
Databricks Liquid Clustering
Have you ever wondered if there’s a dynamic solution to the relentless challenge of data partitioning in the world of data lakehouses?
Well, I did! So let’s talk about it.
The Challenge of Fixed Data Layouts
Have a look at this graph.

This graph projects yearly row counts for a table & reveals a significant skew in data distribution. This skew is particularly relevant as consumers frequently employ the year column as a filter in their queries.
This table, when created, was partitioned using year and month columns. This is how the DDL looks like for this one.
%sql
CREATE TABLE kaggle_partitioned (
year_month STRING,
exp_imp TINYINT,
hs9 SMALLINT,
Customs SMALLINT,
Country BIGINT,
quantity BIGINT,
value BIGINT,
year STRING,
month STRING
) USING delta PARTITIONED BY (year, month);The problem here is, that 2 partitions have ~83% of the total data for the table.

Based on the information provided above, do you think the table is under partitioned? Or is over partitioned?
Let’s look at the data distribution in further depth for this table. The following chart present the monthly split for each yearly row counts.

Slicing the pictorial representation of data distribution further, 2020 has most data in March, with Jan and Feb following the suite, followed with a trail of smaller partitions for other months.
So, is the table over-partitioned? Or under partitioned? Or both?
Does the following picture rings any bell? Makes any sense?

With the current partitioning strategy,
- For partitions like 2020–03, you might end up reading a huge amount of data to query, say, just one hour’s worth of data.
- On the completely other end of spectrum, I may need to span across multiple partitions and scan many small files to serve a query which is for a customer with not a lot of data.
- Lastly, if I need to repartition my table by week/day/month, you’d need to rewrite the entire table. AGAIN!
Now let’s discuss the data write scenarios in my table. I think the picture summarizes the point I am trying to make and I don’t need to type it in the article ;)

Now! Let’s repeat the very first line of this article again!
Have you ever wondered if there’s a dynamic solution to the relentless challenge of data partitioning in the world of data lakehouses?
Enters Liquid Clustering! It simplifies data layout decisions and enhances query performance, all without demanding constant monitoring and adjustments.
So how does it do it?
- Fast: Faster writes and similar reads vs. well-tuned partitioned tables
- Self-tuning: Avoids over- and under-partitioning
- Incremental: Automatic partial clustering of new data
- Skew-resistant: Produces consistent file sizes and low write amplification
- Flexible: Want to change the clustering columns? No problem!
- Better concurrency: Enables Row-Level concurrency on your tables.
Let’s understand it in a bit more detail. I will use the sample layout diagram from earlier.
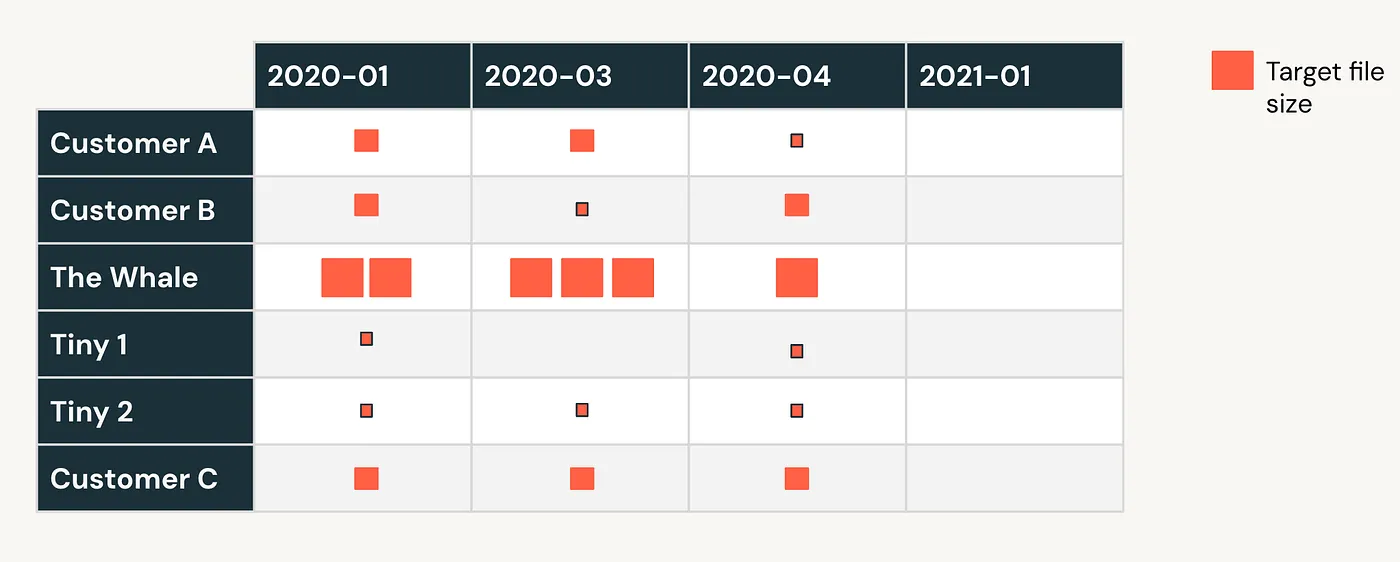
So how does Liquid Clustering helps here? See for yourself below! Liquid Clustering efficiently balance clustering vs. file size

Not only does it automatically handles the smaller partitions, a heavier partition would be subdivided for a more efficient query if one wants to fetch only hourly data from a large partition
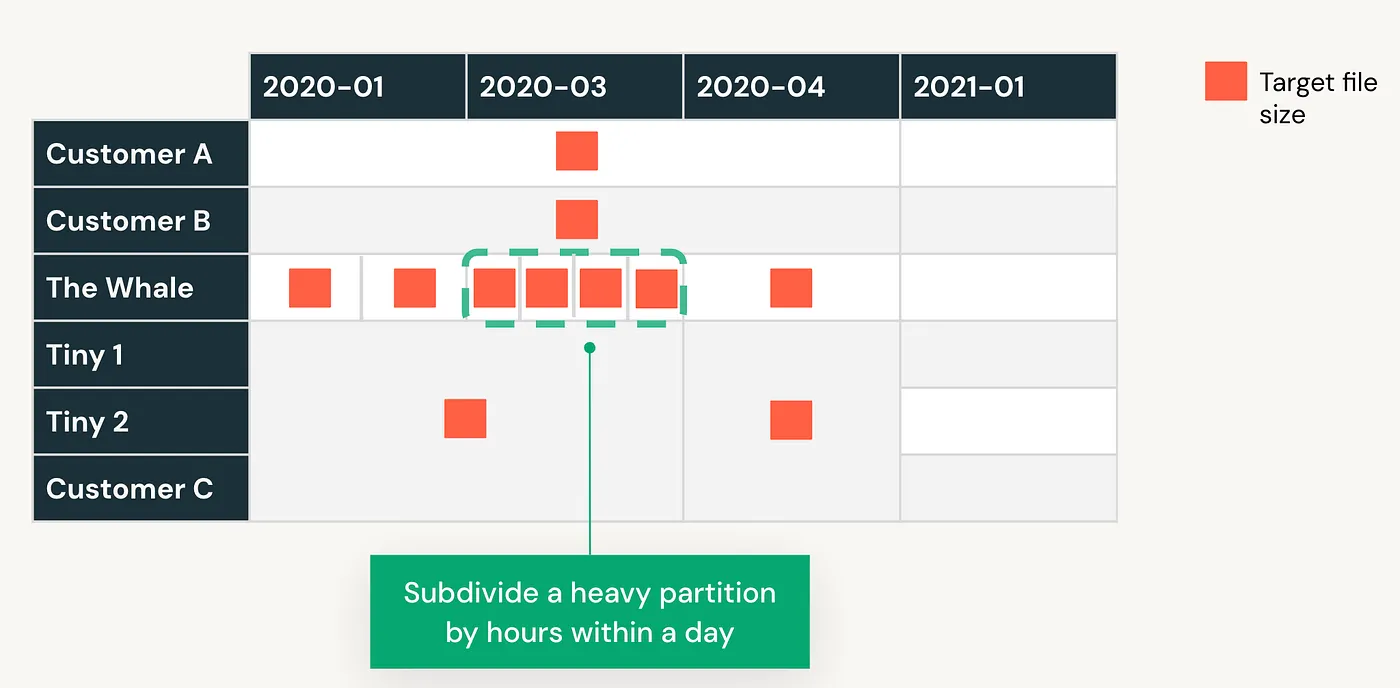
Let’s see it in action! Here’s the file size distribution for the partitioned table.

Let’s create a clustered table from this partitioned table. We’ll use CTAS.
CREATE TABLE kaggle_clustered CLUSTER BY(year, month) AS
SELECT
*
FROM
kaggle_partitioned;And here’s the file size distribution for the clustered table.

It’s clearly evident that most of the smaller files have been merged together to create more optimized files.
Note
Both the tables have
OPTIMIZErun on them.
Liquid Clustering also aids with ingestion by leveraging partial/lazy clustering to make it more efficient.
Let’s understand how.
- 2021–01 is a partition where I don’t have any data in my partitioned table.
- As one will start to ingest the data for that date range, one file will be created covering all the customers.
- As the data set starts to grow, Liquid Clustering will start to split files for customers.
- The split operation will result in smaller files intermittently but the table maintenance will automatically merge those smaller files into larger ones, making sure the read performance is not impacted.
So! How do I use it in my tables?
Heads up! Databricks Runtime 13.3 LTS and above is required to create, write, or
OPTIMIZEDelta tables with liquid clustering enabled.
First thing first! Clustering is not compatible with partitioning or ZORDER, and requires that the Databricks client manages all layout and optimization operations for data in your table.
Now let’s see how can you create a Delta table with Liquid Clustering.
--Create an empty table
CREATE TABLE table1(col0 int, col1 string) USING DELTA CLUSTER BY (col0);
--Using a CTAS statement
CREATE EXTERNAL TABLE table2 CLUSTER BY (col0) --specify clustering after table name, not in subquery
LOCATION 'table_location' AS
SELECT
*
FROM
table1;
--Using a LIKE statement to copy configurations
CREATE TABLE table3 LIKE table1;Note
Tables created with liquid clustering enabled have numerous Delta table features enabled at creation and use Delta writer version 7 and reader version 3. Table protocol versions cannot be downgraded, and tables with clustering enabled are not readable by Delta Lake clients that do not support all enabled Delta reader protocol table features. See How does Databricks manage Delta Lake feature compatibility?
How to trigger clustering
Simply use the OPTIMIZE command on your table. See the example below.
OPTIMIZE table_name;Liquid clustering is incremental, so data is only rewritten as necessary to accommodate data that needs to be clustered. Data files with clustering keys that do not match data to be clustered are not rewritten.
You should run regular OPTIMIZE jobs to cluster data and hence achieve the best performance. Because liquid clustering is incremental, most OPTIMIZE jobs for clustered tables run quickly.
What is liquid clustering used for?
As per Databricks documentation, it is recommended to use liquid clustering for all new Delta tables. The following are examples of scenarios that benefit from clustering:
- Tables often filtered by high cardinality columns.
- Tables with significant skew in data distribution.
- Tables that grow quickly and require maintenance and tuning effort.
- Tables with concurrent write requirements.
- Tables with access patterns that change over time.
- Tables where a typical partition key could leave the table with too many or too few partitions.
Things to consider when using Liquid Clustering
- You can only specify columns with statistics collected for clustering keys. By default, the first 32 columns in a Delta table have statistics collected.
- You can specify up to 4 columns as clustering keys.
- Structured Streaming workloads do not support clustering-on-write.
