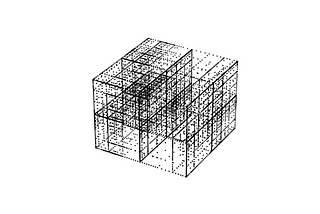
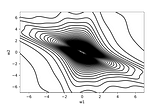
Ryan BurninTowards Data ScienceHow to Efficiently Approximate a Function of One or More VariablesUse sparse grids and Chebyshev interpolants to build accurate approximations to multivariable functions.Jun 282Jun 282
Ryan BurninTowards Data ScienceIntroduction to Objective Bayesian Hypothesis TestingHow to Derive Posterior Probabilities for Hypotheses using Default Bayes FactorsJun 11Jun 11
Ryan BurninTowards Data ScienceAn Introduction to Objective Bayesian InferenceHow to calculate probability when “we absolutely know nothing antecedently to any trials made” (Bayes, 1763)Apr 233Apr 233
Ryan BurninTowards Data ScienceLogistic Regression and the Missing PriorHow to reduce the bias of logistic regression using Jeffreys PriorMar 10, 20221Mar 10, 20221
Ryan BurninTowards Data ScienceHow to Build a Bayesian Ridge Regression Model with Full Hyperparameter IntegrationHow do we handle the hyperparameter that controls regularization strength?Feb 23, 20221Feb 23, 20221
Ryan BurninITNEXTWhy Standard C++ Math Functions Are SlowPerformance has always been a high priority for C++, yet there are many examples both in the language and the standard library where…Dec 27, 2020Dec 27, 2020
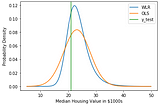
Ryan BurninTowards Data ScienceHow to Build a Warped Linear Regression ModelWe use the module peak-engines to fit monotonic transformations to dataJun 11, 2020Jun 11, 2020
Ryan BurninTowards Data ScienceWhat to Do When Your Model Has a Non-Normal Error DistributionHow to use warping to fit arbitrary error distributionsMar 13, 2020Mar 13, 2020
Ryan BurninTowards Data ScienceWhat Form of Cross-Validation Should You Use?Optimize the right proxy for out-of-sample prediction errorDec 20, 2019Dec 20, 2019
Ryan BurninTowards Data ScienceHow to Do Ridge Regression BetterUse an optimizer to find the best performing regularization matrixDec 17, 2019Dec 17, 2019