RozenChenSub-Image Anomaly Detection with Deep Pyramid Correspondences 論文筆記Medium放着快兩年了,現在開始爲碩論做實驗,決定把這些看過且比較重要的paper都心得都記錄下來。Aug 13, 2021Aug 13, 2021
RozenChen第一次投稿conference心得研究,是一件很深奧的事情。需要專業的基礎還有一點小小的運氣,導致很多人望之卻步。在各個學術組織每年舉辦的conference中會有一個投稿項目叫做poster paper和short…Mar 14, 2020Mar 14, 2020
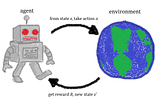
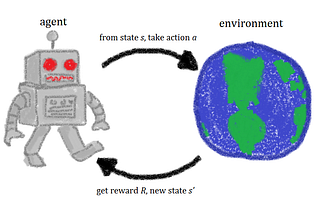
RozenChenCuriosity-driven Exploration by Self-supervised Prediction 論文筆記Reinforcement Learning 是目前Deep Learning 一個學派,利用Agent 與環境互動產生的reward 來讓Training Agent。 如果我們不去定義reward,Agent 會面臨到一個問題:Agent…Jan 29, 2019Jan 29, 2019
RozenChenPolicy GradientBlog 又放了快2個月沒更新了,其實很早以前已經把 MDP Monte Carlo 弄懂了,Monte Carlo 跟 Temporary Error 在估算Loss 有非常大的不同,TD error是在估算每一步的價值而MC 則是計算整個 Episode…Dec 9, 2018Dec 9, 2018
RozenChenDeep Q learning前幾天實踐了Policy Gradient .嘗試了Monte Carlo Evaluation去更新網路,發現在 Health_gathering 有一個不錯的表現,可以看出他學出來的策略……看來不用CNN也能達到相同效果阿(走四角形,這四角形有極大機率會再吃到補包)Oct 4, 2018Oct 4, 2018
RozenChenQ-Learning最近終於將neural network 結合 強化學習弄個清楚了,我參考了Vizdoom 給的範例利用 CNN作為神經網路,然後利用q-learning做反向傳播修正 . 在basic這張地圖看起來有不錯的成績.Sep 30, 2018Sep 30, 2018
RozenChenRL 三個月學習的一些小心得及碎碎念Blog 又放了快一個月都沒有寫了. 這段時間終於拿到了實習學分,每天過著上班寫code 下班看論文的日子(還要感謝公司願意贊助我一台電腦做研究用……超級佛心的).這篇文章沒有任何技術探討,只有我對強化學習(Reinforcement Learning)的一些看法.Sep 19, 2018Sep 19, 2018
RozenChenMarkov Decision Process(下)上一篇 Markov Decision Process (上)已經把 Markov Reward Process介紹完了,這次我們要來正式開始解釋 MDP 到底是什麼。Aug 19, 2018Aug 19, 2018