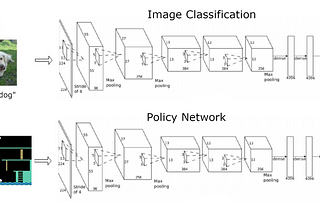
Roei BahumiReinforcement Learning — A mathematical introduction to Policy GradientRL Policy Gradient (PG) methods are model-free methods that try to maximize the RL objective directly without requiring a value function…Jun 2, 2020Jun 2, 2020
Roei BahumiDeep Learning — Cross Entropy Loss DerivativeIn this article, I will explain the concept of the Cross-Entropy Loss, commonly called the “Softmax Classifier”. I’ll go through its usage…Oct 28, 2019Oct 28, 2019
Roei BahumiKeras — serving a Keras model quickly with TensorFlow Serving and DockerThe purpose of this blog post:Jun 29, 2019Jun 29, 2019
Roei BahumiKeras — Regression with categorical variable embeddingsImplement a feature vector with both continuous and categorical features and use a Regression head to predict continuous values.Jan 25, 2019Jan 25, 2019