PinnedRitvik RastogiThanks for the appreciation, Its surreal for me to get acknowledged from the author itself.1 min read·Feb 1, 2024----
Ritvik RastogiPapers Explained 147: LongLoRALongLoRA is an efficient fine-tuning approach that extends the context sizes of pre-trained LLMs, with limited computation cost.4 min read·9 hours ago----
Ritvik RastogiPapers Explained 146: QLoRAQLoRA is an efficient finetuning approach that reduces memory usage for fine-tuning hplarge models on a single GPU while preserving full…6 min read·2 days ago----
Ritvik RastogiPapers Explained 145: LoRALow-Rank Adaptation or LoRA freezes the pretrained model weights and injects trainable rank decomposition matrices into each layer of the…5 min read·4 days ago--1--1
Ritvik RastogiPaper Explained 144: Granite Code ModelsThis paper introduces a series of decoder-only code models (3B, 8B, 20B, 34B) for code generative tasks, trained with code written in 116…10 min read·May 31, 2024----
Ritvik RastogiPapers Explained 143: ChameleonChameleon is a family of early-fusion token-based mixed-modal models capable of reasoning over and generating interleaved image-text…8 min read·May 29, 2024----
Ritvik RastogiPapers Explained 142: Gemini 1.5 FlashThe tech report introduces two new models: Gemini 1.5 Pro and Gemini 1.5 Flash.16 min read·May 27, 2024----
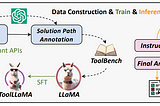
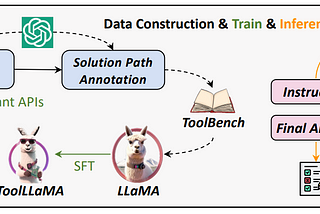
Ritvik RastogiPapers Explained 141: Tool LLMOpen-source LLMs struggle with tasks that require interaction with external tools or APIs, to address this limitation, this paper…6 min read·May 24, 2024----
Ritvik RastogiPapers Explained 140: ToolformerToolformer is a model trained to decide which APIs to call, when to call them, what arguments to pass, and how to best incorporate the…6 min read·May 22, 2024----
Ritvik RastogiPapers Explained 139: GorillaGorilla is retrieve-aware finetuned LLaMA-7B model, specifically for API calls. It substantially mitigates the issue of hallucination…6 min read·May 20, 2024----