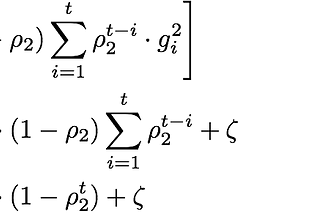Published inKonvergen.AIUnderstanding DropoutOne particular layers that are useful, yet mysterious when training neural networks is Dropout. Dropout is created as a regularization…Jul 21, 20192Jul 21, 20192
Published inKonvergen.AICross-entropy and Maximum Likelihood EstimationSo, we are on our way to train a neural network model for classification. We design our network depth, the activation function, set all…Feb 16, 20197Feb 16, 20197
Published inKonvergen.AIFinding the Minimum: Escaping Saddle PointsWhen I did my weekly Arxiv chores (via arxiv-sanity.com, which is a great site! Thanks Andrej Karpathy), I stumbled across this paper by Du…Nov 18, 2018Nov 18, 2018
Published inKonvergen.AIAdaptive Method Based on Exponential Moving Averages with Guaranteed Convergence ; AMSGrad and…From all optimization algorithms that we have covered in this series, Adam and RMSProp are very popular among Deep Learning practitioner…Jul 21, 2018Jul 21, 2018
Published inKonvergen.AIModifying Adam to use Nesterov Accelerated Gradients: Nesterov-accelerated Adaptive Moment…On the previous post, we have discussed Adam algorithm, which could be seen as the way to combine the advantage of Momentum method and…Jun 24, 2018Jun 24, 2018
Published inKonvergen.AIAccelerating the Adaptive Methods; RMSProp+Momentum and AdamOur last post discussed two other adaptive algorithms which are an extension to the Adagrad algorithm, i.e., Adadelta and RMSProp. As we…May 21, 20181May 21, 20181
Published inKonvergen.AIContinuing on Adaptive Method: ADADELTA and RMSPropIn our last post, we have discussed the difficulties of setting the learning rate hyper-parameter, which can be mitigated by using the…May 4, 2018May 4, 2018
Published inKonvergen.AIAn Introduction to AdaGradWe have discussed several algorithms in the last two posts, and there is a hyper-parameter that used in all algorithms, i.e., the learning…May 3, 20184May 3, 20184