TF-IDF from scratch with Python
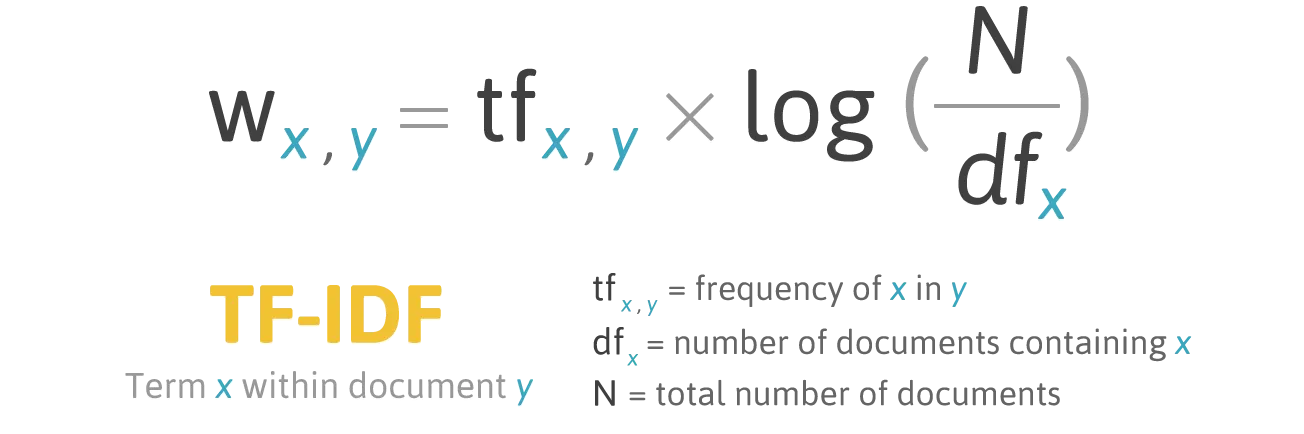
TF-IDF stands for term frequency-inverse document frequency. It is a statistical measure used to evaluate how important a word is to a document in a collection or corpus. The TF-IDF weight of a word is proportional to the number of times it appears in the document but is offset by the frequency of the word in the corpus.
In this blog post, we will implement the TF-IDF vectorizer from scratch using Python.
Preprocessing the Text
Before we begin, we need to preprocess the text by removing punctuation, converting all text to lowercase, and removing stop words. We can use the nltk library to do this.
import string
from nltk.corpus import stopwords
from nltk.tokenize import word_tokenize
def preprocess_text(text):
# Remove punctuation
text = text.translate(str.maketrans('', '', string.punctuation))
# Convert to lowercase
text = text.lower()
# Tokenize the text
words = word_tokenize(text)
# Remove stop words
words = [word for word in words if word not in stopwords.words('english')]
return wordsBuilding the Corpus
corpus = [
"This is the first document.",
"This document is the second document.",
"And this is the third one.",
"Is this the first document?",
]Calculating TF-IDF
Now, we can calculate the TF-IDF values for each word in each document. To do this, we will first calculate the term frequency (TF) of each word in each document. We will then calculate the inverse document frequency (IDF) of each word in the corpus. Finally, we will multiply the TF and IDF values to get the TF-IDF value for each word in each document.
from collections import Counter
from math import log
from scipy.sparse import csr_matrix
from sklearn.preprocessing import normalize
class tfidf_vectorizer():
def __init__(
self,
data_corpus = [],
top_imp_words = None
):
self.idf_ = dict()
self.feature_names = []
self.feature_names_in_each_doc = []
self.top_imp_words = top_imp_words
self.corpus_size = len(data_corpus)
self.data_corpus = [doc.lower() for doc in data_corpus]
def extract_features_from_text(self):
# looping through data_corpus, to get a list of unique words at a document level.
for each_document in self.data_corpus:
self.feature_names.extend(list(set(each_document.split()) - set(self.feature_names)))
self.feature_names_in_each_doc.extend(list(set(each_document.split())))
self.feature_names = sorted(self.feature_names)
def count_frequency_of_feature(self, ):
# counting number of documents which have a specific word in them
return dict(Counter(self.feature_names_in_each_doc))
def calculate_idf_of_each_feature(self, freq_of_feat):
return dict([(feat, 1+log((1+self.corpus_size)/(1+freq))) for feat, freq in freq_of_feat.items()])
def fit(self,
data_corpus,
top_imp_words = None):
self.__init__(data_corpus,
top_imp_words)
self.extract_features_from_text()
freq_of_feat = self.count_frequency_of_feature()
self.idf_ = self.calculate_idf_of_each_feature(freq_of_feat)
if not top_imp_words: top_imp_words = len(self.feature_names)
self.idf_ = dict(sorted(self.idf_.items(),
key = lambda kv: kv[1],
reverse = True)[:top_imp_words])
self.feature_names = sorted(list(self.idf_.keys()))
self.idf_ = dict([(feat, (self.idf_.get(feat), dim)) for dim, feat in enumerate(self.feature_names)])
def transform(self,
dataset):
doc_index = []; tf_idf = []; dimension = []
for index, each_doc in enumerate(dataset):
leng_of_doc = len(each_doc)
word_freq_in_doc = dict(Counter(each_doc.split()))
for word in each_doc.split():
if self.idf_.get(word):
idf, dim = self.idf_.get(word)
doc_index.append(index)
dimension.append(dim)
tf_idf.append((word_freq_in_doc.get(word)/leng_of_doc)*idf)
temp = csr_matrix((tf_idf, (doc_index, dimension)),
shape = (len(dataset), len(self.idf_)))
return normalize(temp)
def fit_transform(self,
data_corpus,
top_imp_words = None):
self.fit(data_corpus,
top_imp_words)
return self.transform(data_corpus)Conclusion
In this blog post, we implemented the TF-IDF vectorizer from scratch using Python. We first preprocessed the text by removing punctuation, converting all text to lowercase, and removing stop words. We then built a corpus of documents and calculated the TF-IDF values for each word in each document. Finally, we represented each document as a vector in the TF-IDF space using a TF-IDF matrix. The TF-IDF vectorizer is a powerful tool for natural language processing and can be used for various tasks, such as clustering, classification, and information retrieval.
