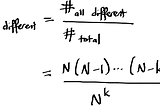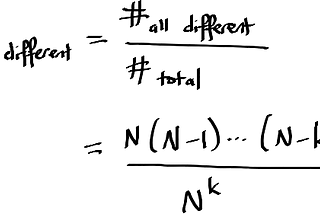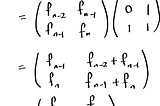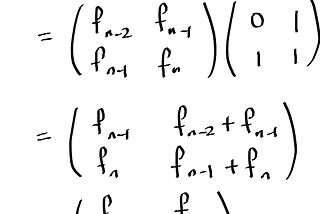Elliott JininUX Collective3D worlds and the future of UX: A review of “spatial interfaces”“Games and entertainment have pointed us toward a new way of thinking about interacting with software: spatial interfaces.”Aug 12, 20211Aug 12, 20211
Elliott JinRemoving foreground clutter from landscape scenesLandscape photography is tricky when fast moving foreground objects (people, cars, etc.) clutter the background scene. Especially when…Jul 5, 2018Jul 5, 2018
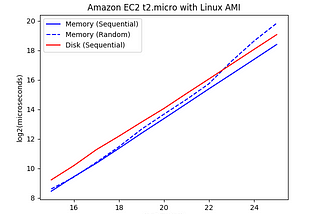
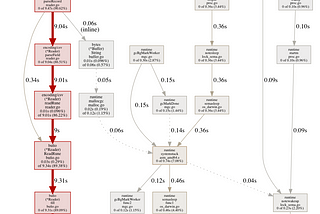
Elliott JinDisk can be faster than memoryConventional wisdom says that “disk is slow and memory is fast”, but the Kafka documentation mentions that this isn’t nuanced enough…Mar 24, 20182Mar 24, 20182
Elliott JinGoroutines and Channels Aren’t FreeI used to think the performance overhead of goroutines and channels is basically negligible — especially when compared to things like IO —…Feb 22, 20181Feb 22, 20181
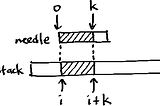
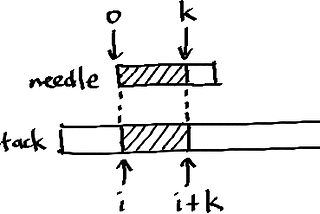
Elliott JininPython PandemoniumThat one string matching algorithmI’ve come across the Knuth-Morris-Pratt (or KMP) string matching algorithm several times. Every time, I somehow manage to forget how it…Jan 30, 2017Jan 30, 2017
Elliott Jin“Unique” IDs and birthday problemsI recently had to convince someone that generating “unique” IDs by (pseudo)randomly choosing numbers between 1 and 1,000,000,000 is a Bad…Jan 21, 2017Jan 21, 2017
Elliott JinLogarithmic time FibonacciWe can compute the n-th Fibonacci number with only a logarithmic number of arithmetic operations! While I can think of zero practical…Jan 17, 2017Jan 17, 2017