dataset is n dimensional, we will try to fit the line in a higher dimension. If the support vector machine in over fitted, it can be regularized by changing the hyper parameter more specifically c.

Boosting
It is a technique in which we try to convert weak learners to strong learners. The intuition behind this is to train models sequentially. So in this algorithm, we start with a weak learner do the predictions and pass those predictions to the next model. This approach is repeated till the desired output is achieved. Models which can be included in boosting approach are
· AdaBoost
· Gradient Boost
· XgBoost
AdaBoost
In this algorithm, we try to give more importance to the training instances that the preceding model under fitted. This will result in a more accurate prediction as more focus is given to the extreme cases.
· Firstly weights are calculated of all the rows (wi = i/N)
· Decision is made using the model.
· Error is calculated
· Compute α = ½(log(1 — error)/error)
· Calculate the new weights wi = wi exp[α * I(predicted not equal to expected output)]
· Normalize the weights to summation of 1
· Construct the nest model.
For example we take a data of 10 rows. We train our first model and try to get the output. After this we calculated our loss function in which we saw that 1st, 5th and 9th row output is not correct. So this time we will calculate weights and more weights will be given to these rows so that they can perform well.
Note: There is a one very important drawback of this approach is that it a sequential approach not a parallel one. Which means that the next execution will only start when the previous has ended. This result in Boosting technique not to be a scalable approach.
We use argmax function in case of output in regression and sigmoid for classification.

{kind=link}
Gradient Boosting
This is also a sequential approach in which the previous model corrections are done in the subsequent models. In this approach, the weights are calculated using gradient.
New weights = Old weights + — Learning Rate * Residual
Residual = Actual Label — Predicted Label
This step is repeated again and again till the residuals are minimized. Learning rate is a hyper parameter which can be decided using the GridSearchCV.
