
DCGAN Implementation in Keras explained
I started reading GAN (Generative Adversarial Networks) related papers recently. I am fascinated about this new path-breaking technology in the field of computer vision. To make my understanding deeper about the implementation, I am going through the DCGAN (Deep Convolutional Generative Adversarial Networks) code.
This is the code I am trying to understand:
Original DCGAN paper: https://arxiv.org/pdf/1511.06434.pdf
This is my understanding of DCGAN implementation in Keras. Anybody is welcome to correct if there is a gap in the explanation or my understanding.
Code has 6 main blocks:
- Load and Prepare dataset
- Generator
- Discriminator
- Generator/Discriminator loss
- Optimizer
- Train
Load and Prepare Dataset
MNIST (Handwritten digits) dataset is used for training the model. This is an image dataset and has 60,000 training examples and 10,000 test examples of handwritten digits. Images are in greyscale and of 28x28 pixel. Each pixel value ranges from 0 to 255, where 0 is black and 255 is white background.
First, images are reshaped into a tensor of shape (60000x28x28x1) and then normalized to have values in the range [-1,1].
train_images = train_images.reshape(train_images.shape[0], 28, 28, 1).astype('float32')
train_images = (train_images - 127.5) / 127.5 # Normalize the images to [-1, 1]train_images (60,000) are then shuffled and batched into batches of size 256.
train_dataset = tf.data.Dataset.from_tensor_slices(train_images).shuffle(BUFFER_SIZE).batch(BATCH_SIZE)Generator
Generator takes a noise vector of dimension 100 as input and generates an image of size 28x28x1.


The above block diagram gives a detailed view inside a generator. The noise vector z is fed into a fully connected layer with 7x7x256 (12544)hidden units. The output of fully connected layer is input into Leaky ReLu activation function and Batch Normalization.
The output is then reshaped into a tensor of size 7x7x256. This is input to a Conv2DTranspose (upsampling) with the following features:
128 filters of size 5x5x256, with (1,1) strides, “same” padding* and bias=0
*”same” padding keeps the output size same as the input size when stride =(1,1).
The output of this block is a tensor of size 7x7x128. This is then passed through LeakyReLu and batch normalization. The output is then fed to another Conv2DTranspose with the following features:
64 filters of size 5x5x128, with (2,2) strides, “same” padding and bias =0
The output of this block is a tensor of size 14x14x64.
Note: Formula for calculating output dimension for different strides is:
for `tf.layers.conv2d_transpose()` with `SAME` padding:
out_height = in_height * strides[1]
out_width = in_width * strides[2]
The tensor 14x14x64 is again given as input to Leaky ReLu and Batch Normalization. The output is then input to another Conv2DTranspose with the following features:
1 filter of size 5x5x64, with (2,2) strides, “same” padding and bias =0
The output is of size 28x28x1. It is input to a tanh activation to obtain a generated image.
Discriminator
Discriminator takes real and fake images as input and predicts if the image is fake or real. Ideally, the discriminator should predict 0 for fake image and 1 for the real image.
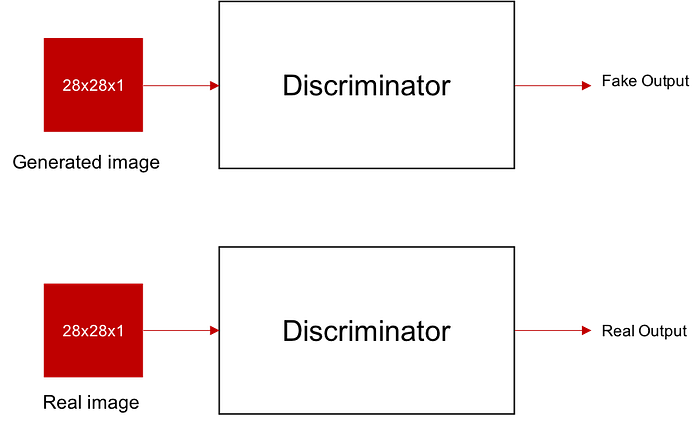

Image (generated/real) is given as input to a Conv2D with the following features:
64 filters of size 5x5x1, (2,2) strides, “same” padding and bias=0
The output (14x14x64) is fed into a Leaky ReLu activation function and dropout with a rate of 0.3. The output from the dropout is fed into another Conv2D with following features:
128 filters of size 5x5x64, stride (2,2), “same ” padding and bias=0
The output (7x7x128) is fed into Leaky ReLu and dropout with a rate of 0.3 and then flattened into a vector of size 6272(7x7x128=6272) which is given as input to to fully connected layer with one hidden unit. The output of the fully connected layer is the discriminator output.
Generator/Discriminator Losses


Optimizer
Adam Optimizer with learning rate 0.0001 is used for optimization.
Train
•EPOCHS = 50
•Z = 100
•Batch size = 256
For each epoch:
For each batch (256 images) in images (60K images):
- Generate noise vectors of dimension 100
2. Generate fake images using noise vectors
3. Input fake images to discriminator to get fake_output
4. Input real images to discriminator to get real_output
5. Calculate generator loss gen_loss
6. Calculate discriminator loss disc_loss
7. Update gradients to minimize the loss values
Going through this code gave me a better understanding of DCGAN. I hope to improve further through more practice!!
Thanks for reading :)
References:
DCGAN paper: https://arxiv.org/pdf/1511.06434.pdf
Activation Functions: https://towardsdatascience.com/activation-functions-neural-networks-1cbd9f8d91d6
Convolution Neural Network : http://cs231n.github.io/convolutional-networks/
Adam Optimizer: https://arxiv.org/pdf/1412.6980.pdf
